HBase 基本概念
作者: 康凯森
日期: 2016-04-08
分类: HBase
- HBase是什么
- HBase VS HDFS
- HBase VS RDBMS
- Hbase 特性
- Hbase架构
- HBase数据模型
- Hbase物理模型
- HBase 一致性模型
- HBase 容错性
- HBase支持的操作
- Write-Ahead-Log (WAL)
- HBase编程
- HBase Schema 设计
- 高级特性
- Hbase 核心概念
- Region 定位
- META 表
注:以下图片均来自互联网
HBase是什么
HBase构建在 HDFS 之上的分布式列式键值存储系统。 HBase内部管理的文件全部存储在HDFS中。

HBase VS HDFS
HDFS适合批处理场景
- 不支持数据随机查找
- 不适合增量数据处理
- 不支持数据更新
HBase VS RDBMS

范式化和反范式化 事务(单行:多行ACID) 索引(RowKey: 健全索引)
RDBMS的优点
- SQL
- 索引
- 事务
- 轻量
- 久经考验
RDBMS的缺陷
- 高并发读写的瓶颈
- 可扩展性的限制
- 事务一致性的负面影响
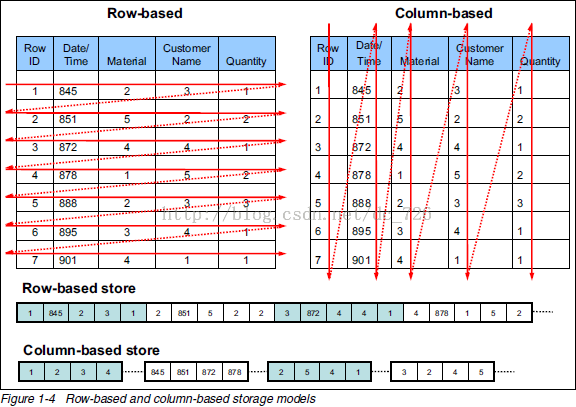
列式存储
列式存储概念出现的基础:对于特定的查询,不是所有值都是必需的。
- 以列为单位聚合数据,然后将列值顺序地存入磁盘
- 数据类型一致,数据特征相似,更利于压缩
- 大量降低系统I/O
Hbase 特性
- 容量巨大 单表可以有百亿行,百万列
- 面向列
- 稀疏性 空值不占用存储空间
- 扩展性 由HDFS决定。 热扩展
- 高可靠性
- WAL和Replication机制
- HDFS
- ZooKeeper
- 高性能
- LSM数据结构
- Rowkey有序排列
- 无模式
- 数据多版本
- 数据类型单一
- TTL
Hbase架构

Client
- 包含访问 HBase 的接口,并维护 cache 来加快对 HBase 的访问
- 通过RPC机制和Master,Region Server通信
Zookeeper
- 保证任何时候,集群中只有一个 master
- 存贮所有 Region 的寻址入口
- 实时监控 Region server 的上线和下线信息。并实时通知给 Master
- 存储 HBase 元数据信息
- HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
Master
- 为 Region server 分配 region
- 负责 Region server 的负载均衡
- 发现挂掉的 Region server 并重新分配其上的 region
- 负责表的建立,删除等操作
(由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。 因此master下线短时间内对整个hbase集群没有影响。)
Region Server
- Region server 维护 region ,处理对这些 region 的 IO 请求
- Region server 负责切分在运行过程中变得过大的 region
- Region Server 提供了行锁
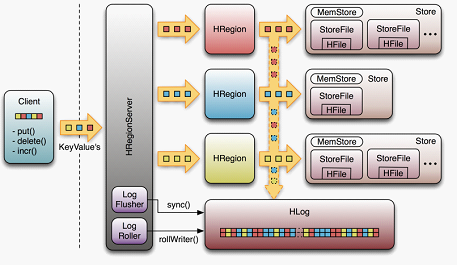
HRegionServer:HRegion:HStore = Column Family HStore:
- MemStore:用户数据首先写入MemStore。 (flush操作)
- StoreFile:Hfile (compact操作 split操作) Hbase 只有增加数据,所有更新和删除都是在 compact 过程中进行的。 用户写操作只要写入内存就可以立即返回,保证I/O高性能。
这台rs上的所有region共享相同的HLog files。 知道到目前为止,哪些数据已经被持久化了。
每个 update(或者说edit)都会 被写到 log ,当通知客户端成功后, rs 把数据再加载到内存中。
HBase数据模型
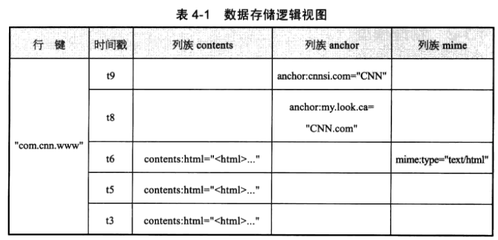
Row Key
行键,Table的主键,Table中的记录按照Row Key排序。类型为Byte array
- 不宜过长
- 分布均匀
Column Family
列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成
Column
列 格式为:familyName:columnName。 列名称是编码在cell中的。 不同的cell可以拥有不同的列。
Version Number
版本号。默认值是系统时间戳。类型为long
Value (Cell)
具体的值。类型为Byte array
Hbase物理模型
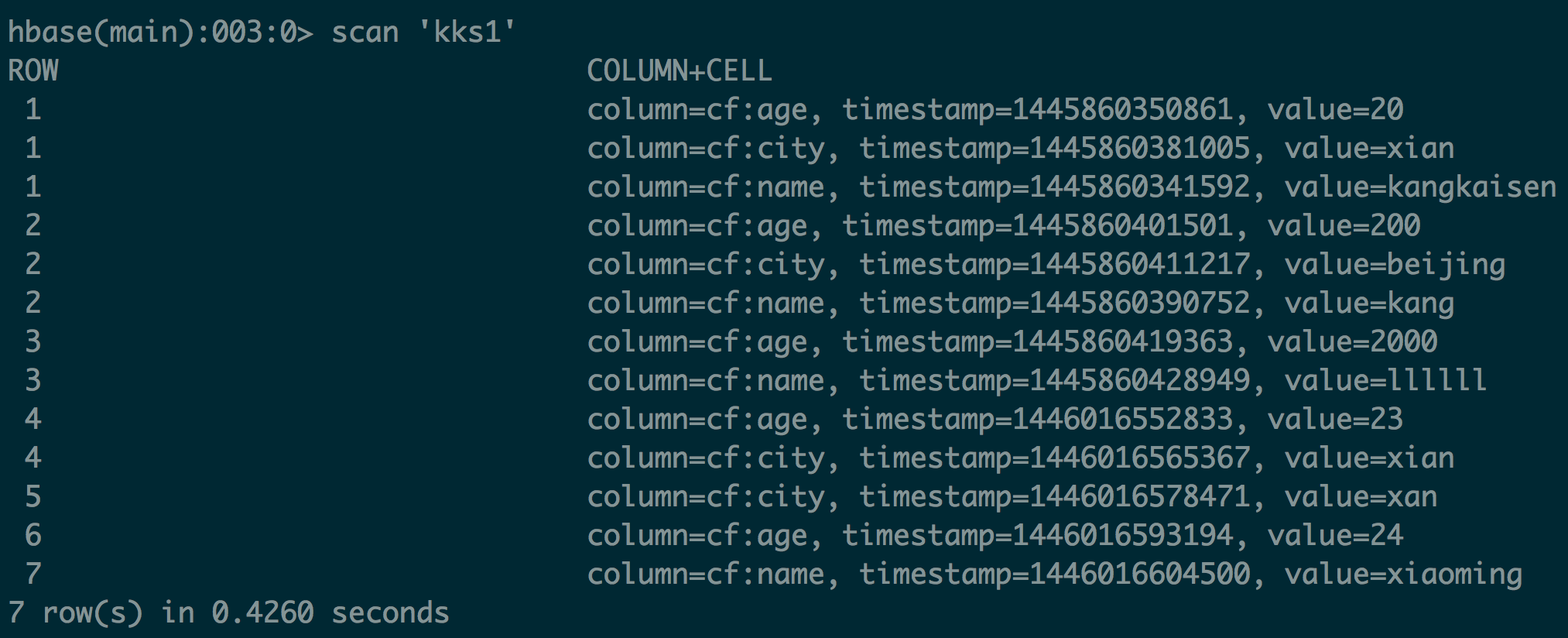
KeyValue格式
{HBASE_HMOE}/bin/hbase hfile -p -f /hbase/data/default/kks1/68639b7c80a31bf91448d26bb7af17b7/cf/74e43a51ebd14007870ac58658330aeb
K: 1/cf:age/1445860350861/Put/vlen=2/mvcc=0 V: 20
K: 1/cf:city/1445860381005/Put/vlen=4/mvcc=0 V: xian
K: 1/cf:name/1445860341592/Put/vlen=10/mvcc=0 V: kangkaisen
K: 2/cf:age/1445860401501/Put/vlen=3/mvcc=0 V: 200
K: 2/cf:city/1445860411217/Put/vlen=7/mvcc=0 V: beijing
K: 2/cf:name/1445860390752/Put/vlen=4/mvcc=0 V: kang
K: 3/cf:age/1445860419363/Put/vlen=4/mvcc=0 V: 2000
K: 3/cf:name/1445860428949/Put/vlen=6/mvcc=0 V: llllll
K: 4/cf:age/1446016552833/Put/vlen=2/mvcc=0 V: 23
K: 4/cf:city/1446016565367/Put/vlen=4/mvcc=0 V: xian
K: 5/cf:city/1446016578471/Put/vlen=3/mvcc=0 V: xan
K: 6/cf:age/1446016593194/Put/vlen=2/mvcc=0 V: 24
K: 7/cf:name/1446016604500/Put/vlen=8/mvcc=0 V: xiaoming

HFile格式
{HBASE_HOME}/bin/hbase hfile -m -f /hbase/data/default/kks1/68639b7c80a31bf91448d26bb7af17b7/cf/74e43a51ebd14007870ac58658330aeb
Block index size as per heapsize: 392
reader=/hbase/data/default/kks1/68639b7c80a31bf91448d26bb7af17b7/cf/74e43a51ebd14007870ac58658330aeb,
compression=none,
cacheConf=CacheConfig:disabled,
firstKey=1/cf:age/1445860350861/Put,
lastKey=3/cf:name/1445860428949/Put,
avgKeyLen=18,
avgValueLen=5,
entries=8,
length=1211
Trailer:
fileinfoOffset=448,
loadOnOpenDataOffset=343,
dataIndexCount=1,
metaIndexCount=0,
totalUncomressedBytes=1123,
entryCount=8,
compressionCodec=NONE,
uncompressedDataIndexSize=31,
numDataIndexLevels=1,
firstDataBlockOffset=0,
lastDataBlockOffset=0,
comparatorClassName=org.apache.hadoop.hbase.KeyValue$KeyComparator,
majorVersion=2,
minorVersion=3
Fileinfo:
BLOOM_FILTER_TYPE = ROW
DELETE_FAMILY_COUNT = \x00\x00\x00\x00\x00\x00\x00\x00
EARLIEST_PUT_TS = \x00\x00\x01P\xA3\xFD\xF7X
KEY_VALUE_VERSION = \x00\x00\x00\x01
LAST_BLOOM_KEY = 3
MAJOR_COMPACTION_KEY = \x00
MAX_MEMSTORE_TS_KEY = \x00\x00\x00\x00\x00\x00\x00\x00
MAX_SEQ_ID_KEY = 10
TIMERANGE = 1445860341592....1445860428949
hfile.AVG_KEY_LEN = 18
hfile.AVG_VALUE_LEN = 5
hfile.LASTKEY = \x00\x013\x02cfname\x00\x00\x01P\xA3\xFFL\x95\x04
Mid-key: \x00\x011\x02cfage\x00\x00\x01P\xA3\xFE\x1B\x8D\x04
Bloom filter:
BloomSize: 8
No of Keys in bloom: 3
Max Keys for bloom: 6
Percentage filled: 50%
Number of chunks: 1
Comparator: RawBytesComparator
Delete Family Bloom filter:
Not present
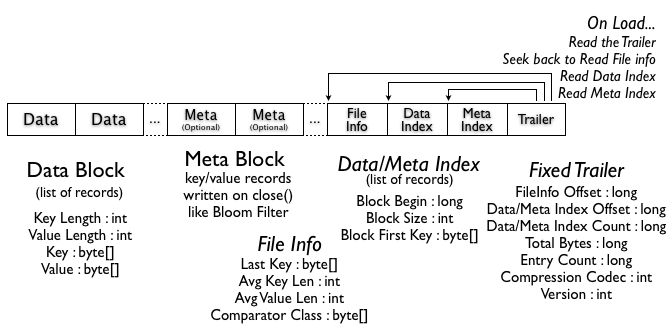
物理上,表是按列族分开存储的,每个 Column Family 存储在 HDFS 上的一个单独文件中(因此最好将具有共同I/O特性的列放在一个 Column Family中)
HBase 为每个值维护了多级索引,即: RowKey, column family, column name, timestamp
Table 中的所有行都按照 RowKey 的字典序排列
Table 在行的方向上分割为多个Region

Region 按大小分割的,每个表开始只有一个 region ,随着数据增多, region 不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region
Region 是 HBase 中分布式存储和负载均衡的最小单元,Region 实际上是rowkey 排序后的按规则分割的连续的存储空间,不同Region分布到不同RegionServer上
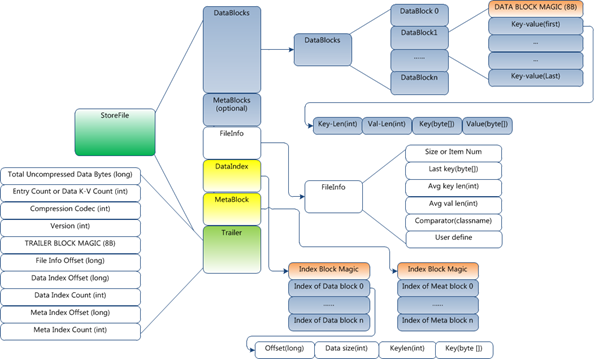
Region 虽然是分布式存储的最小单元,但并不是存储的最小单元。
- Region 由一个或者多个 Store 组成,每个 Store 保存一个columns family
- 每个 Strore 又由一个 MemStore 和 0 至多个 StoreFile 组成
- MemStore 存储在内存中, StoreFile 存储在 HDFS 上。
HBase 一致性模型
HBase 是强一致性的。
- WAL
- 行操作的存取操作是原子的。
HBase 容错性
Master容错
- Zookeeper重新选择一个新的Master
- 无Master过程中,数据读取仍照常进行
- 无master过程中,region切分、负载均衡等无法进行
RegionServer容错
- 定时向Zookeeper汇报心跳
- Master将该RegionServer上的Region重新分配到其他RegionServer上
- WAL由Master进行分割并派送给新的RegionServer
Zookeeper容错
- Zookeeper是一个可靠地服务
- 一般配置3或5个Zookeeper实例
HBase支持的操作
- 所有操作均基于Rowkey
- 支持CRUD 和SCAN
- 没有内置join操作,可以使用MapReduce解决。
Write-Ahead-Log (WAL)
- 用户每次写入 MemStore 的同时,也会写一份数据到HLOG文件中。只有当写入成功后才通知客户端该操作成功。
- 每个RegionServer只有一个HLOG文件
- HLOG文件定期会滚动更新,并删除旧的文件(已持久化到StoreFile中的数据)
- 日志文件回放 集群启动时或服务失效时
- 日志拆分 ##Hbase应用
何时使用Hbase
- 键值对的数据存储
- 有序的数据存储
- 存储大量数据(PB级数据)且能保证良好的访问性能
- 高并发写入,瞬间写入量很大
- 业务场景简单(无交叉列,交叉表,事务, 连接等)
- 可以优雅的数据扩展
Hbase 不适用场景
• 事务 • join、group by等关系查询不计算 • 不按rowkey查询数据 • 高并发随机读 • 低延迟随机读
Hbase应用场景
- 淘宝指数
- 淘宝交易历史记录查询系统
- FB消息系统(聊天系统,邮件系统) 一个较小的临时数据集,是经常变化的 一个不断增加的数据集,是很少被访问的
- 搜索引擎应用
- 增量数据存储 OpenTSDB FB Like按钮
- 内容推荐引擎系统:搜狐
- 用户模型服务:电商行业
HBase编程
- Native Java API
- HBase Shell
- Thrift Gateway (多语言编程)
- REST Gateway
- MapReduce
HBase Schema 设计
重点是RowKey设计
高级特性
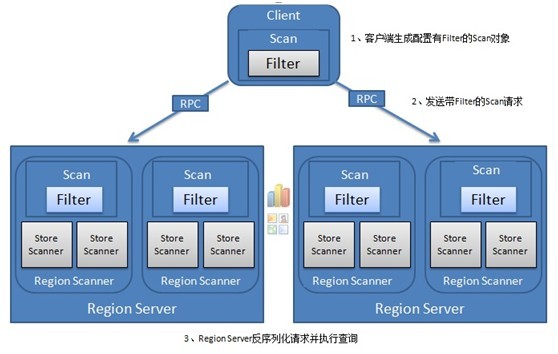
过滤器 Filter
Scan.setFilter 所有的过滤器都在服务端生效,叫做谓词下推。 数据仍然需要从硬盘读进RegionServer,过滤器在RegionServer里发挥作用 过滤器也可以自定义
计数器
如果没有计数器,用户需要针对一行加锁,读取一行的值,然后再加上特定的值,然后再写回并释放锁,尤其是当客户端进程崩溃之后,尚未释放的锁需要等待超时恢复,这样在一个高负载的系统中会引起灾难性后果。
计数器就是读取并修改(Read and modify),保证一次客户端操作的原子性。
将列作为计数器 通过Check-And-Save保证写操作原子性 便于给某些在线应用提供实时统计功能
协处理器
允许用户在region服务器上运行自己的代码,也就是允许用户执行region级操作。 用途: 辅助索引, 权限控制
- observer 类似触发器或者回调函数 在特定事件发生后执行
- endpoint 类似存储过程 通过RPC,调用regionserver端的计算过程
Hbase 核心概念
LSM 树
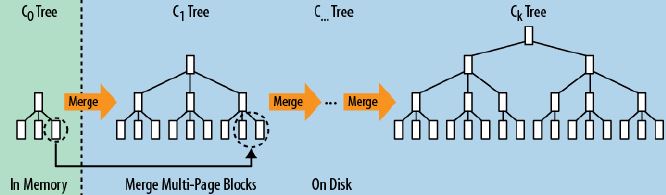
RDBMS 通常是寻道型的 LSM树 属于传输型的 LSM树 会使用日志文件
为长期具有很高记录更新频率的文件提供低成本的索引机制 LSM 树 最适合 索引插入 比 查询操作 更常见的操作 主题思想是划分不同等级的树 LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作顺序批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。(极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级)
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。
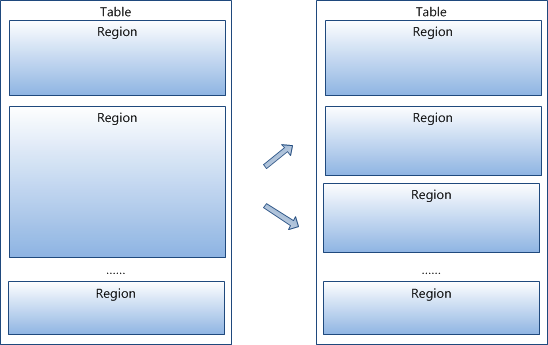
split
当store的store file集合中总文件长度太大时(超过配置的阈值),这个region会一分为二.
父 region 下线,新分裂的俩个子 region 会被Master 分配到相应的 RegionServer.
compaction
minor compaction 将部分小文件合并成大文件 majar compaction 合并所有文件为一个 操作的是此列族的全量数据,所以可以做物理删除。但是也由于是全量数据,执行起来耗费时间也会比价长
flush
用空的新memstore 获取更新数据,将满的旧memstore写入磁盘。
Region 定位
第一次读取: 步骤1:读取ZooKeeper中META表的位置。 步骤2:读取META表中用户表的位置。 步骤3:读取数据。
如果已经读取过一次,则root表和.META都会缓存到本地,直接去用户表的位置读取数据。
META 表
当我们从客户端读取,写入数据的时候,我们需要知道数据的 Rowkey是在哪个Region以及我们需要的Region是在哪个RegionServer上。 而这正是HBase Meta表所记录的信息。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
