HBase Schema 设计
作者: 康凯森
日期: 2016-04-09
分类: HBase
基本概念
每张表只有一个索引:rowkey 没有二级索引
行按照rowkey 排序:rowkey 按照字典序排序
行级别的操作都是原子的
例如:你要更新表中的俩行,可能出现一行更新成功,一行更新失败的情况。Schema 设计中应该避免跨行的原子性请求。
读写应该均匀分布到整个表
通常,应该把单个实体的所有信息保存在单行中
如果一个实体需要存储大量信息(数百MB),你可以考虑用多行来存储每个实体。或者你很少需要在一次请求中获取单个实体的全部信息,你也可以使用多行来存储每个实体。
相关的实体应该存储在邻近的行
这样可以使得读更加高效,也可以尽可能压缩数据
HBase表是稀疏的
空的列不会占据任何空间,所以,建立大量列通常是有意义的,尽管许多行的许多列都是空的。
确定 rowkey
为了获得 HBase 的最好性能,我们必须认真考虑 rowkey 的设计,因为HBase 最有效的查询就是 使用 rowkey 获取特定行,或者多行数据,其他类型的查询会触发全表扫描,效率比较低下。
首先要确定你想要如何使用你存储的数据,例如:
- 用户信息:你需要快速获取用户之间的连接信息吗?(例如:用户A是否关注了用户B)
- 用户产生内容:假如你需要向用户展示大量的用户产生信息的抽样,例如状态更新,你将如何决定哪些状态更新信息应该展示给指定用户?
- 时间序列数据:你需要频繁获取最新的N条记录,或者获取特定时间范围内的记录吗?如果你存储了多种项目的数据,你需要基于项目进行过滤吗?
通过提前明确你的需求,你可以确定你的 rowkey 和整体 schema 设计,提供足够灵活,有效的方式查询你的数据。
rowkey 的类型
这部分会描述最常见的 rowkey 使用类型以及何时使用哪种类型。
基本的经验:让你的 rowkey 尽可能短,长的 rowkey 会占据更多存储空间而且也会增加 HBase 的响应时间。
反转域名
如果你要存储的数据可表示为域名的形式,可以考虑反转域名作为 rowkey 。(例如:com.example.products)反转域名是很不错的方法,尤其是相邻域名相似度很大, 同时这种方法也便于更有效的压缩数据。
这种方法最适合你的数据分散在许多不同的反向域名中,如果你希望存储你的数据在少量的反向域名中,你应该重新设计 rwokey,否则,大量的写请求会发往集群的单个节点,形成热点。
字符串标识符
如果你要存储的数据可以被一个字符串简单的标识(例如: user IDs),你可以使用标识符作为 rowkey 或是 rowkey 的一部分。考虑使用 标识符的哈希而不是它本身,以便 标识符的长度永远可以预测。
时间戳
如果你经常需要基于时间读取数据,将时间戳作为 rowkey 的一部分是不错的方法。不推荐直接使用时间戳本身作为 rowkey,因为会造成热点问题,同样的原因,也不应该将时间戳作为 rowkey 的开始。
例如:你的应用可能需要记录性能相关的数据,例如每秒的CPU,内存使用情况。对于这种情况,你可以将数据类型的标识符和时间戳组合为 rowkey.(例如:cpu#1425330757685)
如果你需要经常获取最新的记录,你可以使用相反时间戳作为 rwokey,用你的编程语言中长整形的最大值(in Java, java.lang.Long.MAX_VALUE)减去现在的时间戳。有了相反的时间戳,记录将会按照从新到旧的顺序排列。
单行中存储多个值
因为 HBase 仅仅支持通过 rwokey 查询,所以通常可以将多个值包含在你的 rowkey 中。这样做查询十分高效。当你的 rowkey 中包含多个值时,清楚的知道你将如何使用你的数据是十分重要的。
例如:假如你的应用允许用户发布消息,可以在消息中@另一个用户。你需要一种有效的方法去列出一个用户在消息中@的所有用户,实现这个需求的一种方法是:用被@用户名的哈希+主动@用户名的哈希作为 rowkey.同时每一行也会存储原始的用户名和消息内容,如图:
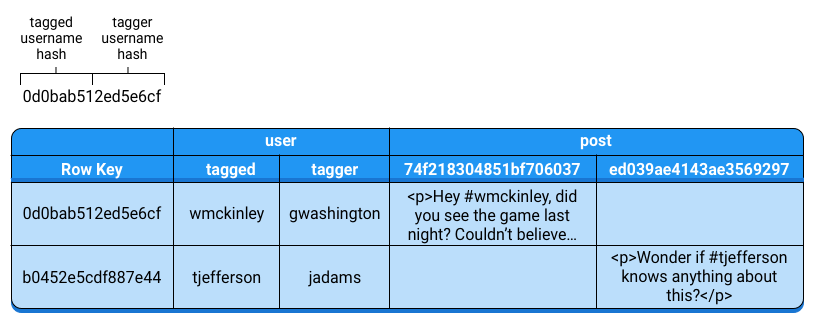
为了找到哪个用户被@,或者@了某个用户的所有消息。你可以简单获取rowkey 以被@用户开始的行即可。
像这个例子,建立 rowkey 可以让你返回定义良好的行是十分重要的,否则你需要扫描整个表格,这比返回特定行慢许多。例如:假设你需要存储每秒多种数据类型的性能相关的数据,如果你的 rowkey 是 时间戳+数据类型(1425330757685#cpu),这样你查询特定类型的数据效率会十分低下,你将仅仅可以根据时间戳查询。
避免这样的rowkey
一些 rowkey 会使查询困难,性能低下,这部分会介绍一些你在 HBase 中应该避免使用的 rowkey:
域名
避免使用标准的,未反转的域名作为 rowkey,用标准的域名作为 rowkey 会使获取部分域名的行十分低效,(例如:myapp.example.com的所有相关行)。除此之外,使用标准域名会使得相似的数据没有聚集在一起,这样压缩也会十分低效。
连续的数字
假设你的应用给每一个用户分配一个数字ID。你可能会用用户的数字ID作为表的 rowkey .然而,新的用户十分有可能是活跃用户,这将可能导致热点问题。
安全的方法是反转用户数字ID,这样可以将请求均匀分散到表的各个节点。
频繁更新的标识符
避免使用单个 rowkey 标识一个更新频繁的值,例如:如果你存储内存使用数据每秒一次,不要使用 “memusage” 的单个 rowkey并且重复更新数据。这将会使得存储频繁更新数据的表超过负载,也可能会使得行的大小超过限制,因为之前旧的数据也会暂时占据空间。
相反,应该每一行存储一个值。使用包含元数据类型,限定符,时间戳的rowkey.例如:你需要监控一段时间 内存的使用情况,你可以这样设计 rowkey: memusage#1423523569918.这种方法在 HBase中是有效的,因为创建新行不会比创建新版本或者列花费更多时间。除此之外,这种方法允许你通过设置合适的开始,结束键值快速读取特定时间范围的数据。
对于频繁更新的数值,例如每分钟改变几百次的计数器,最简单的方法是将数据先保存在内存中,再周期性的批量写入HBase 。
列
因为HBase 是稀疏的,所以你可以在每行中创建许多列,只要你需要。空的列是不占据空间的。所以,可以把列名当做数据看待,例如:如果你的表存储用户的文章,你可以对每篇文章用唯一标识符作为列名。
和 roekey 和列族一样,列名也尽可能短,因为它们在每次数据请求中都会被传输。
高表还是宽表
目前你看到的例子都是宽表,每行有许多列。通常当你用列名作为数据时,你可以获得一个宽表。有时候也会用高表,高表有大量的行但是每行只有极少的列。
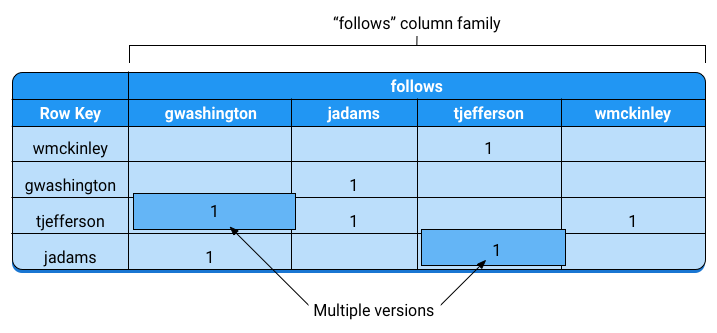
这是一个宽表,存储每个人的粉丝,对于每个用户,每行都是他的粉丝。
假如你不需要完整的用户关注列表,你仅仅想用HBase回答:用户A是否关注用户B。
一个有效的方法是使用高表,每行是对应一对用户和他的粉丝。rowkey由被关注者和关注者的哈希组成。 所以,你通过查询一个rwokey就可以检查用户A是否关注用户B,如果存在那行,就说明用户A关注用户B,否则,用户A就没有关注B。 下面是上图的高图版本:

如果你想知道用户jadams 是否关注 tjefferson,你可以简单搜索jadams(df887e44)和tjefferson(b0452e5c)哈希值组成的 rowkey行 df887e44b0452e5c 存在, 所以 我们知道 jadams 关注了 tjefferson.
注意我们存储了被关注者的用户名,因为没有这个信息,找到哈希对应的用户名是比较耗时的。
《OLAP 性能优化指南》欢迎 Star&共建
欢迎关注微信公众号
