Data-Parallel Actors:千行代码构建高性能 OLAP 数据库
作者: 康凯森
日期: 2022-11-05
分类: OLAP
- What is Data-Parallel Actors
- Why need Data-Parallel Actors
- How Data-Parallel Actors
- 相比 Druid, MongoDB, ClickHouse 等数据库的优点
- 限制
- 难点
- 思考
- 参考资料
What is Data-Parallel Actors
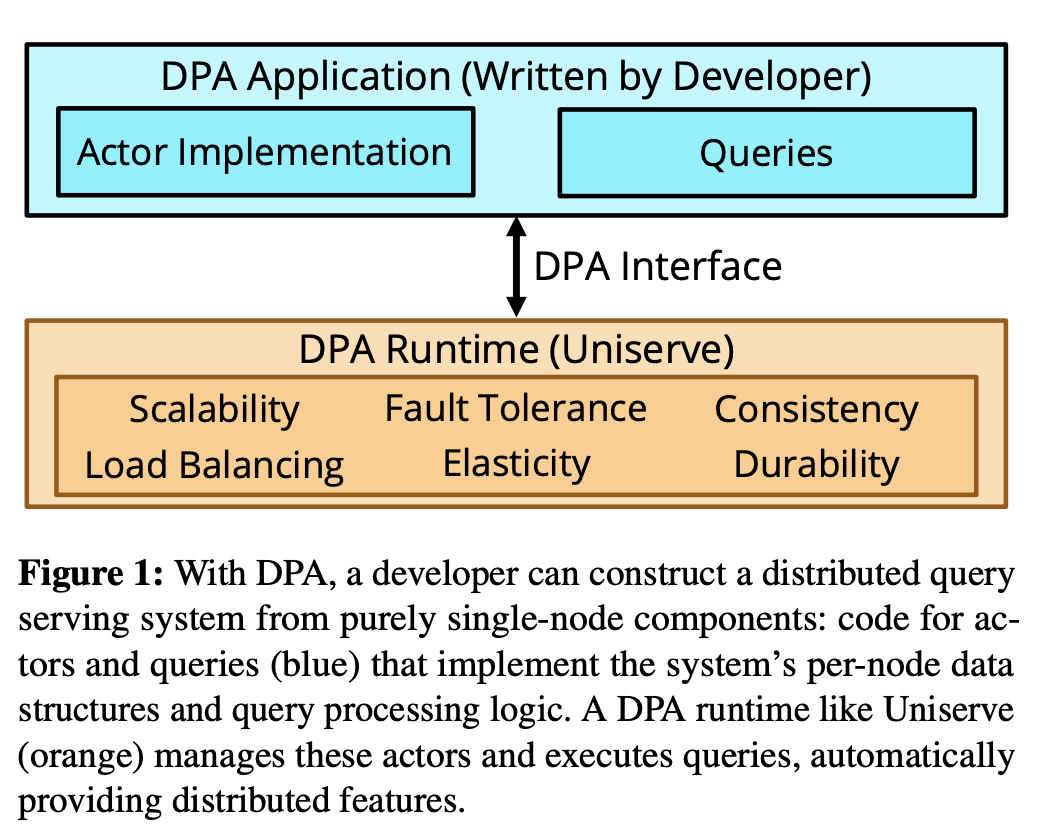
如上图,DPA 是一个 high-level 的编程模型:对分布式查询的相关功能进行了统一和抽象:数据复制,更新一致性,容错,查询负载均衡,弹性,持久化等。
有了 DPA,开发者只实现单机的数据结构和算子,就可以获得一个可靠的,高性能的分布式分析型数据库。开发者使用 DPA 只需要专注自己的独特和核心的逻辑。
论文中通过 Druid, Solr, and MongoDB 3 个系统论证了 DPA 的普适性和实际效果,利用 DPA 实现前面 3 个系统每个都不超过 1 千行代码。 并且在标准测试集的性能,不比之前的系统差,而且在有数据倾斜的场景,还有 3 倍的性能提升。
开发者需要通过查询优化器将用户的请求转为 DPA 的并行算子。
Why need Data-Parallel Actors
分布式功能每个系统都大同小异,都需要耗费大量的人力,不应该也不需要重复实现。
当前的分布式系统(Erlang,Ray,Spark 等)不能满足分析型数据库的需求:数据并行的低延迟查询和高频的批量数据更新。
How Data-Parallel Actors
Actors 和数据模型的映射
DPA 将一个数据库视为 stateful actors 的集合,每个 Actor 封装了一部分数据,同时负责这部分数据的状态和计算。
- 在 Solr 里,一个 Actor 封装了 Solr 的 inverted index
- 在 Druid 里,一个 Actor 封装了 Druid 的 segment,一组 Actor 组成 Druid 的 data source
- 在 MongoDB,一组 Actor 封装了 MongoDB 的 collections
DPA 不关心每个系统的 actor 具体如何实现,只需要实现几个核心接口: create, destroy, serialize, and deserialize。DPA 会依靠这些接口实现分布式的相关功能,来管理 Actor 和执行查询。
DPA 提供的接口

如上图所示,DPA 提供的接口主要分为 4 类:
- Actor 状态管理相关的接口,DPA 依赖这些接口去管理 Actor
- 更新相关的接口,DPA 依赖这些接口实现 Actor 数据的更新,DPA 支持不同级别的一致性
- Operator 并行化的接口,DPA 依赖这些接口实现 Actor 的并行查询
- 具体的 Operator 算子, DPA 依赖这些接口 实现 Actor 的具体查询逻辑。 不同数据库的算子基本都可以通过这几个抽象算子实现。每个 Operator 不应该修改 Actor 的 state,而是物化输入,让后一个 Operator 读取。其中 Scatter and Gather 算子可以实现 Actor 之间进行数据传输,模拟分布式数据库中的 broadcast and shuffle
整体架构
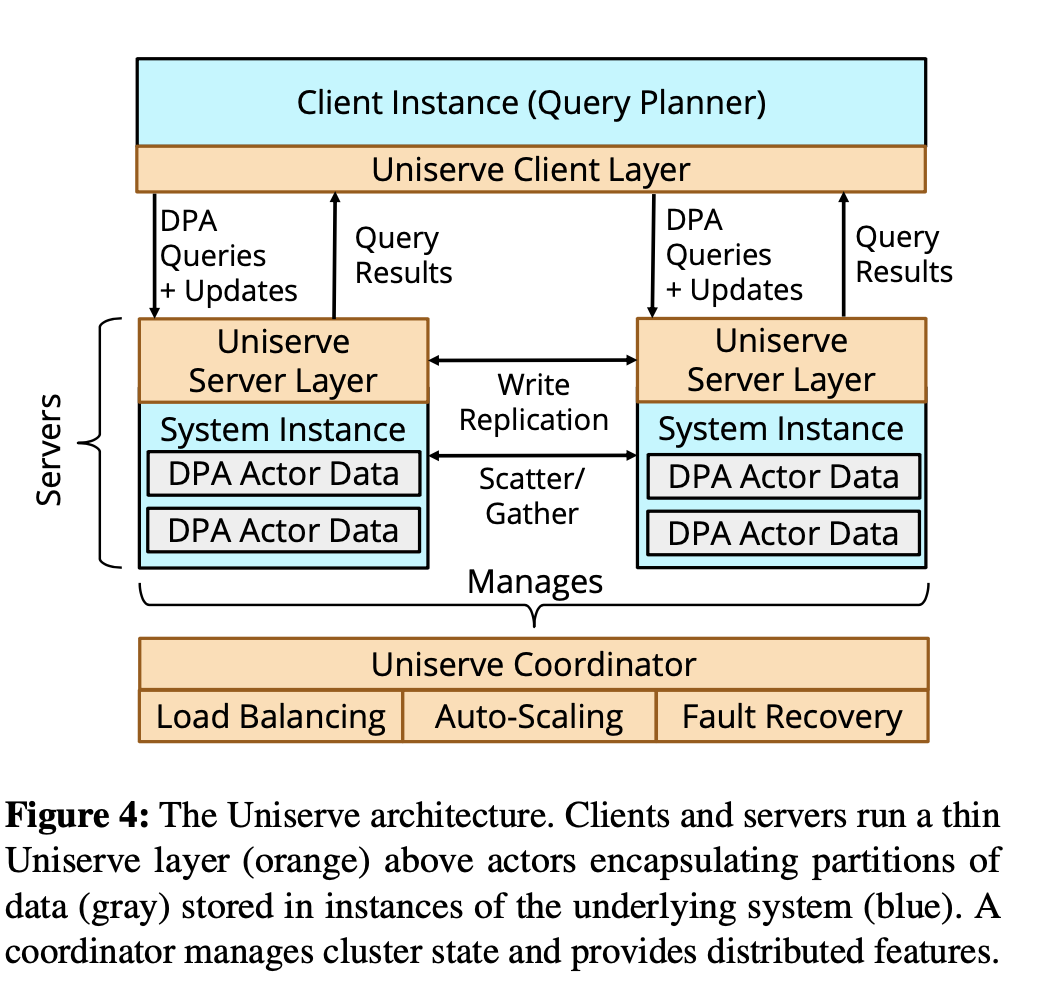
如果所示,Uniserve 是 DPA 的一个具体实现。有 3 个 角色:
- Uniserve Client:负责发送查询和更新请求,在查询部分,会承担查询优化器的职责,将 将用户的请求转为 DPA 的算子。
- Uniserve Server: 负责服务 每个 Actor 的查询和更新请求。
- Uniserve Coordinator: 负责 实现 DPA 的分布式逻辑:数据复制,更新一致性,容错,查询负载均衡,弹性,持久化等。
- DPA 会将数据存储在 S3 等分布式存储上。
相比 Druid, MongoDB, ClickHouse 等数据库的优点
主要是两点:
根据机器负载 balance 查询请求
默认的策略比较简单:就是将负载最高的 actor 从负载最高的 server 上迁移到 负载最低的 server 上。
优点是调度策略是可扩展的,允许开发者自定义自己的策略
Elasticity and Auto-Scaling
具备弹性伸缩的能力,同时策略也是可扩展的,弹性伸缩的策略我们一方面要参考集群的 CPU,内存,网络,磁盘等资源的使用率,也要参考集群的查询请求负载。
我理解主要也是因为这两点,DPA 可以做到在数据倾斜场景下有 3 倍的性能提升。
限制
- DPA 的查询模型对数据并行的查询最合适
- DPA 不适合 TP 场景有事务要求的高频点查
难点
1 如何支持多种查询和数据模型:
- 关系型
- 搜索
- 时序
- 文档
- 向量数据库
2 如何对查询调度,副本均衡,弹性伸缩等分布式核心功能进行正确的抽象,允许不同的数据库,不同的业务需求都可以在定义好的接口下实现。
思考
开源界必然出现类似 DPA 的系统
凡是重复的,有价值的功能和模块,在开源界,肯定会有专门的系统来做
开源数据库会越来越模块化
开源的数据库模块越来越多:DPA,Apache Calcite,Apache Arrow, Velox, gRPC 等,而且被工业界采纳的也越来越多
打造一个高性能的数据库原型会越来越简单
因为开源数据会越来越模块化,所以我们从零打造一个高性能的数据库原型就会越来越简单,我在下一篇文档会详细解释这一点
参考资料
https://cs.stanford.edu/~matei/papers/2022/nsdi_uniserve.pdf
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
