Druid Storage 原理
作者: 康凯森
日期: 2017-11-02
分类: OLAP
本文主要介绍Druid Storage的原理,包括Druid Storage的存储格式,不同列的Serde方式,以及Druid Storage的底层查询原理。在介绍Druid Storage之前,我先对Druid的整体架构和核心概念做下简单介绍。
What is Druid
Druid是一个开源的实时OLAP系统,可以对超大规模数据提供亚秒级查询,其具有以下特点:
- 列式存储
- 倒排索引 (基于Bitmap实现)
- 分布式的Shared-Nothing架构 (高可用,易扩展是Druid的设计目标)
- 实时摄入 (数据被Druid实时摄入后便可以立即查询)
Why Druid
为了能够提取利用大数据的商业价值,我们必然需要对数据进行分析,尤其是多维分析, 但是在几年前,整个业界并没有一款很好的OLAP工具,各种多维分析的方式如下图所示:
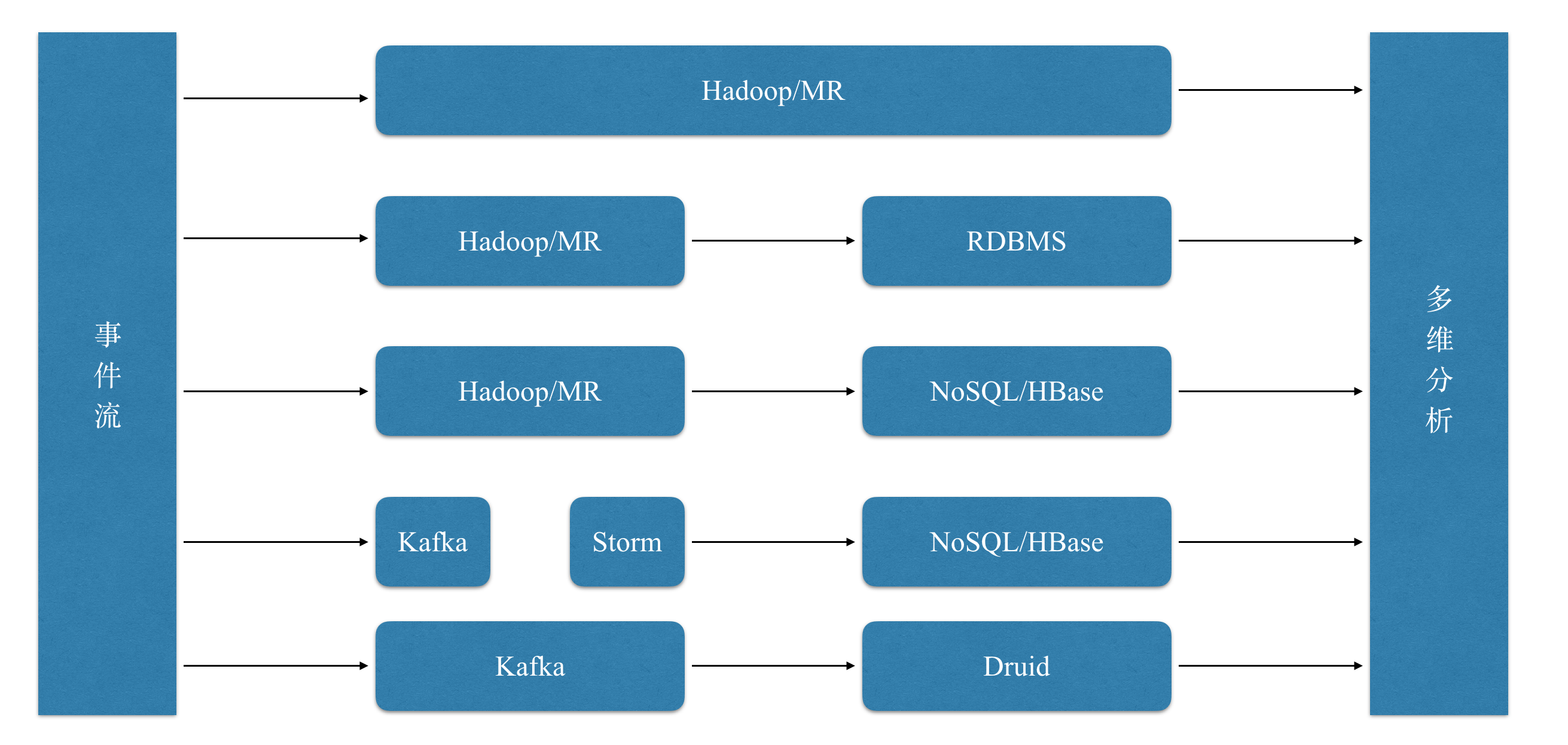
其中直接基于Hive,MR,Spark的方式查询速度一般十分慢,并发低;而传统的关系型数据库无法支撑大规模数据;以HBase为代表的NoSQL数据库也无法提供高效的过滤,聚合能力。正因为现有工具有着各种各样的痛点,Druid应运而生,以下几点自然是其设计目标:
- 快速查询
- 可以支撑大规模数据集
- 高效的过滤和聚合
- 实时摄入
Druid 架构
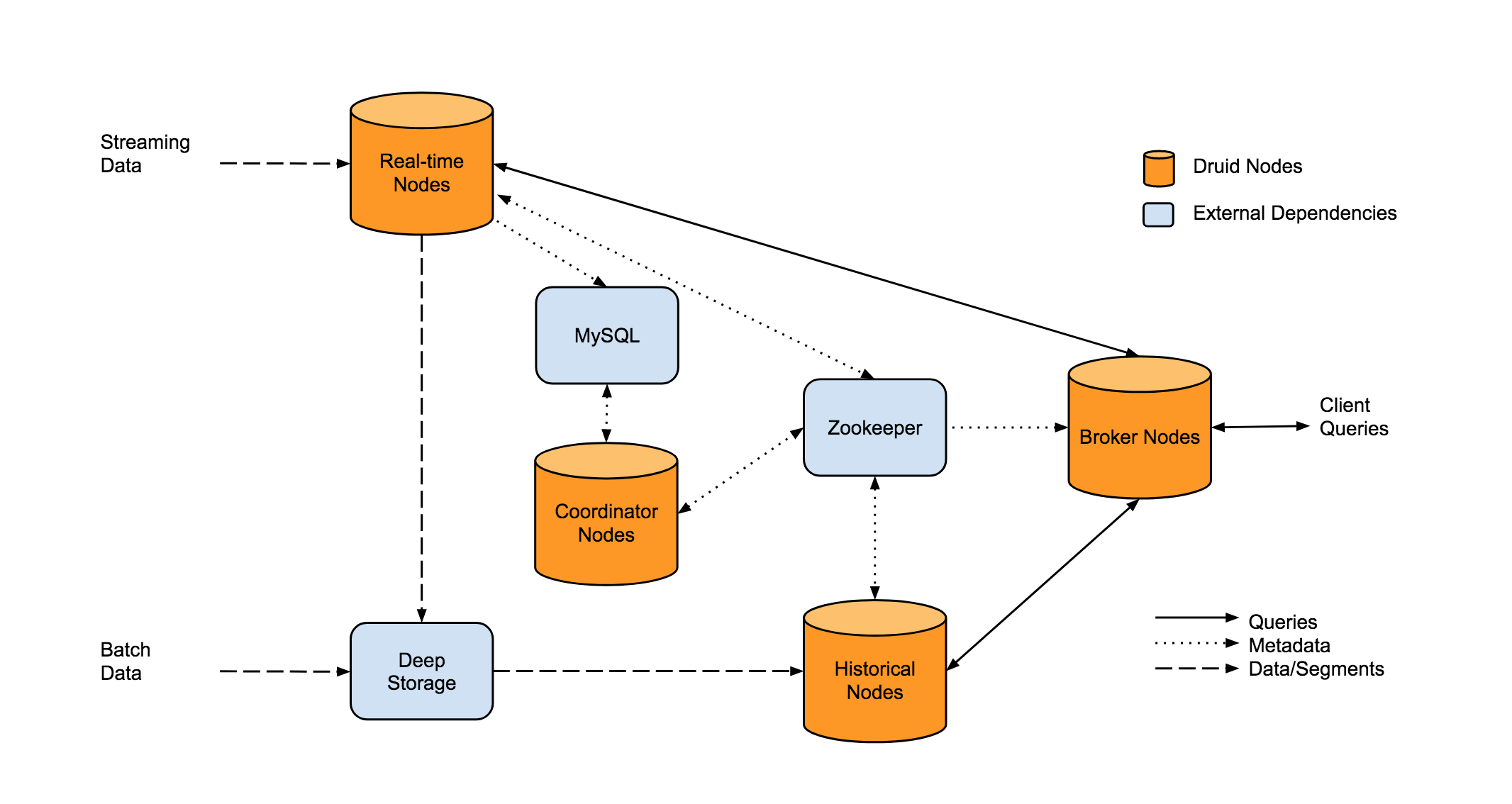
Druid的整体架构如上图所示,其中主要有3条路线:
实时摄入的过程: 实时数据会首先按行摄入Real-time Nodes,Real-time Nodes会先将每行的数据加入到1个map中,等达到一定的行数或者大小限制时,Real-time Nodes 就会将内存中的map 持久化到磁盘中,Real-time Nodes 会按照segmentGranularity将一定时间段内的小文件merge为一个大文件,生成Segment,然后将Segment上传到Deep Storage(HDFS,S3)中,Coordinator知道有Segment生成后,会通知相应的Historical Node下载对应的Segment,并负责该Segment的查询。
离线摄入的过程: 离线摄入的过程比较简单,就是直接通过MR job 生成Segment,剩下的逻辑和实时摄入相同:
用户查询过程: 用户的查询都是直接发送到Broker Node,Broker Node会将查询分发到Real-time节点和Historical节点,然后将结果合并后返回给用户。
各节点的主要职责如下:
Historical Nodes
Historical 节点是整个Druid集群的骨干,主要负责加载不可变的segment,并负责Segment的查询(注意,Segment必须加载到Historical 的内存中才可以提供查询)。Historical 节点是无状态的,所以可以轻易的横向扩展和快速恢复。Historical 节点load和un-load segment是依赖ZK的,但是即使ZK挂掉,Historical依然可以对已经加载的Segment提供查询,只是不能再load 新segment,drop旧segment。
Broker Nodes
Broker 节点是Druid查询的入口,主要负责查询的分发和Merge。 之外,Broker还会对不可变的Segment的查询结果进行LRU缓存。
Coordinator Nodes
Coordinator 节点主要负责Segment的管理。Coordinator 节点会通知Historical节点加载新Segment,删除旧Segment,复制Segment,以及Segment间的复杂均衡。
Coordinator 节点依赖ZK确定Historical的存活和集群Segment的分布。
Real-time Node
实时节点主要负责数据的实时摄入,实时数据的查询,将实时数据转为Segment,将Segment Hand off 给Historical 节点。
Zookeeper
Druid依赖ZK实现服务发现,数据拓扑的感知,以及Coordinator的选主。
Metadata Storage
Metadata storage(Mysql) 主要用来存储 Segment和配置的元数据。当有新Segment生成时,就会将Segment的元信息写入metadata store, Coordinator 节点会监控Metadata store 从而知道何时load新Segment,何时drop旧Segment。注意,查询时不会涉及Metadata store。
Deep Storage
Deep storage (S3 and HDFS)是作为Segment的永久备份,查询时同样不会涉及Deep storage。
Column

Druid中的列主要分为3类:时间列,维度列,指标列。Druid在数据摄入和查询时都依赖时间列,这也是合理的,因为多维分析一般都带有时间维度。维度和指标是OLAP系统中常见的概念,维度主要是事件的属性,在查询时一般用来filtering 和 group by,指标是用来聚合和计算的,一般是数值类型,像count,sum,min,max等。
Druid中的维度列支持String,Long,Float,不过只有String类型支持倒排索引;指标列支持Long,Float,Complex, 其中Complex指标包含HyperUnique,Cardinality,Histogram,Sketch等复杂指标。强类型的好处是可以更好的对每1列进行编码和压缩, 也可以保证数据索引的高效性和查询性能。
Segment
前面提到过,Druid中会按时间段生成不可变的带倒排索引的列式文件,这个文件就称之为Segment,Segment是Druid中数据存储、复制、均衡、以及计算的基本单元, Segment由dataSource_beginTime_endTime_version_shardNumber唯一标识,1个segment一般包含5–10 million行记录,大小一般在300~700mb。
Segment的存储格式
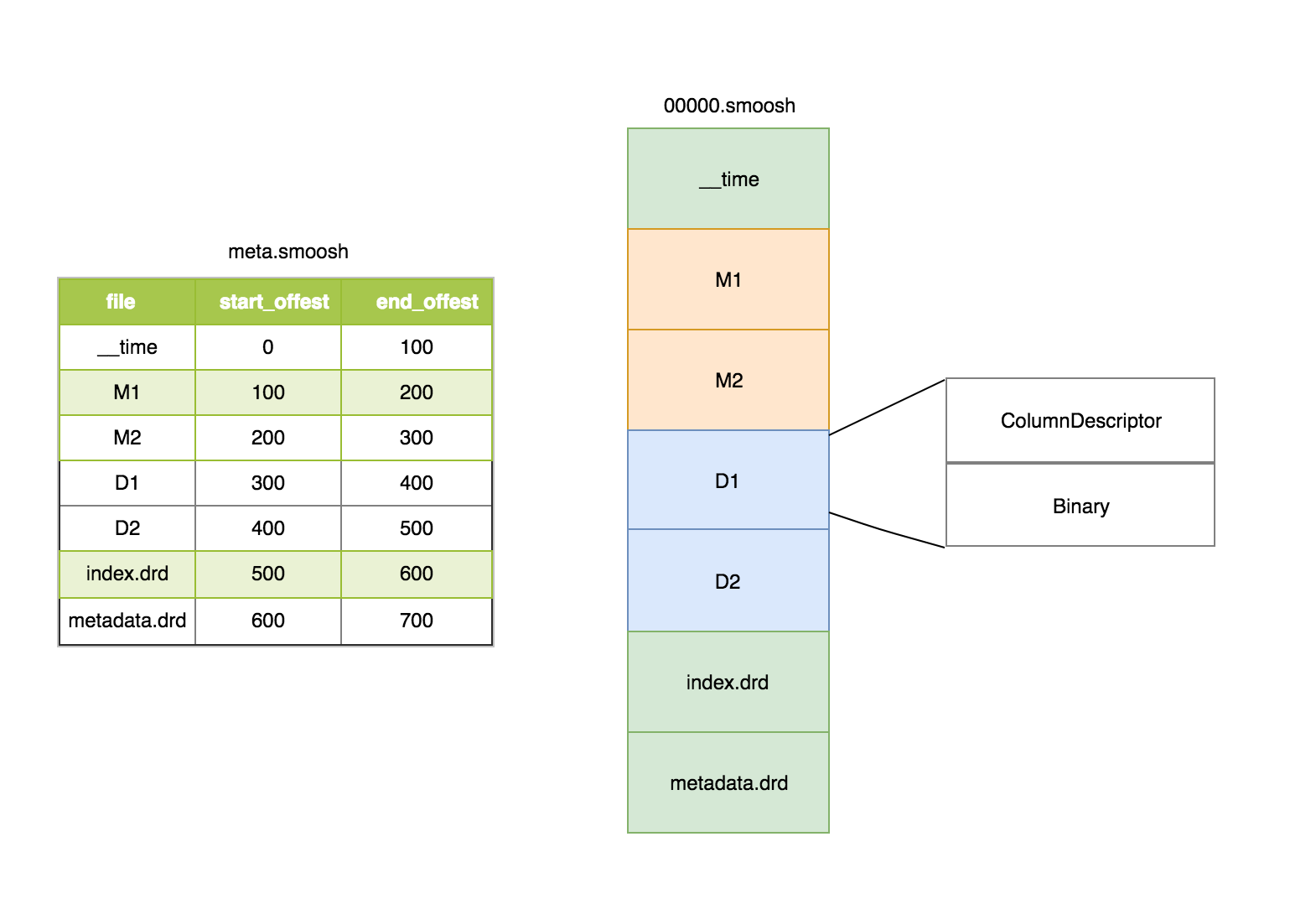 Druid segment的存储格式如上图所示,包含3部分:
Druid segment的存储格式如上图所示,包含3部分:
- version文件
- meta 文件
- 数据文件
其中meta文件主要包含每1列的文件名和文件的偏移量。(注,druid为了减少文件描述符,将1个segment的所有列都合并到1个大的smoosh中,由于druid访问segment文件的时候采用MMap的方式,所以单个smoosh文件的大小不能超过2G,如果超过2G,就会写到下一个smoosh文件)。
在smoosh文件中,数据是按列存储中,包含时间列,维度列和指标列,其中每1列会包含2部分:ColumnDescriptor和binary数据。其中ColumnDescriptor主要保存每1列的数据类型和Serde的方式。
smoosh文件中还有index.drd文件和metadata.drd文件,其中index.drd主要包含该segment有哪些列,哪些维度,该Segment的时间范围以及使用哪种bitmap;metadata.drd主要包含是否需要聚合,指标的聚合函数,查询粒度,时间戳字段的配置等。
指标列的存储格式
我们先来看指标列的存储格式:

指标列的存储格式如上图所示:
- version
- value个数
- 每个block的value的个数(druid对Long和Float类型会按block进行压缩,block的大小是64K)
- 压缩类型 (druid目前主要有LZ4和LZF俩种压缩算法)
- 编码类型 (druid对Long类型支持差分编码和Table编码两种方式,Table编码就是将long值映射到int,当指标列的基数小于256时,druid会选择Table编码,否则会选择差分编码)
- 编码的header (以差分编码为例,header中会记录版本号,base value,每个value用几个bit表示)
- 每个block的header (主要记录版本号,是否允许反向查找,value的数量,列名长度和列名)
- 每1列具体的值
Long型指标
Druid中对Long型指标会先进行编码,然后按block进行压缩。编码算法包含差分编码和table编码,压缩算法包含LZ4和LZF。
Float型指标
Druid对于Float类型的指标不会进行编码,只会按block进行压缩。
Complex型指标
Druid对于HyperUnique,Cardinality,Histogram,Sketch等复杂指标不会进行编码和压缩处理,每种复杂指标的Serde方式由每种指标自己的ComplexMetricSerde实现类实现。
String 维度的存储格式
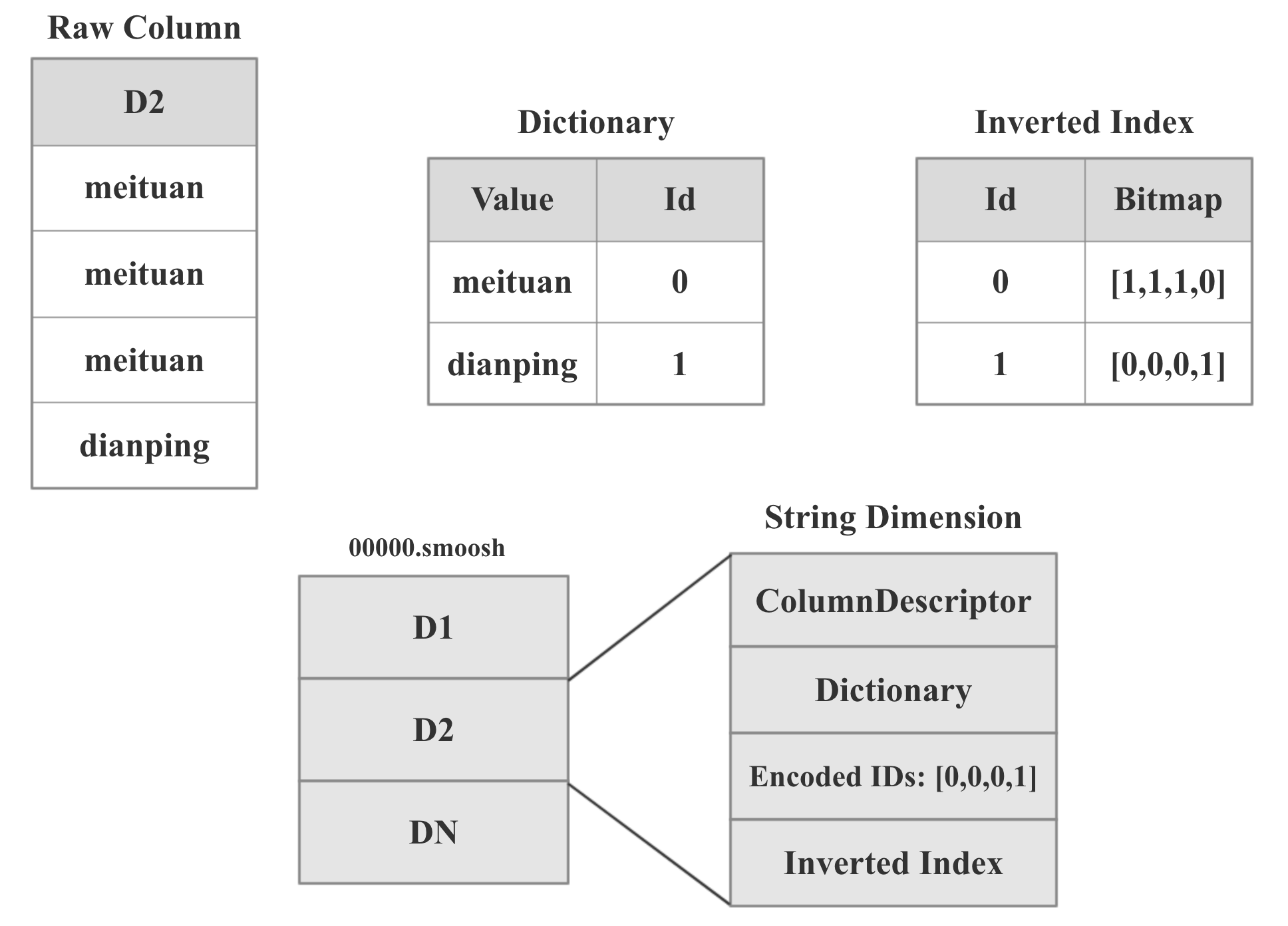
String维度的存储格式如上图所示,前面提到过,时间列,维度列,指标列由两部分组成:ColumnDescriptor和binary数据。 String维度的binary数据主要由3部分组成:dict,字典编码后的id数组,用于倒排索引的bitmap。
以上图中的D2维度列为例,总共有4行,前3行的值是meituan,第4行的值是dianing。Druid中dict的实现十分简单,就是一个hashmap。图中dict的内容就是将meituan编码为0,dianping编码为1。 Id数组的内容就是用编码后的ID替换掉原始值,所以就是[1,1,1,0]。第3部分的倒排索引就是用bitmap表示某个值是否出现在某行中,如果出现了,bitmap对应的位置就会置为1,如图:meituan在前3行中都有出现,所以倒排索引1:[1,1,1,0]就表示meituan在前3行中出现。
显然,倒排索引的大小是列的基数*总的行数,如果没有处理的话结果必然会很大。不过好在如果维度列如果基数很高的话,bitmap就会比较稀疏,而稀疏的bitmap可以进行高效的压缩。
Segment生成过程
- Add Row to Map
- Begin persist to disk
- Write version file
- Merge and write dimension dict
- Write time column
- Write metric column
- Write dimension column
- Write index.drd
- Merge and write bitmaps
- Write metadata.drd
Segment load过程

- Read version
- Load segment to MappedByteBuffer
- Get column offset from meta
- Deserialize each column from ByteBuffer
Segment Query过程
Druid查询的最小单位是Segment,Segment在查询之前必须先load到内存,load过程如上一步所述。如果没有索引的话,我们的查询过程就只能Scan的,遇到符合条件的行选择出来,但是所有查询都进行全表Scan肯定是不可行的,所以我们需要索引来快速过滤不需要的行。Druid的Segmenet查询过程如下:
- 构造1个Cursor进行迭代
- 查询之前构造出Fliter
- 根据Index匹配Fliter,得到满足条件的Row的Offset
- 根据每列的ColumnSelector去指定Row读取需要的列。
Druid的编码和压缩
前面已经提到了,Druid对Long型的指标进行了差分编码和Table编码,Long型和Float型的指标进行了LZ4或者LZF压缩。
其实编码和压缩本质上是一个东西,一切熵增的编码都是压缩。 在计算机领域,我们一般把针对特定类型的编码称之为编码,针对任意类型的通用编码称之为压缩。
编码和压缩的本质就是让每一个bit尽可能带有更多的信息。
总结
本文主要分享了Druid Storage的眼里,既然Druid Storage专门为了OLAP场景设计,我们在Kylin中是不是可以用Druid Storage 替换掉HBase呢? 下一篇我将分享《Apache Kylin on Druid Storage 原理和实践》
参考资料
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
