Google Mesa 论文解读
作者: 康凯森
日期: 2018-01-28
分类: OLAP
What Google Mesa
Google Mese 是可以多数据中心,近实时,高可扩展的分析型数据仓库。
Why Google Mesa
- Atomic Updates.
- Consistency and Correctness.
- Availability: 永不停服,无论是预期内还是预期外的,并可以接受一个数据中心完全down掉。
- Near Real-Time Update Throughput: 近实时的高吞吐更新。数据摄入时不仅支持追加新数据也支持更新已有数据。
- Query Performance: 同时支持数百毫秒低延迟的点查询和高吞吐的批量查询。
- Scalability: 数据摄入和查询性能可以随集群规模线性增长。
- Online Data and Metadata Transformation:在线的表Schema变更,表的Schema变更不会影响数据的摄入和查询。
How Google Mesa
为了实现storage scalability 和availability, Mesa的数据进行水平分区和多副本;
为了实现数据一致性和数据更新时不想影响查询,Mesa的底层数据采用多版本管理;
为了实现数据更新的可扩展性,数据的更新是batch的,每次更新会分配一个版本号,然后周期性的摄入到Mesa;
为了实现多数据中心的元数据一致性,Mesa采用了基于Paxos的一致性协议。
下面具体介绍Mesa的实现原理。
Mesa存储系统
在Mesa中将OLAP系统的维度称为key,将指标称为value。
Mesa数据模型
Mesa中的数据依然是按照table维护,每个表都有明确的table schema,table schema指定了key和baue的集合K和V,以及指标的聚合函数:aggregation F: V x V -> V ,相同维度下的指标会按照聚合函数F进行聚合,F必须满足结合律,大多数F也满足交换律,特殊的replace函数F(v0, v1) =v1除外,table schema也指定了所有维度上的有序索引。
replace函数的作用是实现数据更新,一般OLAP系统的数据都是只支持append的,但是像电商中交易的退款,广告点击中的无效点击处理,都需要去更新之前写入的单条数据,在Kylin这种没有relpace函数的系统中我们必须把包含对应更新记录的segment数据全部重刷,但是有了relpace函数,我们只需要再追加1条新的记录即可。
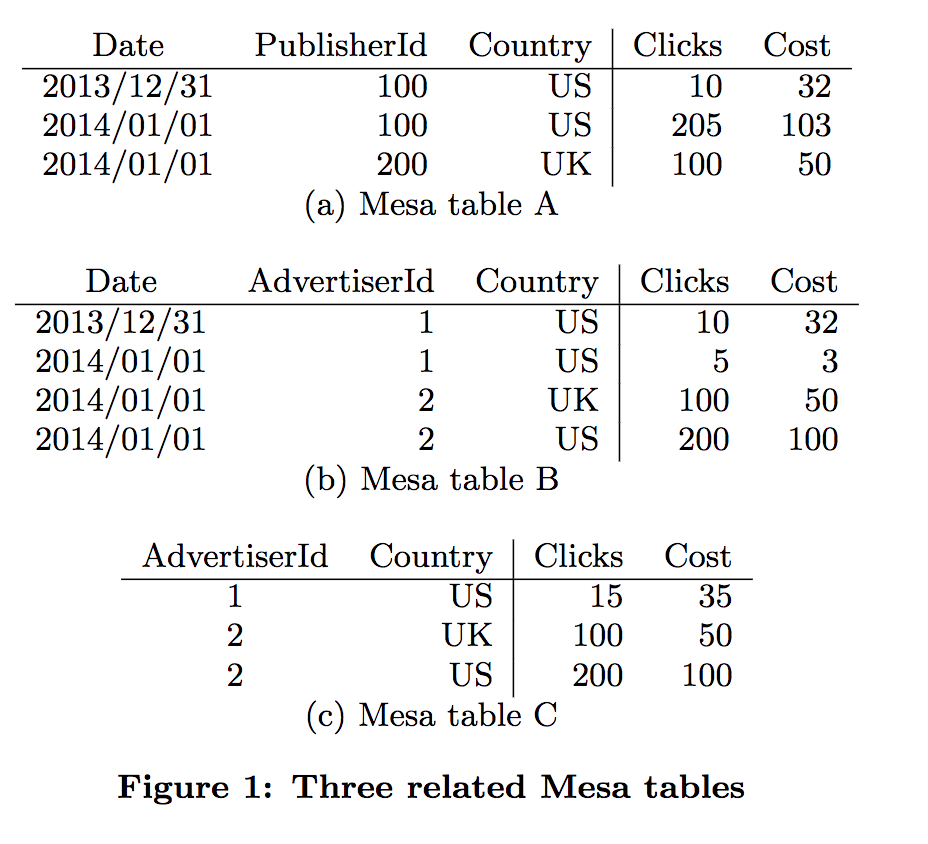
如下图,含有Data, PublisherId,Country, AdvertiserId 4个维度和Clicks,Cost2个Sum指标, 下图就是这个4个纬度和2个指标组成的3个子表(Roll Up表,或者称为materialized views),等价于Kylin中的3个Cuboid。
Table C可以通过Table B上的以下SQL:
SELECT SUM(Clicks),SUM(Cost) GROUP BY AdvertiserId, Country 得到,在Kylin中相当于Table B是Table C的父Cuboid,Table B 可以通过现场聚合计算出Table C。
Mesa数据更新和查询
为了获得更高的吞吐量,Mase的数据更新是按照batch来更新的。为了在数据更新时不影响数据查询以及保证更新的原子性,Mase采用了MVCC的方式,所以在数据更新时每个batch都需要指定一个verison。
由于Mesa采用了MVCC,所以查询时也需要指定verison,除此之外,也需要指定基于维度的predicate 和 查询的指标。 为了回答对于特定version n的查询,Mesa需要聚合[0,n]范围内所有的deltas.
Mesa数据版本化管理
数据的版本化虽然可以解决读写冲突和更新的原子性,但是也带来了以下问题:
- 存储成本。 多版本意味着我们需要存储多份数据,但是由于聚合后的数据一般比较小,所以这个问题还好。
- 查询时延。 如果有很多版本,那么查询时需要遍历的版本数据就会很多,自然就会增大查询时延。
为了解决这两个问题,常见的思路就是及时删除不需要的、过期的数据,以及将小的文件merge为大的文件。

如上图所示,Mesa的merge策略和 LevelDB, HBase很像。类似HBase的minor compaction 和major compaction,Mesa中引入了cumulative compaction和base compaction的概念。 Mesa中将包含了一定版本的数据称为deltas, 表示为[V1, V2],刚实时写入的小deltas, 称之为singleton deltas,然后每到一定的版本数,图中是10,就通过cumulative compaction将10个singleton deltas合并为1个cumulative deltas,最终每天会通过base compaction将所有一定周期的内的deltas都合并为base deltas。 所以查询时只需要查询1个base deltas, 1个cumulative deltas和少数singleton deltas即可。
注意,compaction是在后台并发和异步执行的,此外由于Mesa的存储是按照key有序存储的,所以deltas的merge是线性时间的。
Mesa物理数据和索引结构
由于Mesa的每个deltas都是immutable,所以Mesa的物理存储格式不需要支持增量修改,可以大大简化设计。存储设计上的主要需求是存储空间高效和快速查询特定key。为了能够根据特定key快速查询,我们就需要给特定key建立索引。每个Table可以有1个或者多个Table Index。
Mesa中一个Table的数据按照特定的大小拆分为data files,等价于Kylin和Druid中的segment,然后几百行的数据会组织成一个row blocks,每个row blocks按照column进行存储。
每个data files都会有对应的index file。一个索引项是< key, value>, key是row blocks的第一个key,value是row blocks在data files中的offest。 所以查找特定key的过程也很简单,先加载index文件,二分查找index文件获取包含特定key的row blocks的offest,然后从data files中获取指定的row blocks,最后在row blocks中二分查询特定的key。
Mesa系统架构
Mesa主要由两部分组成:更新(导入)系统和查询系统,Mesa的元数据存储在BigTable(HBase),数据存储在Colossus(Google HDFS的下一代存储系统)
Mesa更新系统
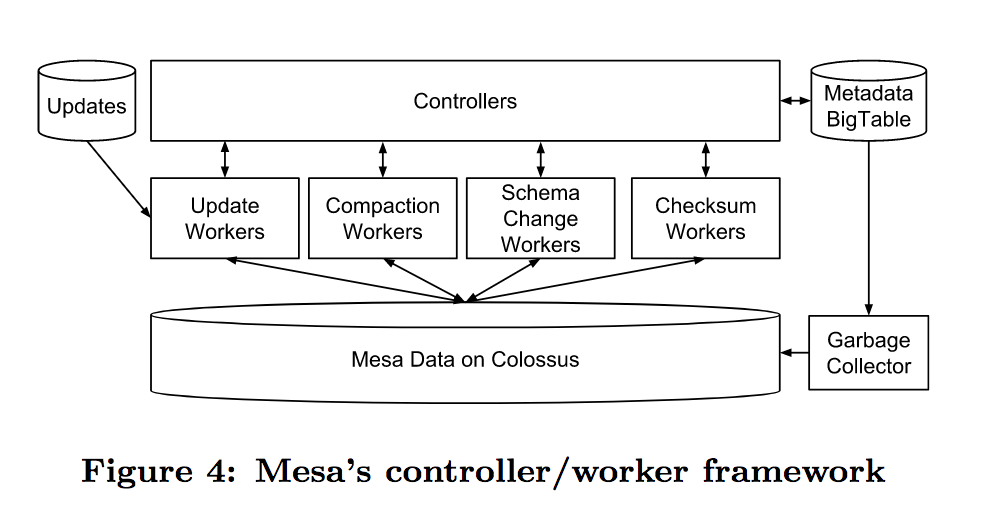
Mesa的更新系统十分像Kylin的JobServer。是controller/worker framework,controller主要有两个职责:table的元数据缓存和各种worker的调度器。 和Kylin一样,元数据缓存就必然涉及到缓存的更新和淘汰,Mesa也引入了事件监听机制去更新元数据缓存。controller的worker调度器也和kylin中的job调度器类似,区别是Mesa有多种不同的worker,所以controller需要为不同的worker维护不同的调度器。
每个worker都有自己独立的职责,比如Update workers负责数据的更新,Compaction workers负责delta的compaction,Schema Change workers负责实现table的schema在线变更,Checksum workers负责校验数据文件是否损坏。 图中的Garbage Collector主要作用是当一些workers失败时,清理work的中间数据。
注意,controller是无状态的,controller在启动的时候就会去BigTable拉取元数据,所以更新系统挂掉是不会影响查询的,和Kylin一样,Kylin的JobServer挂掉不会影响QueryServer。为了保证可扩展性,controller可以按照table shard。
Mesa查询系统
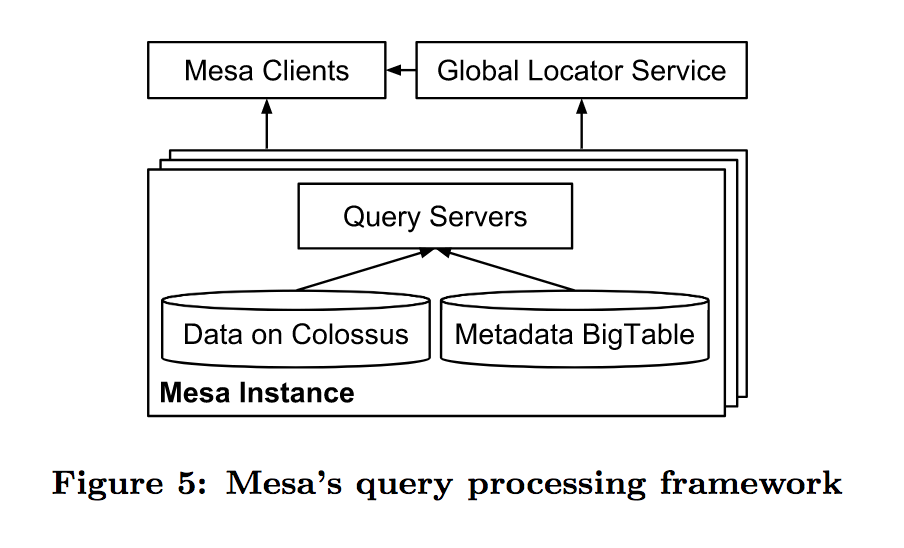
如上图所示,是Mesa 查询系统的架构,十分简单。 Global Locator Service是用来知道目标table是由哪个query server负责的,和HBase的meat table,以及Druid的coordinator作用类似。
Mesa为了满足用户对不同类型查询的不同性能需求,利用标签对低延迟的点查询和高吞吐的批量查询进行隔离和优先级设置。
类似HBase的RsGroup,Druid的Router,Kylin不同域名下的查询集群,Mesa在queryServer中引入了sets的概念,论文提到的sets的意义是便于灰度上线和升级,其实更大的意义是可以实现业务隔离。
类似HBase中的regionServer要尽可能利用内存的cache,Mesa的query server也是尽可能利用内存,让相同table的查询落到指定的几台query server上,尽可能少的直接从底层存储Colossus读取数据。
Mesa多数据中心下的一致更新机制
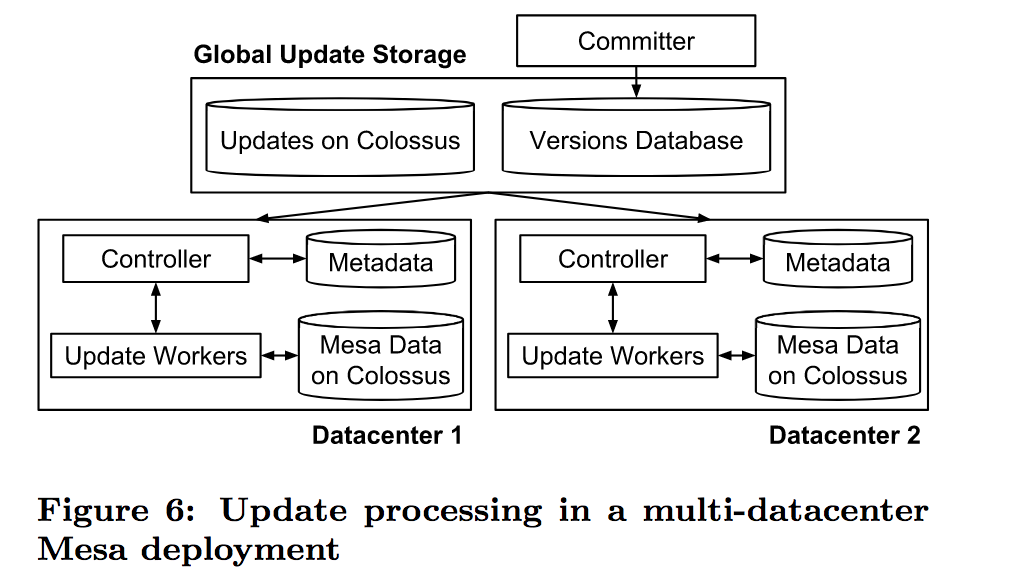
为了实现多数据中心的一致性更新,Mesa引入了committer组件,committer负责协调在多数据中心实例下,一次只更新一个版本。在更新前,committer会给每个batch的更新分配一个version,存入version database,然后Mesa的controllers会监听versions database的change, 如果监听到change, Mesa会分配work给Update workers,接着controllers会根据work执行结果的状态信息更新version database,最终committer会检查verion提交的一致性条件是否满足(比如,一个table有多个roll up表,那么必须所有roll up表都更新后才可以提交),如果满足的话,就最终更新versions database中的version。
Mesa的一致性更新机制有两个显著的特点:
- 数据的更新和查询都没有锁,这也是MVCC的好处
- 数据是异步更新,元数据是基于Paxos协议同步更新
这两个特点可以让Mesa的数据更新和查询的吞吐量都很高。
Mesa的优化改进
Mesa查询性能优化
主要有3点:
- delta预过滤,原理类似partition预过滤,避免读取不必要的delta
- scan-to-seek,原理类似HBase的fuzzy filter,主要用于靠后的key的过滤,原理很好理解,具体可以看论文,简单来说就是能不能的数据就不读。
- resume key,Mesa返回数据是流式返回的,一次一个block,每个block会有个resume key。 所以当某个查询执行慢时,Mesa的client可以将查询重新提交到另一个query server并带上resume key,那么另一个query server就可以从resume key的地方继续执行而不需要重新执行一次。 原理类似Kylin JobServer的resume。
Mesa Worker并行化
就是利用Mapreducer来执行Worker的任务,思想和Kylin的JobServer一样。
Mesa Schema在线变更
所谓的Schema在线变更就是指scheme的变更不会影响数据的正常导入和查询。Schema在线变更是一个十分重要的feature,因为在实际的业务中,Schema的变更会十分频繁,所以如果每次Schema变更都需要用户重刷历史数据的话,用户就会很痛。
要实现Schema在线变更,最笨的办法如下:
- 基于固定version的table Copy一份数据并按照新的schema进行存储
- 回放并更新当前version和之前固定version的数据
- 将元数据的schema更新为新的schema
- 当旧的schema没有查询后,删除旧schema的数据
这种办法的代价很高,需要重刷所有历史数据,但是可以处理所有case。
对于shcema 变更的部分case,例如加列,Mesa提出了linked schema change的做法,就是对于历史数据不会重刷,新摄入的数据都按照新的schema处理,对于旧数据,新加列的值直接用对应数据类型的默认值填充。显然这种做法无法处理所有情况,比如:删除排序列中的一列, 修改列的类型等。
Kylin只支持最笨的方法,Druid的做法类似linked schema change。
Mese最后也分享了下系统开发中的一些经验,不过没有特别的,都是经常提到的东西。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
