Apache Kylin 精确去重和全局字典权威指南
作者: 康凯森
日期: 2018-01-07
分类: OLAP
Kylin官方现在关于精确去重的blog Use Count Distinct in Apache Kylin是基于Kylin 1.5.3的,其中的使用方式和优化方法已经过时,本文将基于Kylin 2.3.0 介绍精确去重和全局字典的用法,调优,FAQ和核心原理。
本文的主要内容如下:
Kylin精确去重指标的用法
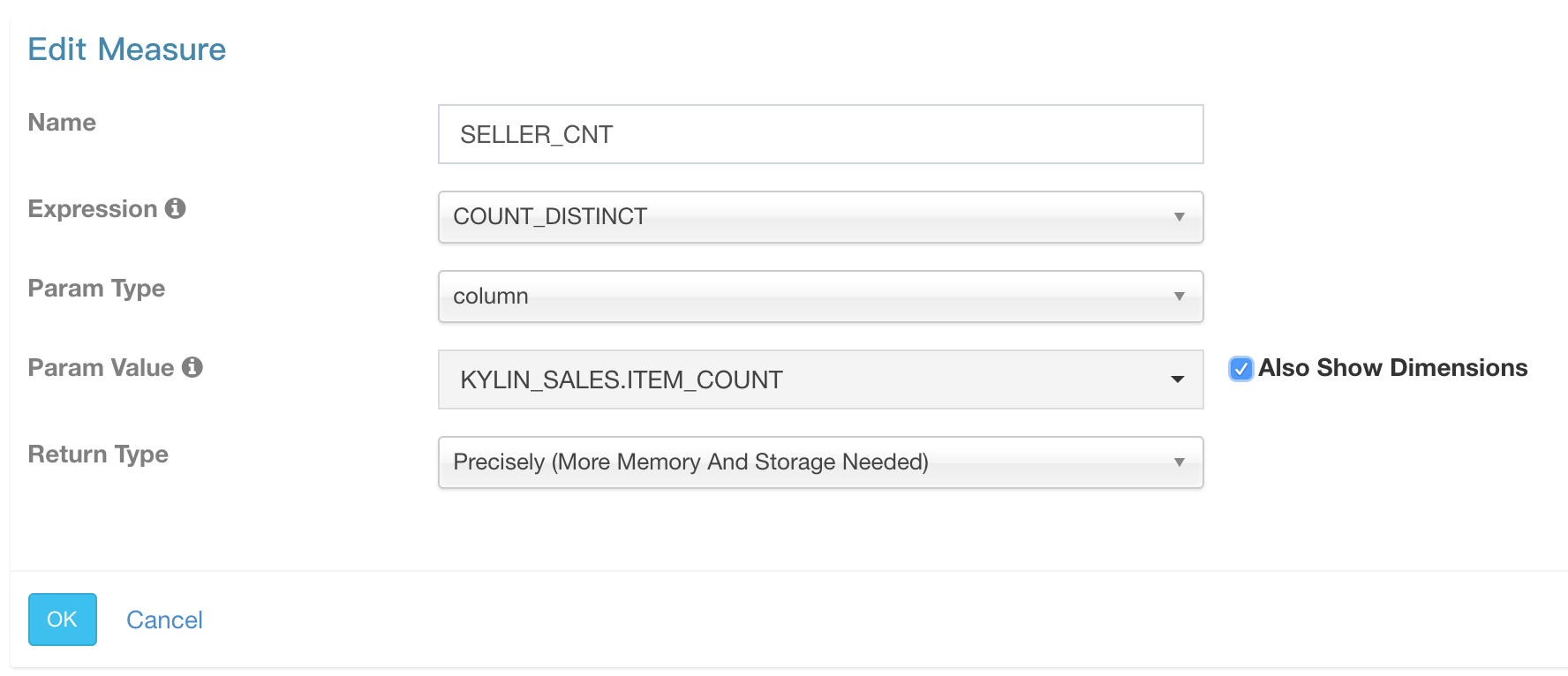
如上图,编辑指标时Expression选择COUNT_DISTINCT,Return Type选择 Precisely。 如果你的精确去重列的基数很小,你就已经可以愉快地利用Kylin进行精确去重计算了。
Kylin精确去重指标的优化
当精确去重指标列的基数达到数千万,数亿,或者有多个精确去重指标时,我们就需要进行一些优化。大家可以根据下面的Case 进行优化,不同的优化方法是可以叠加的。
Case1 : 全局字典的复用
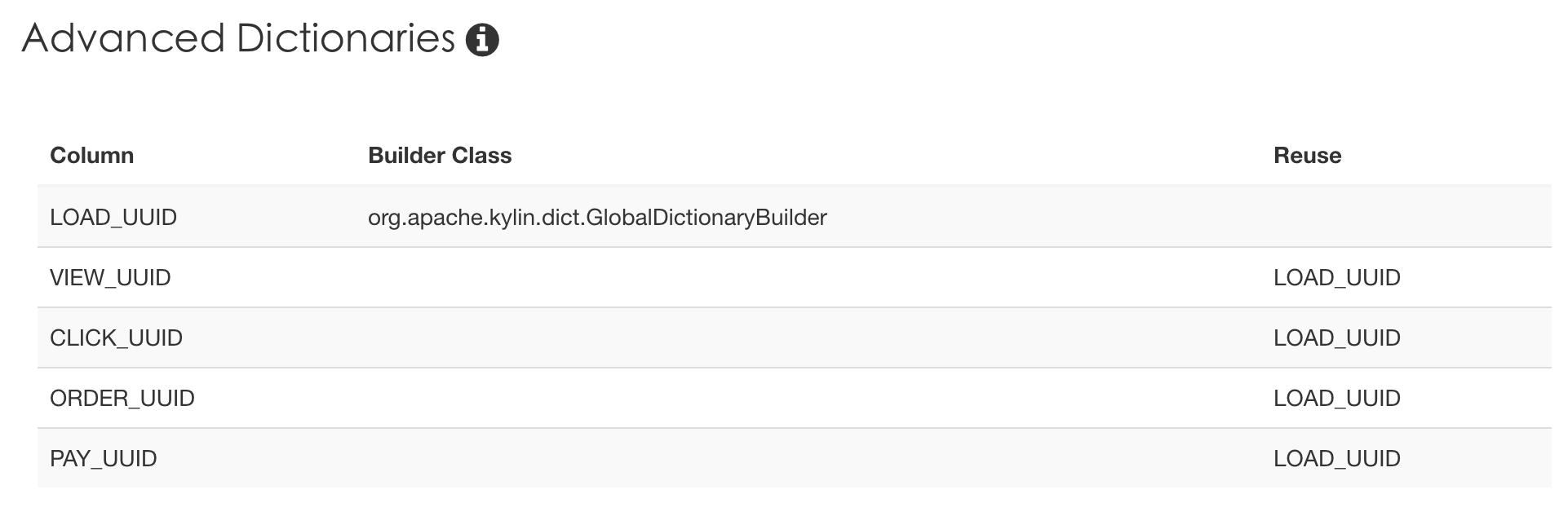
如果1个Cube中有多个全局字典列,且存在A列是B列子集的情况,我们就可以让A列复用B列的全局字典。比如日支付用户数一般就是日活跃用户数的子集,这种关系一般在ETL生产中表现为if (pay = true, uuid, null) as pay_uuid, 我们就可以让pay_uuid reuse uuid的全局字典,如下图:
Case2: 1个Cube只有1个超高基数列的精确去重指标
如果1个Cube有1个或者多个精确去重指标,但是只有1个超高基数列,像PV,UV,订单量这种去重指标,我们可以配置以下参数来优化:
kylin.source.hive.flat-table-cluster-by-dict-column=LOAD_UUID(精确去重指标的列名,不需要加Hive表名)
这个参数的原理是在Cube构建的第2步 "Redistribute Flat Hive Table" 中将Hive表数据按照配置的列Cluster by,让Hive表数据按照Cluster by列有序,以此来减少 "Build Base Cuboid" 这一步对精确去重指标编码时全局字典的内存置换次数。
Case3: 1个Cube有多个超高基数列的精确去重指标
如果一个Cube中同时有用户数和设备数这种超高基数的精确去重指标,可以考虑拆分成两个cube,转化成Case2,如果不能拆分成两个Cube,就需要增大"Build Base Cuboid" 这一步MR的内存,可以配置以下参数:
kylin.source.hive.flat-table-cluster-by-dict-column=基数最高的精确去重列名 (不需要加Hive表名)
kylin.engine.mr.base-cuboid-config-override.mapred.map.child.java.opts = -Xmx4g
kylin.engine.mr.base-cuboid-config-override.mapreduce.map.memory.mb = 4500
Case4: 精确去重指标无需跨Segment上卷聚合
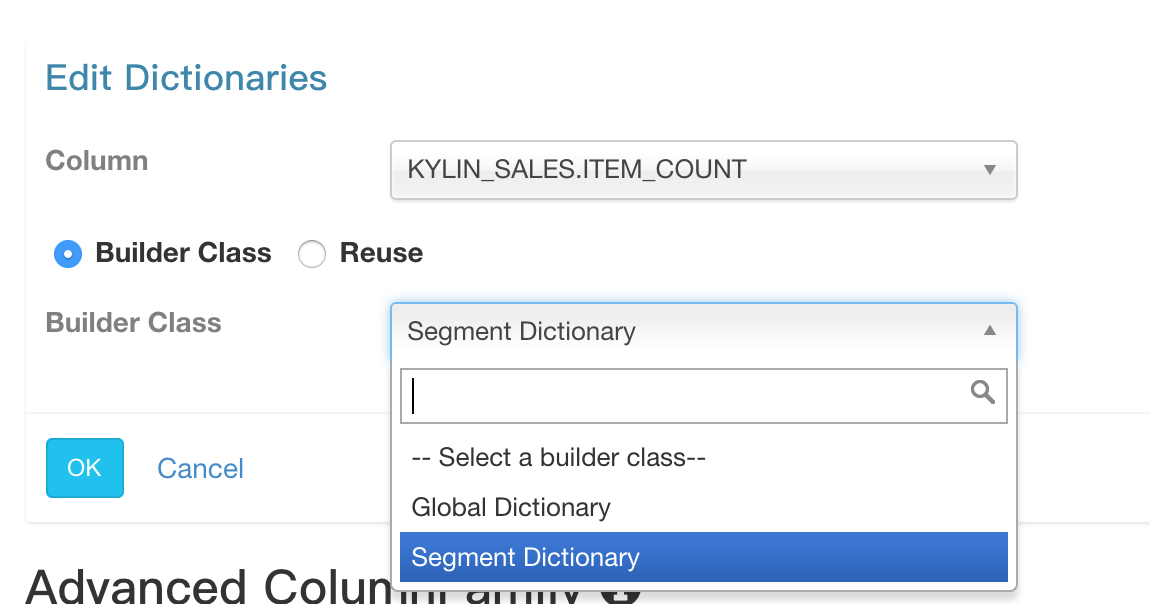
如果你的精确去重指标只需要按天进行去重,那么可以用 Segment Dictionary 代替 Global Dictionary 。 如图:
按天进行精确去重可以理解为你的SQL会按照dt字段Group by,不会有类似下面的SQL:
SELECT A, B, count(distinct uuid),
FROM table
WHERE dt between '20170125' and '20170224'
使用Segment Dictionary的优点是构建速度会十分快,因为Segment Dictionary是基于Segment粒度的,不是全局的。
Case5: Cube是非分区的
如果你的Cube是非分区的,每天全量构建,那么和Case 4一样,也可以用 Segment Dictionary 代替 Global Dictionary。
Case6: 一个Cube包含较多精确去重指标
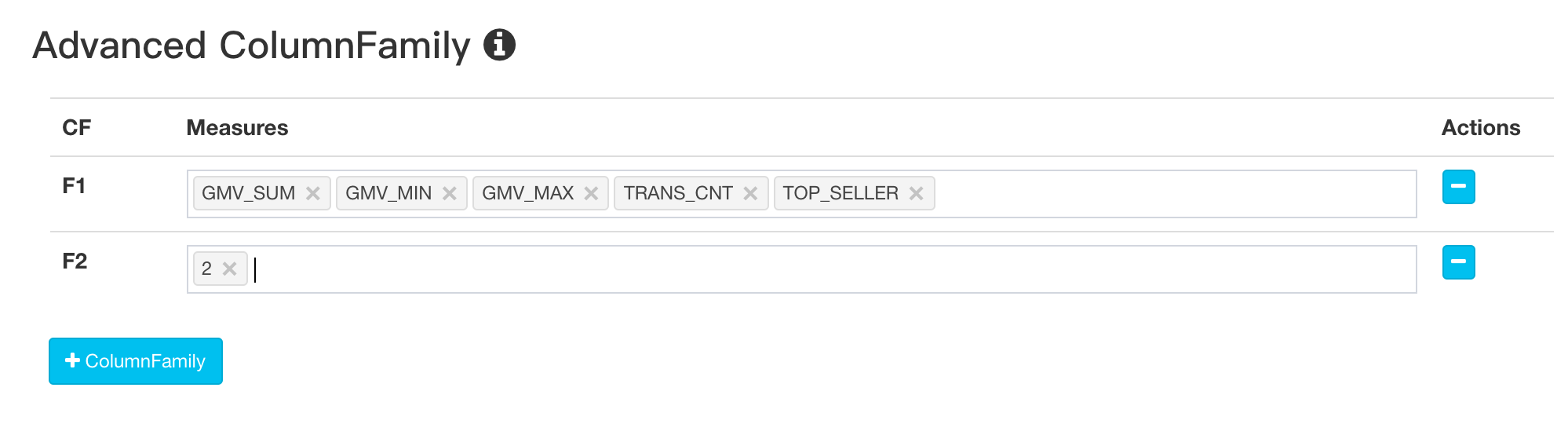
如果你的Cube有10多个甚至几十个精确去重指标,且大多数查询一次只会查询1个或者几个精确去重指标,那么可以考虑将精确去重指标拆分到多个列族,这样做到好处是可以加速查询,Kylin默认是把所有精确去重指标都放在HBase的1个列族中。拆分列族是在Cube编辑的第5步的Advanced ColumnFamily部分,如图:
Kylin精确去重和全局字典的FAQ
Q: Kylin的精确去重指标查询性能如何?
A:相比Sum,Count这种简单指标,精确去重指标的查询会慢一些,根据查询的复杂程度,时间范围,去重指标的数量等因素不同,查询时延从数百毫秒,几秒,10多秒不等。 一般情况下都可以秒级响应。
Q: Kylin的精确去重指标支持跨Segment上卷吗?
A:支持。
Q: Kylin的精确去重指标为什么可以跨Segment上卷?
A:因为Kylin的精确去重指标使用了Bitmap保留明细值,并使用全局字典保证所有Value在所有Bitmap中对应的Int值都是确定且唯一的。
Q: Kylin的精确去重指标为什么不只存储最终的去重值?
A:因为在Kylin中精确去重指标需要支持上卷聚合,所以仅保留最终的去重值会导致查询出错。
Q: Kylin的精确去重指标为什么使用Bitmap进行存储?
A:因为在Kylin中精确去重指标需要支持上卷聚合,所以需要保留明细,而计算机存储的最小单位是bit, 所以我们可以很自然地想到Bitmap这种数据结构。
Q: Kylin的精确去重指标在HBase中存储格式?
A:是RoaringBitmap序列化后的二进制数据。
Q: Kylin的精确去重指标为什么需要全局字典?
A:为了保证String类型的数值在不同Segment中始终可以映射到相同的Int值。
Q: Kylin查询时需要加载全局字典吗?
A:不需要,全局字典的作用是在构建时对非Int类型的精确去重指标进行编码,在Cube构建时会更新全局字典,然后在"Build Base Cuboid" 加载全局字典进行编码。
Q: 全局字典在Cube Merge时会进行重新构建吗?
A:不会,全局字典不会参与Cube Merge。
Q: Kylin的维度列可以使用全局字典吗?
A:不可以,因为全局字典仅支持根据Value查询Id,不可以根据Id反向查找Value。
Q: Kylin的全局字典是什么粒度的全局?
A:Kylin的全局字典是针对Hive表的某一列的,在1个Kylin集群中,某个Hive表的某一列只会有1个全局字典。
Q: Kylin的全局字典存储在哪?
A:HDFS上。其路径是kylin.env.hdfs-working-dir+resources/GlobalDict/dict+/sourceTable+/sourceColumn
Q: Kylin的全局字典构建会不会越来越慢?
A:会。如果使用Global Dictionary的话全局字典会越来越大,构建也会越来越慢。使用Segment Dictionary则不会有这个问题。
Q: Kylin的全局字典支持Segment并发构建吗?
A:支持。 但是全局字典为了保证分布式环境下数据的一致性,在构建全局字典时,必须先获取分布式锁,所以构建全局字典这一步是串行的。
Q: Kylin中某1列可以作为精确去重指标又作为维度吗?
A:可以。 如果是Int类型,不需要做特殊处理;如果是非Int类型,作为维度时不能选择默认的dict编码方式,需要选择整型或者定长编码。
全局字典相关的Cube构建问题
问题1: "Build Base Cuboid" java.lang.IllegalArgumentException: Value XXX not exists!
该问题的一般原因是全局字典的Reuse设置有误或者Hive表有脏数据。
解决方法:
1 确认全局字典的Reuse设置是否合理
参考 精确去重指标的优化的Case1,设置A列Reuse B列的全局字典时,一定要确保在ETL的Hive表定义中A列的数据就是B列数据的子集,不要想当然根据业务含义来确定A列是否是B列的子集。
2 确认Hive表是否有脏数据
在Kylin页面点击MR job链接,查看MR log,找到如下log, 确认Insane record 这条记录是不是脏数据。
2017-04-14 17:14:19,309 ERROR [main] org.apache.kylin.engine.mr.steps.BaseCuboidMapperBase: Insane record: [17184, 2450, 24205, 440800, C, 6, 4, 2, 7.7, -998, 0, 0, 17.5, 17.5, 17.5, 17.5, 17.5, 17.5, 1, 1, 1, 20170116~20170122, 湛江, 团购android, 团购app, 团购, 未知, \N, \N, \N, \N, \N, 0, �Q;���=�����1 �6,� �_����;���7�, ��������~)� ����������[, �Q;���=�����1 �6,� �_����;���7�, ��������~)� ����������[, �Q;���=�����1 �6,� �_����;���7�, ��������~)� ����������[, \N, \N, \N, 315174395
java.lang.IllegalArgumentException: Value '�Q;���=�����1 �6,� �_����;���7�' (\xEF\xBF\xBDQ;\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD=\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD1 \xEF\xBF\xBD6\x05,\xEF\xBF\xBD \xEF\xBF\xBD_\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD\xEF\xBF\xBD;\xEF\xBF\xBD\x12\x00\xEF\xBF\xBD\xEF\xBF\xBD7\xEF\xBF\xBD) not exists!
at org.apache.kylin.common.util.Dictionary.getIdFromValueBytes(Dictionary.java:162)
at org.apache.kylin.dict.AppendTrieDictionary.getIdFromValueImpl(AppendTrieDictionary.java:153)
at org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:98)
at org.apache.kylin.common.util.Dictionary.getIdFromValue(Dictionary.java:78)
at org.apache.kylin.measure.bitmap.BitmapMeasureType$1.valueOf(BitmapMeasureType.java:118)
如果可以容忍脏数据,请添加以下参数,否则请清理脏数据。
kylin.job.error-record-threshold = 100 //该参数表示每个mapper可以容忍的异常记录数,默认是0。
问题2: "Build Base Cuboid" 这一步Mapper 进度很慢或者 Timed out after 600 secs
这个问题的一般原因是Cube中的全局字典很大,Mapper 内存不足,导致全局字典进行频繁的内存置换。解决方法可以参考精确去重指标的优化的Case1,Case2,Case3,Case4,Case5。
Kylin精确去重的原理
精确去重指标实现的两个核心难点:
- 支持任意粒度的上卷聚合
- 支持String等非Int类型数据
难点的解决方案:
- 前面提到,为了支持任意粒度的上卷聚合,我们需要保留明细数据,而计算机存储的最小单位是bit,所以采用了Bitmap来存储Kylin的精确去重指标。Kylin在实际工程中采用的是业界中广泛使用, 性难最优的RoaringBitmap库。
- RoaringBitmap仅支持Int类型数据,为了支持String等非Int类型数据,我们需要一个String到Int的映射,而且要求所有Segment中同一个String始终映射到同一个Int。 为什么呢? 假如UUID列的String "A" 在Segment1中映射到Int 1,但是String "A" 却在Segment2中映射到INT 2,那么当UUID列需要跨Segment1和Segment2去重时,显然就会出错。 所以我们引入了全局字典,来保证String等非Int类型数据始终映射到同一个Int值。
无需上卷的精确去重查询优化:
前面提到,为了支持任意粒度的上卷聚合,我们使用Bitmap存储精确去重指标。所以在查询时,我们需要先从HBase端将整个Bitmap传输给Kylin的QueryServer,Kylin的QueryServr再根据Bitmap计算出 去重值。但是在实际的使用场景中,用户的一些甚至多数精确去重查询是不需要上卷聚合的, 比如用户的Cube按照dt列分区,且已经预计算好(A,dt)的Cuboid,那么下面的SQL查询时在HBase端和Kylin的QueryServer端都是无需聚合的:
SELECT A, count(distinct uuid),
FROM table
WHERE dt between '20170125' and '20170224'
group by dt, A
针对上面提到的场景,我们进行了优化,符合优化规则的查询会在HBase端直接返回最终的去重值,该优化可以将精确去重的查询提高一个数量级,原本需要几秒的查询优化后只需数百毫秒;同时也降低了Kylin QueryServr的内存使用。
Kylin全局字典的原理
全局字典的意义是保证所有Value映射到全局唯一且连续的Int ID ,唯一是保证精确去重查询可以跨Segment上卷,连续的原因是RoaringBitmap对连续的值可以进行更好的压缩。全局字典实现的几个核心难点:
- 核心数据结构的选择
- 分布式环境下数据一致性的保证
- 超大字典构建时的内存使用
- 超大字典加载时的内存使用
难点的解决方案:
1 可追加可分裂的Trie树:
全局字典使用的核心数据结构是AppendTrieDictionary,根据Trie树改造而来。我们知道Trie树中Value对应的Id是根据Value在树中的位置决定的,所以Trie树是不可变的,不可以追加数据,因为追加数据后同一个Value就会映射到不同的Id,为了解决这一点,AppendTrieDictionary将Value对应的Id直接写入了节点本身,这样就保证了同一个Value始终会映射到同一个Id,但同时也导致了AppendTrieDictionary只能根据Value查找Id,不能根据Id查找Value。
因为全局字典是全局的,会不断进行追加,所以全局字典会越来越大,我们不可能一次将整个AppendTrieDictionary 加载到内存,所以AppendTrieDictionary是可以分裂的,当一棵子树的节点个数超过一定值(默认是1千万),就会将一棵子树从中间分裂成两棵子树。每个分裂的子树是一个slice。 AppendTrieDictionary的构建是逐个slice进行构建,内存中同时只会有一个slice; AppendTrieDictionary的加载是使用LoadingCache的softValues策略来管理slice的换入换出。
关于AppendTrieDictionary的更多细节,可以参考:Apache Kylin精确计数与全局字典揭秘
2 分布式环境下数据一致性的保证:
MVCC: 全局字典最终是持久化在HDFS目录上,为了避免读写冲突,我们采用了MVCC,当读AppendTrieDictionary时,永远只读取最新的Version目录;当写AppendTrieDictionary时,会将最新的Verion目录copy到working目录,修改完成且通过正确性校验后,会将working目录rename为新的Version目录。
分布式锁:通过分布式锁,我们保证了在多JobServer的多Segment并发构建下,1个Kylin集群在同一时刻只会有1个线程可以修改AppendTrieDictionary。
3 全局字典使用MR构建:
虽然1个全局字典构建时只会加载AppendTrieDictionary的1个Slice,但是当Kylin JobServer上有数十个全局字典同时构建时,Kylin JobServer 会经常OOM, 为了解决这个问题,我们将全局字典的构建移到了MR中。 使用MR构建全局字典后,Kylin JobServer的内存使用量显著降低,调度的并发能力也提升1到2个数量级,也可以加速多列全局字典的构建。
4 超大字典加载时的内存优化:
全局字典的加载发生在"Build Base Cuboid"的Mapper这一步,前面提到,AppendTrieDictionary的加载是使用LoadingCache的softValues策略管理slice的换入换出。 所以当全局字典远大于的"Build Base Cuboid"的Mapper内存,且Mapper输入是无序的情况下,全局字典就会频繁换入换出。所以我们做了之前Case2的优化,让Hive数据可以按照某列排序,这样就可以保证全局字典有序按需加载。 显然,这个优化只能handle只有1列超高基数列的场景,无法handle有多个超高基数列的场景。
5 支持非全局的AppendTrieDictionary:
前面我们提到,全局字典最重要的意义是支持精确去重指标跨Segment上卷,但在某些应用场景下,用户的确不需要Segment上卷。 比如用户只需要按天进行去重,或者Cube本身就是不分区的(每次全量构建)。 针对这一点,我们新增了一种SegmentAppendTrieDictBuilder(前面提到的Segment Dictionary ),底层的数据结构依然还是AppendTrieDictionary,只是每次构建时Working目录不是Copy最新的Version目录,而是从空Working目录开始构建,同时字典的元数据也需要重新初始化。由于SegmentAppendTrieDictBuilder是segment粒度的,也不需要分布式锁,所以可以并发构建。使用SegmentAppendTrieDictBuilder后构建和加载时的内存问题也基本不会再有。使用方式可以参考优化部分的case4。
总结
虽然Kylin的精确去重在性能和稳定性方面相比最初已经有了显著的提升,已经在企业级的生产环境中广泛使用,但是依然存在以下痛点:
- 需要用户了解相关配置进行优化;
- 查询时超高基数列的Bitmap使用内存过多;
- 构建时无法很好地处理多个超高基数列的情况;
- 全局字典的构建会越来越慢。
所以在新的一年,我们会对Kylin的精确去重指标进行继续优化并探索新的方案,比如:有没有可能移除全局字典,RoaringBitmap的计算移到堆外,RoaringBitmap的分布式化等。大家有好的想法也欢迎随时交流。
我也相信,Kylin的精确去重会越来越易用,越高效,越稳定。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
