Apache Kylin 精确去重指标优化历程
作者: 康凯森
日期: 2017-01-04
分类: OLAP
本文记录了我将Apache Kylin超高基数的精确去重指标查询提速数十倍的过程,大家有任何建议或者疑问欢迎讨论。
问题背景
某业务方的cube有12个维度,35个指标,其中13个是精确去重指标,并且有一半以上的精确去重指标单天基数在千万级别,cube单天数据量1.5亿行左右。
但是业务方的一个结果仅有21行的精确去重查询竟然需要12秒多:
SELECT A, B, count(distinct uuid),
FROM table
WHERE dt = 17150
GROUP BY A, B
其中HBase端耗时6秒多,Kylin的query server端耗时5秒多。
精确去重指标已经在美团点评生产环境大规模使用,我印象中精确去重的查询的确比普通的Sum指标慢一点,但也是挺快的。这个查询慢的如此离谱,我就决定分析一下,这个查询到底慢在哪。
优化1 将精确去重指标拆分HBase列族
我首先确认了这个cube的维度设计是合理的,这个查询也精准匹配了cuboid,并且在HBase端也只扫描了21行数据。
那么问题来了, 为什么在HBase端只扫描21行数据需要6秒多?一个显而易见的原因是Kylin的精确去重指标是用bitmap存储的明细数据,而这个cube有13个精确去重指标,并且基数都很大。
我从两方面验证了这个猜想:
- 同样SQL的查询Sum指标只需要120毫秒,并且HBase端Scan仅需2毫秒。
- 我用HBase HFile命令行工具查看并计算出HFile单个
KeyValue的大小,发现普通的指标列族的每个KeyValue大小是29B,精确去重指标列族的每个KeyValue大小是37M。
所以我第一个优化就是将精确去重指标拆分到多个HBase列族,优化后效果十分明显。查询时间从12秒多减少到5.7秒左右,HBase端耗时从6秒多减少到1.3秒左右,不过query server耗时依旧有4.5秒多。
优化2 移除不必要的toString避免bitmap deserialize
Kylin的query server耗时依旧有4.5秒多,我猜测肯定还是和bitmap比较大有关,但是为什么bitmap大会导致如此耗时呢?
为了分析query server端查询处理的时间到底花在了哪,我利用Java Mission Control进行了性能分析。
JMC分析很简单,在Kylin的启动进程中增加以下参数:
-XX:+UnlockCommercialFeatures -XX:+FlightRecorder -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints -XX:StartFlightRecording=delay=20s,duration=300s,name=kylin,filename=myrecording.jfr,settings=profile
获得myrecording.jfr文件后,我们在本机执行jmc命令,然后打开myrecording.jfr文件就可以进行性能分析。
热点代码的分析如图:
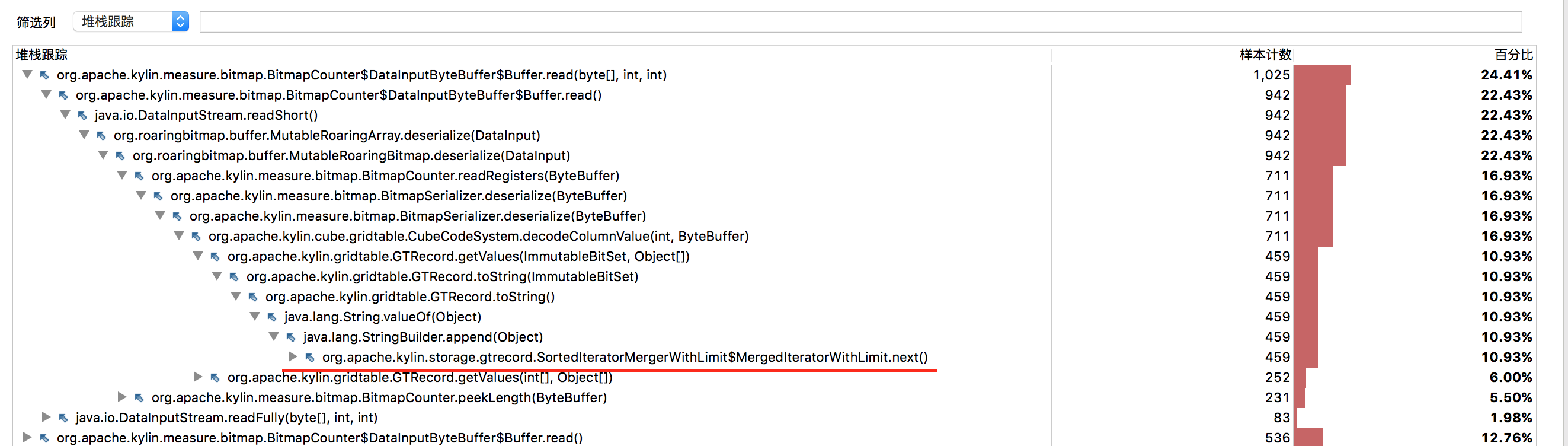
从图中我们可以发现,耗时最多的代码竟然是一个毫无意义的toString。
Preconditions.checkState(comparator.compare(last, fetched) <= 0, "Not sorted! last: " + last + " fetched: " + fetched);
代码中的last 和 fetched就是一个bitamp。
去掉这个toString之后,query server的耗时直接减少1秒多。
优化3 获取bitmap的字节长度时避免deserialize
在优化2去掉无意义的toString之后,热点代码已经变成了对bitmap的deserialize。
不过bitmap的deserialize共有两处,一处是bitmap本身的deserialize,一处是在获取bitmap的字节长度时。
于是很自然的想法就是是在获取bitmap的字节长度时避免deserialize bitmap,当时有两种思路:
- 在serialize bitmap时就写入bitmap的字节长度
- 在
MutableRoaringBitmap序列化的头信息中获取bitmap的字节长度。(Kylin的精确去重使用的bitmap是RoaringBitmap)
我最终确认思路2不可行,采用了思路1。
思路1中一个显然的问题就是如何保证向前兼容,我向前兼容的方法就是根据MutableRoaringBitmap deserialize时的cookie头信息来确认版本,并在新的serialize方式中写入了版本号,便于之后序列化方式的更新和向前兼容。
经过这个优化后,Kylin query server端的耗时再次减少1秒多。
优化4 无需上卷聚合的精确去重查询优化
从精确去重指标在美团点评大规模使用以来,我们发现部分用户的应用场景并没有跨segment上卷聚合的需求,即只需要查询单天的去重值,或是每次全量构建的cube,也无需跨segment上卷聚合。
所以我们希望对无需上卷聚合的精确去重查询进行优化,当时我考虑了两种可行的方案:
方案1: 精确去重指标新增一种返回类型
一个极端的做法是对无需跨segment上卷聚合的精确去重查询,我们只存储最终的去重值。
优点:
- 存储成本会极大降低。
- 查询速度会明显提高。
缺点:
- 无法支持上卷聚合,与Kylin指标的设计原则不符合。
- 无法支持segment的merge,因为要进行merge必须要存储明细的bitmap。
- 新增一种返回类型,对不清楚的用户可能会有误导。
- 查询需要上卷聚合时直接报错,用户体验不好,尽管使用这种返回类型的前提是无需上聚合卷。
实现难点: 如果能够接受以上缺点,实现成本并不高,目前没有想到明显的难点。
方案2:serialize bitmap的同时写入distinct count值。
优点:
- 对用户无影响。
- 符合现在Kylin指标和查询的设计。
缺点:
- 存储依然需要存储明细的bitmap。
- 查询速度提升有限,因为即使不进行任何bitmap serialize,bitmap本身太大也会导致HBase scan,网络传输等过程变慢。
实现难点:
如何根据是否需要上卷聚合来确定是否需要serialize bitmap?
我开始的思路是从查询过程入手,确认在整个查询过程中,哪些地方需要进行上卷聚合。
为此,我仔细阅读了Kylin query server端的查询代码,HBase Coprocessor端的查询代码,看了Calcite的example例子。发现在HBase端,Kylin query server端,cube build时都有可能需要指标的聚合。
此时我又意识到一个问题:
即使我清晰的知道了何时需要聚合,我又该如何把是否聚合的标记传递到精确去重的反序列方法中呢?
现在精确去重的deserialize方法参数只有一个ByteBuffer,如果加参数,就要改变整个kylin指标deserialize的接口,这将会影响所有指标类型,并会造成大范围的改动。 所以我把这个思路放弃了。
后来我"灵光一闪",想到既然我的目标是优化无需上卷的精确去重指标,那为什么还要费劲去deserialize出整个bitmap呢,我只要个distinct count值不就完了。
所以我的目标就集中在BitmapCounter本身的deserialize上,并联想到我提升了Kylin前端加载速度十倍以上的核心思想:延迟加载,就改变了BitmapCounter的deserialize方法,默认只读出distinct count值,不进行bitmap的deserialize,并将那个buffer保留,等到的确需要上卷聚合的时候再根据buffer deserialize 出bitmap。
当然,这个思路可行有一个前提,就是buffer内存拷贝的开销是远小于bitmap deserialize的开销,庆幸的是事实的确如此。
最终经过这个优化,对于无需上卷聚合的精确去重查询,查询速度也有了较大提升。
显然,如你所见,这个优化加速查询的同时加大了需要上卷聚合的精确去重查询的内存开销。我的想法是
- 对于超大数据集并且需要上卷的精确去重查询,用户在分析查询时返回的结果行数应该不会太多。
- 我们需要做好query server端的内存控制。
总结
我通过总共 4个优化,在向前兼容的前提下,后端仅通过100多行的代码改动,对Kylin超高基数的精确去重指标查询有了明显提升,测试中最明显的查询有50倍左右的提升。
大家有任何好的建议或者疑问欢迎在相关的JIRA中讨论。
反思
- 我们应该善于利用各类命令和工具,快速分析和定位问题。
- 重写
toString,hashCode,equals等方法时一定要轻量化,不要有复杂的操作。 - 设计序列化,通信协议,存储格式时,一定要有版本信息,便于之后的更新和向前兼容。
相关Kylin JIRA
- KYLIN-2308 Allow user to set more columnFamily in web 优化1
- KYLIN-2337 Remove expensive toString in SortedIteratorMergerWithLimit 优化2
- KYLIN-2349 Serialize BitmapCounter with peekLength 优化3
- KYLIN-2353 Serialize BitmapCounter with distinct count 优化4
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
