Apache Kylin Job 生成和调度详解
作者: 康凯森
日期: 2016-10-12
分类: OLAP
在Apache Kylin Cube 构建原理 一文中我们知道了Cube的构建需要经过一系列的Job才能完成,那这些Job是如何生成并被调度的呢?
构建Cube的Job
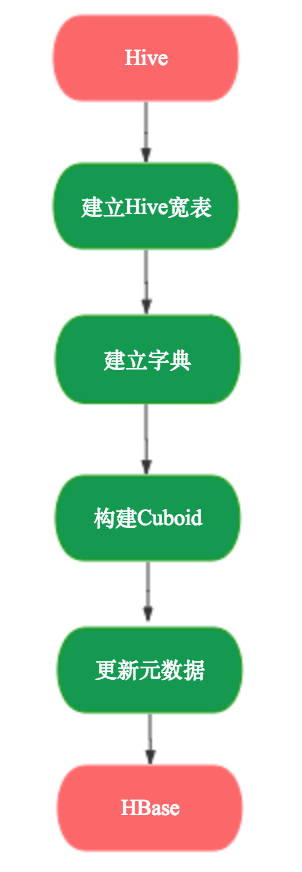
Job 的生成
经过Restful请求调用 JobService的submitJob方法,会根据构建的Segment信息和用户信息生成Job。
job = EngineFactory.createBatchCubingJob(newSeg, submitter);
其中EngineFactory是一个工厂类,可以根据不同的配置选择不同的cube构建类型(Batch或者Streaming)和不同的cube构建算法(Batch Cube有不同的构建算法)
public static DefaultChainedExecutable createBatchCubingJob(CubeSegment newSegment, String submitter) {
return batchEngine(newSegment).createBatchCubingJob(newSegment, submitter);
}
//获取不同的构建算法
public static IBatchCubingEngine batchEngine(IEngineAware aware) {
return batchEngines.get(aware.getEngineType());
}
我们以目前版本主要使用的MRBatchCubingEngine2构建算法分析:
public class MRBatchCubingEngine2 implements IBatchCubingEngine {
//创建单个segment构建的Job
public DefaultChainedExecutable createBatchCubingJob(CubeSegment newSegment, String submitter) {
}
//创建多个segment Merge的Job
public DefaultChainedExecutable createBatchMergeJob(CubeSegment mergeSegment, String submitter) {
}
//获取构建cube的数据源(Hive)
public Class<?> getSourceInterface() {
}
//获取构建cube的存储源(HBase)
public Class<?> getStorageInterface() {
}
}
我们以单个segment的构建过程createBatchCubingJob 分析,其调用了BatchMergeJobBuilder2的build方法,主要是CubingJob用addTask方法将构建cube的每一步job串起来,便于之后调度。
final CubingJob result = CubingJob.createBuildJob((CubeSegment) seg, submitter, config);
// Phase 1: 建立Hive的大宽表
inputSide.addStepPhase1_CreateFlatTable(result);
// Phase 2: 建立字典
result.addTask(createFactDistinctColumnsStepWithStats(jobId));
result.addTask(createBuildDictionaryStep(jobId));
result.addTask(createSaveStatisticsStep(jobId));
outputSide.addStepPhase2_BuildDictionary(result);
// Phase 3: 构建 cube
addLayerCubingSteps(result, jobId, cuboidRootPath);
result.addTask(createInMemCubingStep(jobId, cuboidRootPath));
outputSide.addStepPhase3_BuildCube(result, cuboidRootPath);
// Phase 4: 更新元数据,垃圾清理
result.addTask(createUpdateCubeInfoAfterBuildStep(jobId));
inputSide.addStepPhase4_Cleanup(result);
outputSide.addStepPhase4_Cleanup(result);
CubingJob 到底是什么,我们稍后分析,我们先来看Kylin是如何表达构建Segment过程中的每一个Job。
Executable
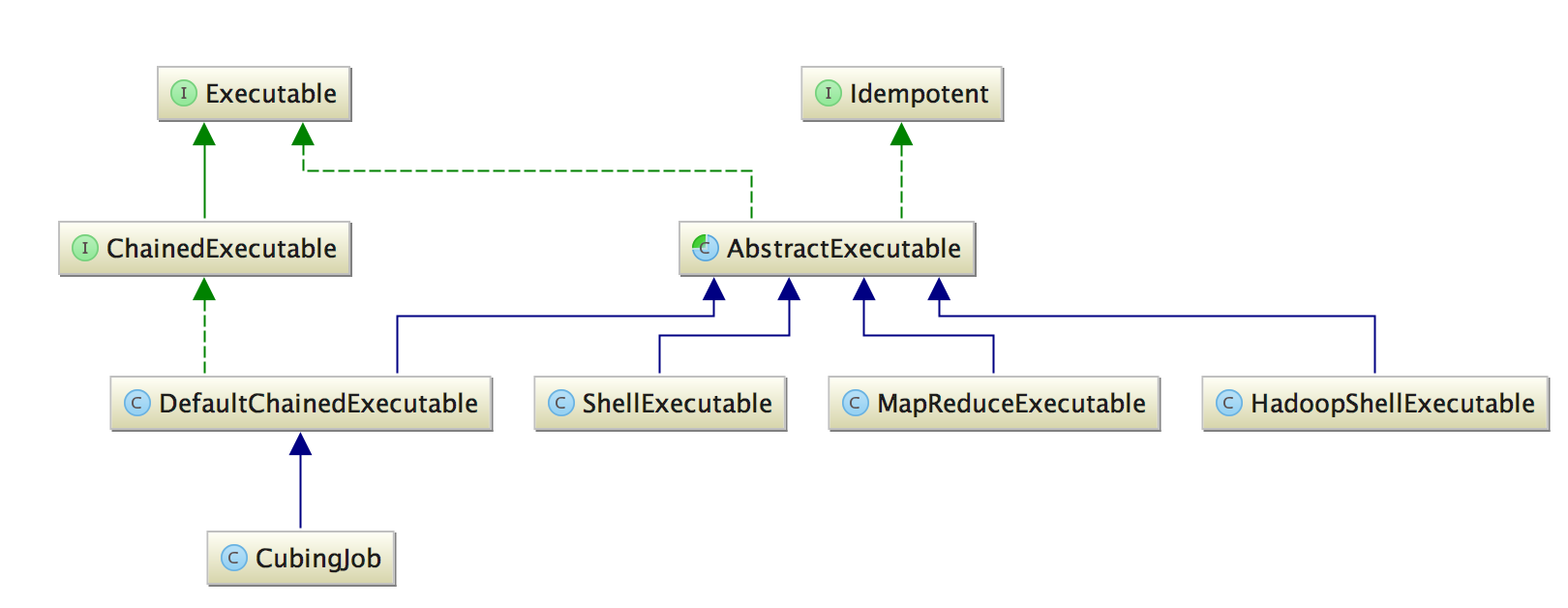 在Kylin中,每一个Job都实现了接口
在Kylin中,每一个Job都实现了接口Executable,其中核心方法是execute,每个实现类可以定义Job的具体执行逻辑。
public interface Executable {
String getId();
String getName();
//定义Job的具体执行逻辑
//参数ExecutableContext Job的上下文
//结果ExecuteResult Job的状态和输出
ExecuteResult execute(ExecutableContext executableContext) throws ExecuteException;
//获取Job运行状态
ExecutableState getStatus();
Output getOutput();
boolean isRunnable();
//获取Job的执行参数
Map<String, String> getParams();
}
抽象类AbstractExecutable实现了Executable接口,核心是实现了execute方法,为了清晰的定义每个Job的运行状态,AbstractExecutable将execute方法细化为onExecuteStart,doWork,onExecuteError,onExecuteFinished等阶段。其中execute方法修饰符为final,onExecuteStart,onExecuteError,onExecuteFinished方法修饰符为protected,doWork方法修饰符为protected abstract,用于子类根据自己的具体逻辑重写此方法。
了解设计模式的小伙伴应该已经看出Kylin Job的表达使用了模板方法设计模式,抽象类AbstractExecutable的 execute方法定义了所有Job的执行逻辑的骨架,具体的Job类根据具体逻辑重写doWork等方法。
execute方法的关键代码如下:
public final ExecuteResult execute(ExecutableContext executableContext) throws ExecuteException {
//Job的状态从Ready 变为 Running
onExecuteStart(executableContext);
...
//不同的Job在这里实现具体逻辑
result = doWork(executableContext);
...
if (exception != null) {
//Job的状态从Ready 变为 Error
onExecuteError(exception, executableContext);
}
//Job的状态从Ready 变为 Succeed or Error or Discard
onExecuteFinished(result, executableContext);
}
AbstractExecutable的具体直接实现类主要有ShellExecutable,HadoopShellExecutable,MapReduceExecutable,主要是根据自身的具体逻辑重写了doWork方法。
ShellExecutable主要用来执行Shell 命令可以直接执行的Job,像计算Hive表行数等Job。HadoopShellExecutable主要用来执行依赖Hadoop环境且用Shell执行的Job,像建字典,建立HBase表,Bulkload HFile等Job。MapReduceExecutable主要用来执行MapReduce类型的Job,像计算列基数,计算Cuboid, 生成HFile等Job。
ChainedExecutable
前面提到是CubingJob将构建cube的每一步job串了起来,其实CubingJob继承了DefaultChainedExecutable,DefaultChainedExecutable类继承了
AbstractExecutable类并实现了ChainedExecutable接口。CubingJob 主要是为Job关联了cube和segment的相关信息,串连所有Job的任务都是DefaultChainedExecutable类实现的。
public interface ChainedExecutable extends Executable {
//获取所有子Job
List<? extends AbstractExecutable> getTasks();
//添加子Job
void addTask(AbstractExecutable executable);
}
之前提到在生成Job的时候,CubingJob通过addTask方法将所有子Job串连了起来。那么DefaultChainedExecutable到底是如何串连起所有子Job呢?关键在其重写的doWork方法里:
protected ExecuteResult doWork(ExecutableContext context) throws ExecuteException {
List<? extends Executable> executables = getTasks();//获取所有子Job
for (int i = 0; i < executables.size(); ++i) {
Executable subTask = executables.get(i);
ExecutableState state = subTask.getStatus();
if (state == ExecutableState.RUNNING) {
//子Job正在执行,等待它完成
break;
} else if (state == ExecutableState.ERROR) {
//子Job执行失败,抛出异常
}
if (subTask.isRunnable()) {
//每个Job在初始化后是Ready状态,所以isRunnable()是True,当子Job是Ready状态时,就开始执行。
return subTask.execute(context);
}
}
return new ExecuteResult(ExecuteResult.State.SUCCEED, null);
}
DefaultChainedExecutable 也重写了onExecuteFinished方法,来根据所有子Job的状态更新整个Job的最终状态。
至此,我们知道了1个Job是如何表示和生成的,也知道了构建segment的多个Job是如何串起来的,下面我们来看下Job是如何被调度的。
单机调度
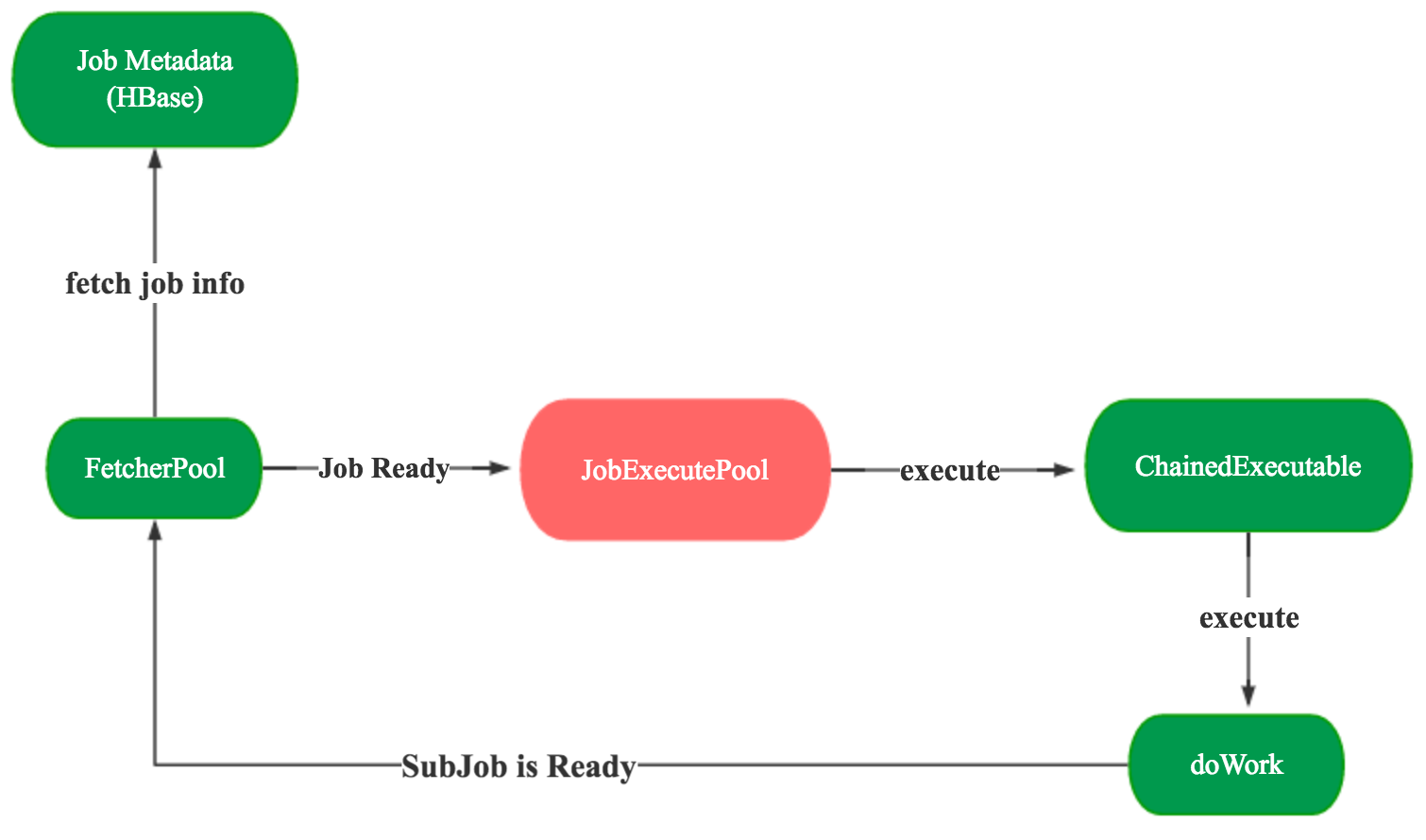
首先我们来看下Kylin默认的单机版调度DefaultScheduler是如何实现的,其核心逻辑是十分简单的,有两个线程池,一个线程池用来抓取所有Job的状态信息,一个线程池来执行具体的Job。其本质上就是一个生产者,消费者模型。
首先ScheduledExecutorService线程池会定时抓取所有Job的状态信息,如果Job的状态是Ready,那么说明该Job是可以被调度执行的,就将该Job交给JobPool线程池的执行单元JobRunner去执行,而JobRunner则调用了每个Job的execute方法。
//抓取所有Job的状态信息的线程池
ScheduledExecutorService fetcherPool = Executors.newScheduledThreadPool(1);
//默认每1分钟抓取1次Job信息
fetcherPool.scheduleAtFixedRate(fetcher, 10, ExecutableConstants.DEFAULT_SCHEDULER_INTERVAL_SECONDS, TimeUnit.SECONDS);
//抓取所有Job状态信息的执行单元
private class FetcherRunner implements Runnable {
synchronized public void run() {
//遍历所有Job
for (final String id : executableManager.getAllJobIds()) {
nReady++;
//根据jobid拿到Job信息
AbstractExecutable executable = executableManager.getJob(id);
//调度Ready 状态的 Job
jobPool.execute(new JobRunner(executable));
}
}
//执行Job的线程池
//SynchronousQueue是没有缓存空间的同步队列,将任务直接交付给可以执行任务的线程
ExecutorService jobPool = new ThreadPoolExecutor(corePoolSize, corePoolSize, Long.MAX_VALUE, TimeUnit.DAYS, new SynchronousQueue<Runnable>());
//执行Job的执行单元
private class JobRunner implements Runnable {
public void run() {
//调用Job的execute方法执行Job的具体逻辑
executable.execute(context);
}
在分布式应用中,单点迟早都会成为性能瓶颈,也无法保证高可用,高可靠,易扩展,那么Kylin1.6.1版本之前的Job Server无法分布式化的原因是什么呢?是因为有单机锁。
单机锁
默认的单机锁实现类是ZookeeperJobLock。
锁什么?
锁整个Job Server节点,所以同一份元数据下只可以有1个Job Server运行。
如何锁?
利用zookeeper的临时有序节点。
谁持有锁?
整个Job Server节点持有锁。
何时加锁?
Job Server进程启动时加锁。
何时释放锁?
Job Server进程退出时释放锁。
分布式调度
那么如何将单机版调度变为分布式调度呢?核心思路就是将整个Job Server粒度的锁变为Segment粒度的锁,因为每个链式Job的目的都是构建1个segment,我们只需要保证构建1个segment的所有Job都在1个Job Server执行即可。
分布式调度的实现类是DistributedScheduler,分布式锁的实现类是ZookeeperDistributedJobLock。
锁什么?
锁segment。
谁持有锁?
触发构建该segment的Job Server持有锁。将持有锁的ServerName写入Zookeeper临时节点,用来标记哪个Job Server持有锁。
如何加锁?
利用zookeeper的临时节点。
何时加锁?
提交build请求时对segment进行加锁。
如何释放锁?
直接删除掉segment在Zookeeper上的临时节点。
何时释放锁?
整个Job的最终状态变为SUCCEED,ERROR 和 DISCARDED 时 释放segment的锁。
分布式调度如何实现HA
作为分布式调度,当1个JobServer挂掉时,我们当然希望其他存活的JobServer可以接管挂掉的JobServer上正在Running的Job。
这个Take over功能的实现主要是利用Zookeeepr的watch机制,每个JobServer都会监听segment锁在Zookeeper临时节点的父节点路径下所有子节点的CHILD_REMOVED事件。
当JobServer接收到CHILD_REMOVED事件后,如果该segment对应的Job状态是RUNNING且之前没有持有该segment的锁,就会对segment进行尝试加锁,加锁成功的JobServer就会继续调度该segment对应的Job。
分布式调度开发反思
- 复杂系统要开发新功能前必须要熟悉相关模块代码,理清代码逻辑关系。
- 在确立方案时,我们应该借鉴现有开源系统的类似功能实现。因为许多问题在业界早就有了很成熟的方案。
- 基本方案确立后,我们可以用简单的代码快速验证方案的可行性。
- 并发编程时我们的加锁粒度一定要尽可能小。Kylin的分布式调度在初期是对cube加锁的,因为当初1个cube只能有1个Job在同时运行,所以我就想当然对cube进行加锁,没有考虑到1个Job本质上是在构建1个segment以及之后可能会并发构建segment。
- 并发编程时加锁,释放锁的时机也是需要我们认真思考的,并且尽可能保证加锁,释放锁的逻辑紧凑,不要分散到多个类中。
- 在调用第三类库的方法实现核心功能时,我们不仅要认真阅读文档,注释,demo,也应该对其方法的核心逻辑进行确认。我开发初期就误用了Curator的API。
- 在增加新功能时,我们应该尽可能对原有代码保持较小改动。
- 对于代码正确性的保证不仅需要完备的测试,更重要的是我们代码逻辑本身简洁,清晰,可靠,正确。比如分布式调度在初期对cube加锁时,Cube Auto merge会导致失败的case在集成测试,我们的线下环境,预上线环境都没有出现,而是在上线到生产环境几天后才出现的。
总结
Kylin-1.6.1实现分布式调度后Job的状态变化大致如下:
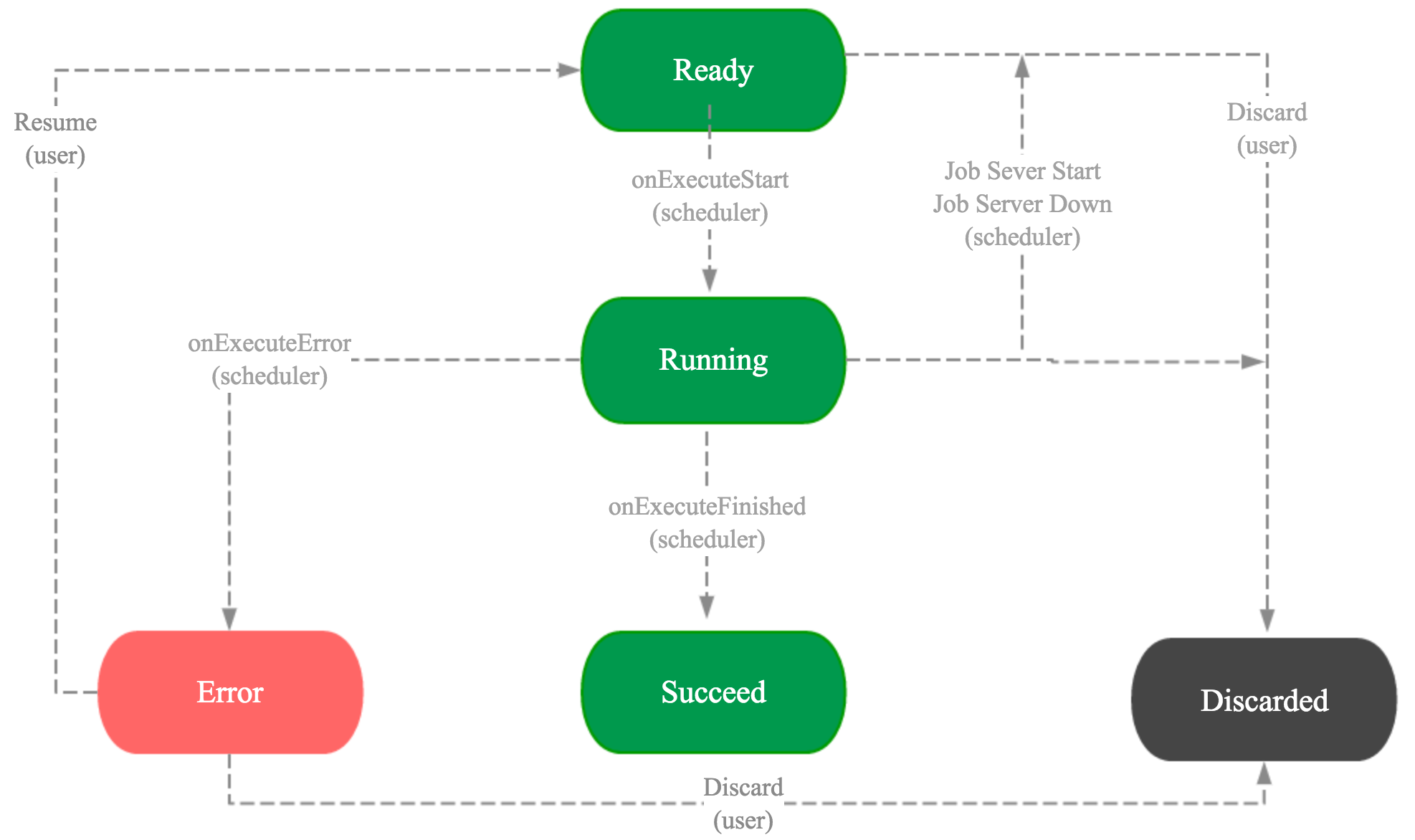
Kylin-1.6.1的Job调度示意图如下:
Kylin Job生成和调度反思
从Kylin Job生成和调度,我们可以学习什么?
模板方法,工厂模式,桥接模式等设计模式的使用。
Kylin的Job调度本质是一个生产者消费者模式,凡是符合生产者消费者模式的场景,我们都可以考虑借鉴Kylin Job调度的实现。
单机的并发上限可以到多少?
单机的并发主要受限于内存使用,而内存用于字典构建。
是否可以实现cube的优先级调度?
目前是随机的公平调度。 优先级调度当然可以实现,但是在Kylin实现优先级调度意义不大, 优先级主要靠Hadoop的资源资源调度优先级去实现。
Job 越来越多怎么办(每次在获取可以调度的Job时都需要遍历所有Job)?
临时办法:及时进行元数据清理。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
