基于Druid的Kylin存储引擎实践
作者: 康凯森
日期: 2018-08-11
分类: OLAP
本文的内容是我在8月11日Kylin Meetup上《基于Druid的Kylin存储引擎实践》的演讲稿。
《基于Druid的Kylin存储引擎实践》PDF下载: https://blog.bcmeng.com/pdf/kangkaisen-kylin-on-druid.pdf
本次分享的内容主要分为3部分,首先我会介绍下Kylin On HBase的问题,也就是我们为什么要为Kylin实现一个新的存储引擎,其次我会介绍下我们Kylin新存储引擎探索的过程,这部分会解释我们为什么选择了Druid作为Kylin的存储引擎,最后我会介绍下Kylin On Druid的整体架构,核心原理和Kylin On Druid的成果。 下面的分享中Kylin On Druid有时会简称为KOD。
Kylin 在美团点评的服务现状
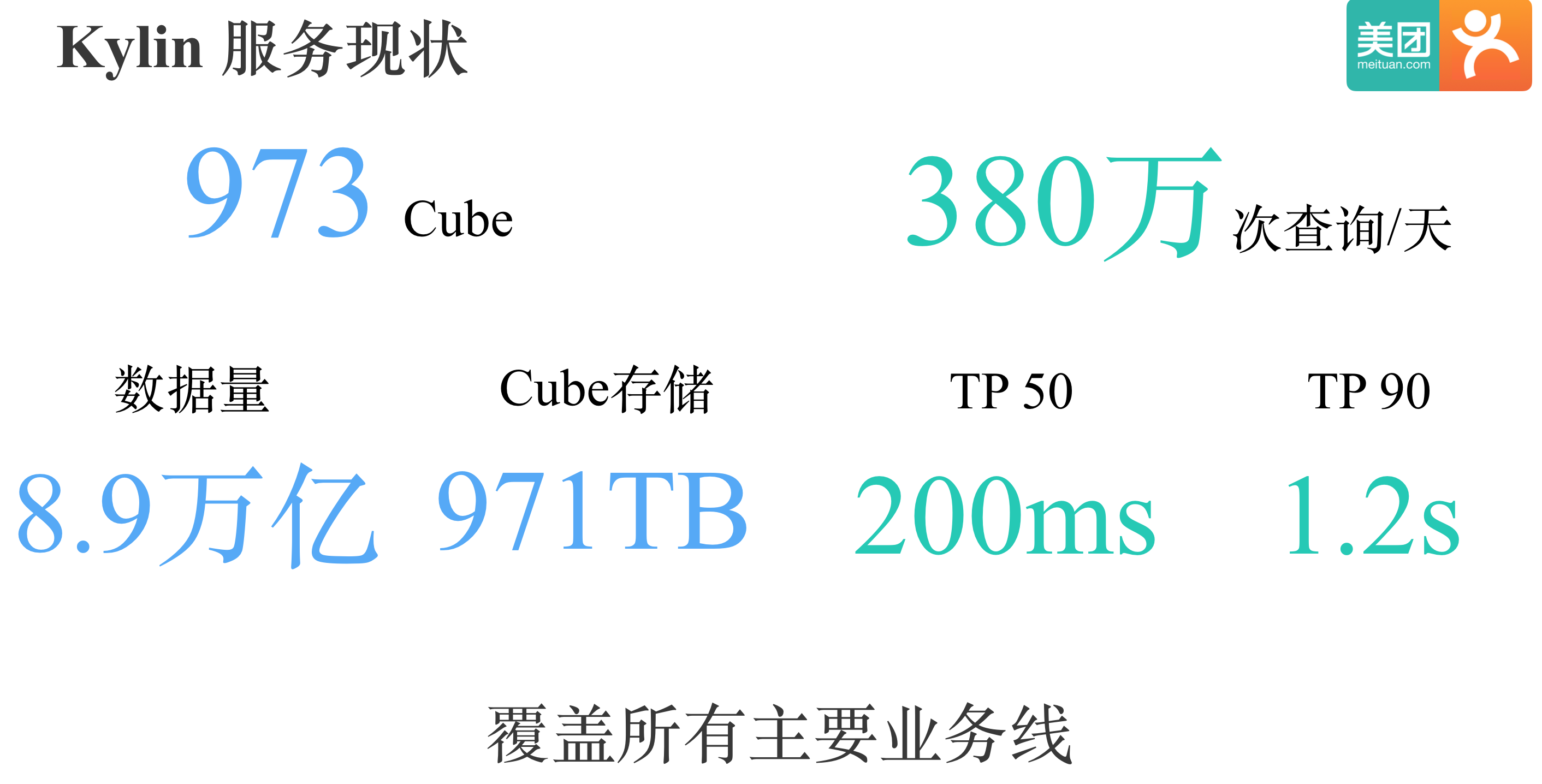
进入正式主题前,我先介绍下Kylin在美团点评的现状。目前我们线上Cube数有近1000个,Cube单副本存储近1PB;每天查询量380多万次,查询的TP50时延在200ms左右,TP90时延在1.2s左右。目前Kylin已经覆盖了美团点评所有主要业务线。
Kylin On HBase 问题
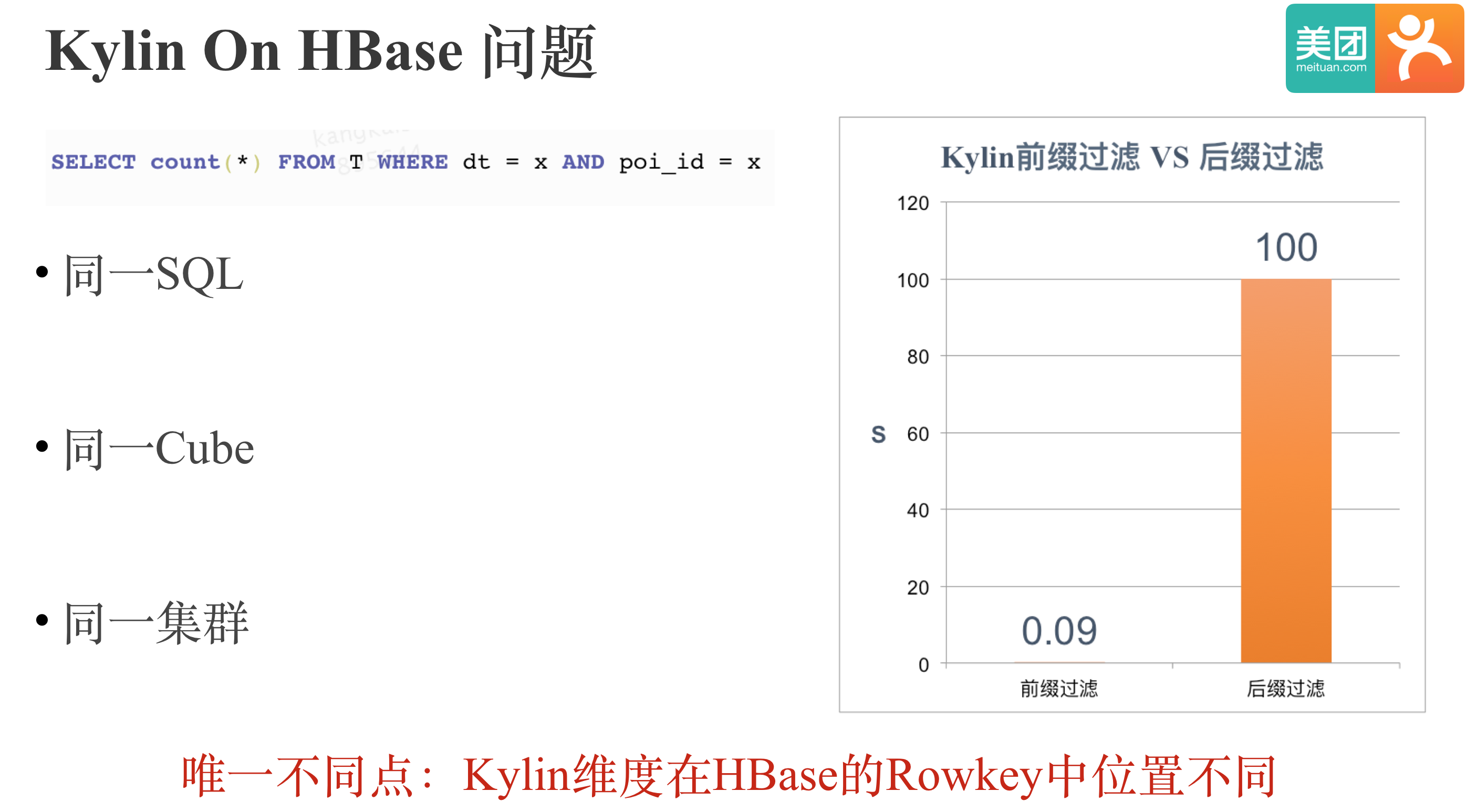
随着Kylin在我司的大规模使用和我们对Kylin的深入优化改进,我们发现了Kylin本身的一些痛点和问题,其中之一便是Kylin On HBase的性能问题。如图:我们用同一SQL在同一集群查询同一Cube,前后性能相差上千倍。 两次查询的唯一不同点就是Kylin维度在HBase的RowKey中位置不同, 耗时90ms的查询中维度dt和poi_id在RowKey前两位,耗时100多s的查询中维度dt和poi_id在RowKey后两位。
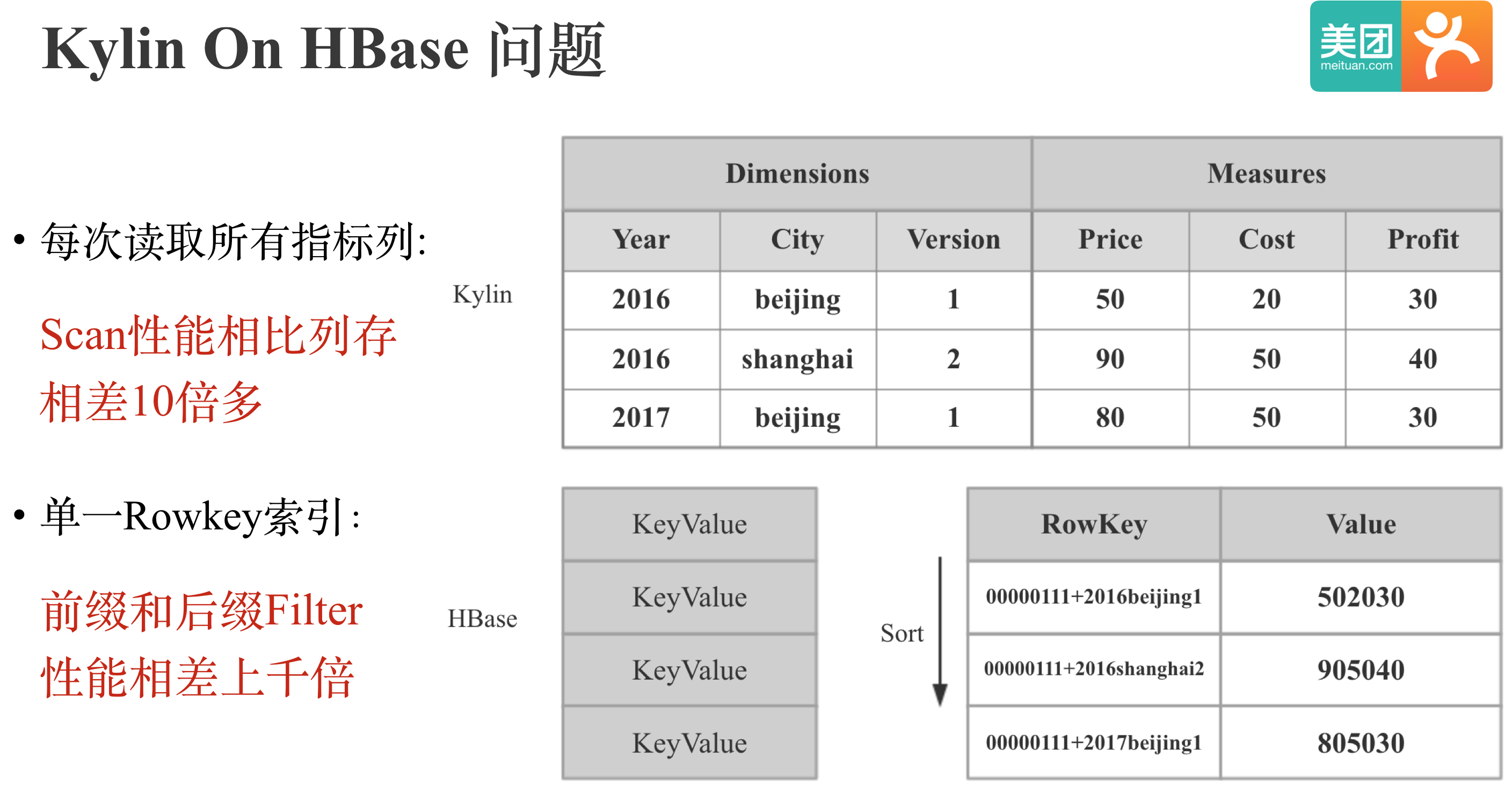
下面我们来看下Kylin On HBase中前后缀过滤性能相差巨大的原因:如图所示:Kylin中会将Cuboid+所有维度拼接成HBase的Rowkey,Kylin默认会将所有普通指标拼接成HBase一个Column Family中同一列的Value。HBase只有单一Rowkey索引,所以只有查询能够匹配Rowkey的前缀时,查询性能会十分高效,反之,查询性能会比较低下,甚至会出现全表Scan。此外,即使只需要查询一个指标,Kylin在HBase侧也需要Scan所有指标列,相比列存性能也会有较大差距。 总的来说,HBase在Kylin的查询场景下Scan和Filter效率较低下。
对于Kylin On HBase Scan和Filter效率低下的问题,我们比较自然会想到的解法是:用列存加速Scan,用索引来加速Filter。
这里我简单介绍下列存的优点,主要包含以下3点:
- 因为只需要读取必需访问的列,所以列存有高效的IO
- 因为每列数据的类型一致,格式一致,所以列存可以进行高效的编码和压缩
- 列存更容易实现向量化执行,而向量化执行相比传统的火山模型,函数调用次数更少,对CPU Cache和SIMD更加友好。 总的来说,列存相比HBase的KV模型更适合Kylin的查询场景。
所以,要解决Kylin On HBase Scan和Filter效率低下的问题, 我们就需要为Kylin增加一个列存,有高效索引的存储引擎。
Kylin 新存储引擎探索之路
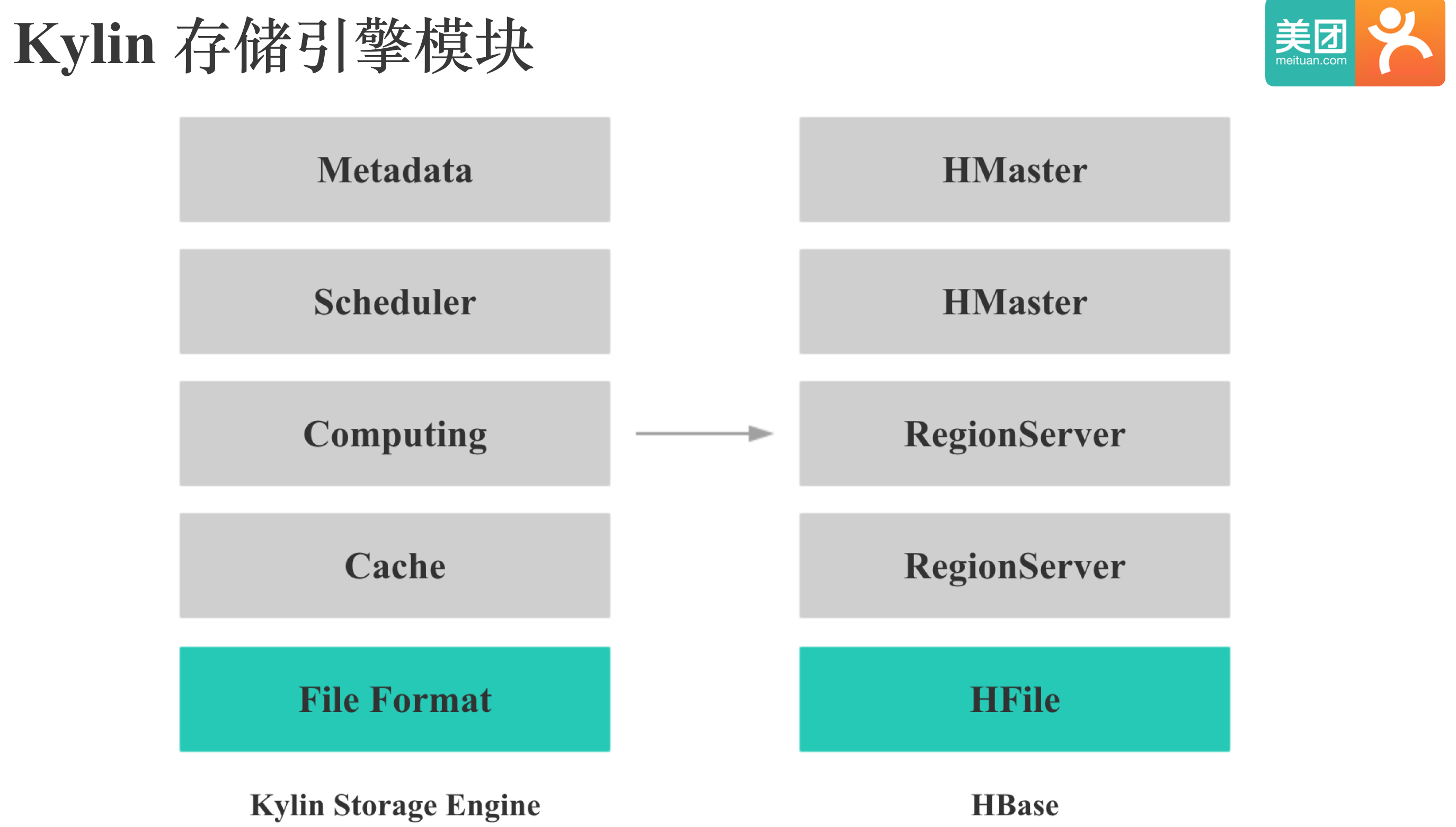
在我们为Kylin新增一个存储引擎之前,我们自然就需要先了解Kylin的存储引擎组成。主要有5部分:存储格式,Cache,计算,调度和元数据。 计算指数据的Scan,过滤,聚合等,调度指文件增删,复制和负载均衡等,这里的元数据指的是存储引擎本身的元数据。其中存储格式对查询性能影响很大,也是HBase在Kylin查询场景下的痛点,所以我们决定首先去寻找或改造一个适合Kylin的存储格式。
Kylin 新存储引擎实现思路
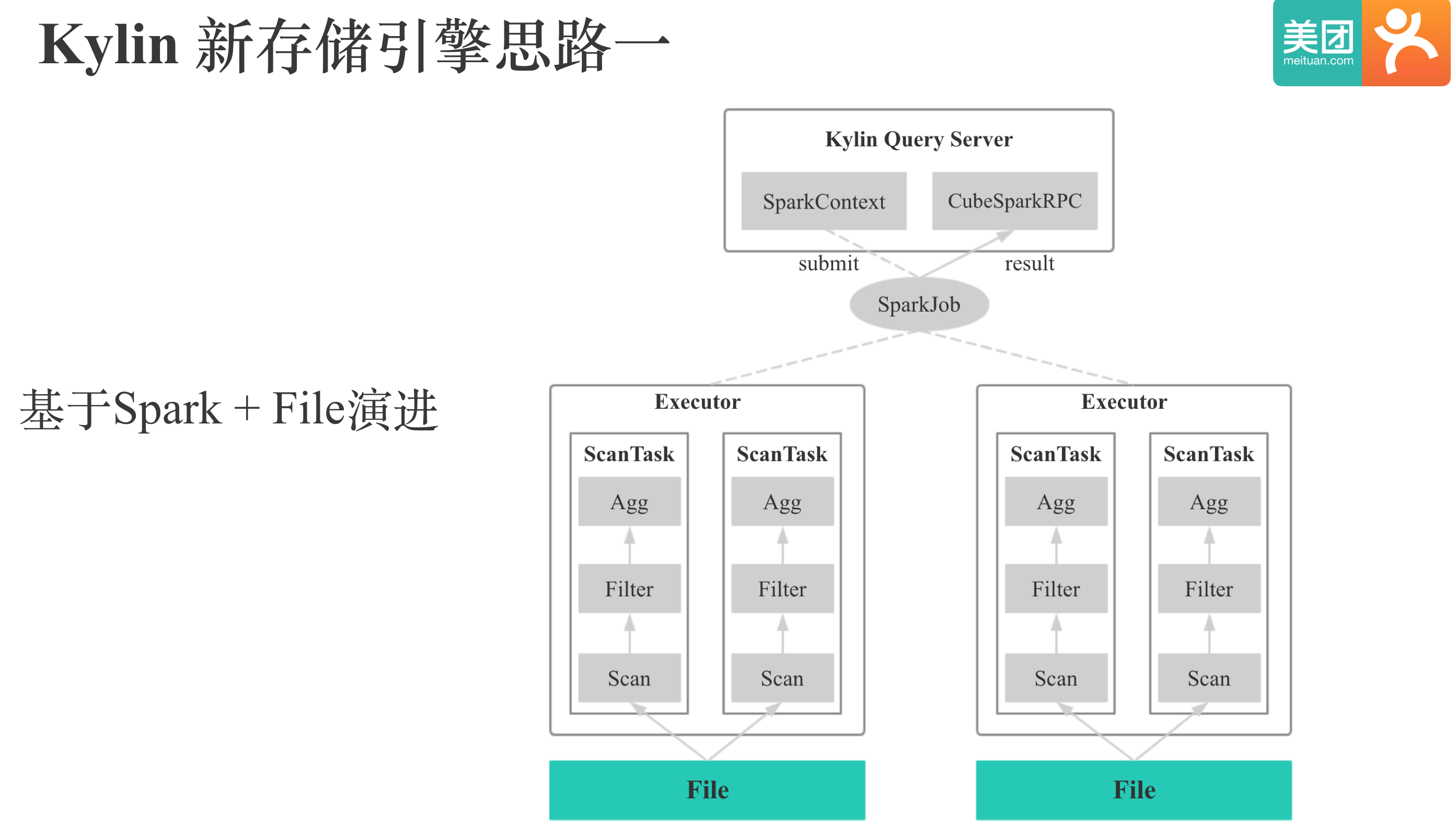
当时我们主要有两个思路,一种思路是基于Spark + 存储格式进行演进: 就是找到一个优秀的存储格式后,和Spark进行集成。大概思路是将文件Cache到本地,用Spark来实现计算和查询的调度,整个方案大体上就可以Run起来。大家对这种思路感兴趣的话,可以参考TiDB的TiSpark项目,以及Snappydata这个系统。
第二种思路就是找到或自研一个优秀的存储格式后,再参考HBase, Druid等系统,逐步完善成一个完整的存储引擎。
所以,无论哪一种思路,我们都需要首先找到或者自研一个优秀的适合Kylin的存储格式。
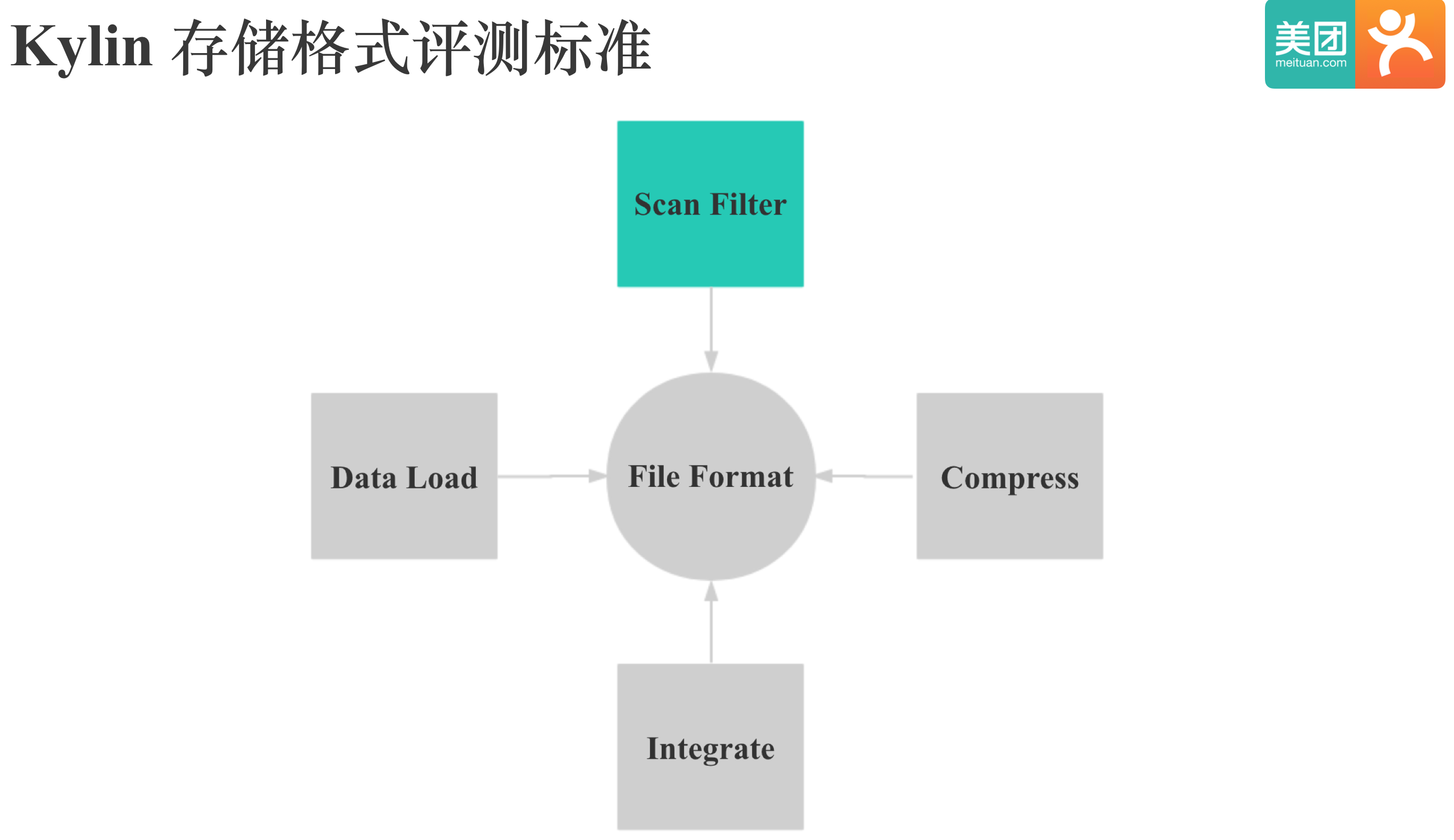
我们在调研存储格式时主要考虑Scan和Filter性能,导入性能,压缩率,集成难度这4点因素,其中重点关注Scan和Filter性能。
Kylin On Parquet POC

我们首先对Parquet进行了调研。因为Parquet是当前Hadoop生态列式文件的标准,在Hadoop生态中广泛使用。一个Parquet文件先按行逻辑上水平拆分成row groups,row groups内是列存,每一列是一个Column chunks,Column chunks进一步拆分成Page, Page是数据访问的最小单位。Parquet 可以通过min,max索引和字典实现row groups粒度的过滤,但是没有Page粒度的索引。
我们在17年5月份的时候进行了Kylin On Parquet POC,POC的结果也符合我们的理论预期:由于Parquet是列存,所以在Scan部分列时性能优于HBase,但由于存在Tuple重组,也就是列转行的开销,Scan性能会随着访问列的个数增加而降低,Scan全部列时性能不如HBase。 Filter方面,Parquet在前缀和后缀过滤上性能没有差别,但是由于当时的Parquet没有Page粒度的细粒度索引,所以前缀过滤性能明显比HBase差。
Kylin On CarbonData
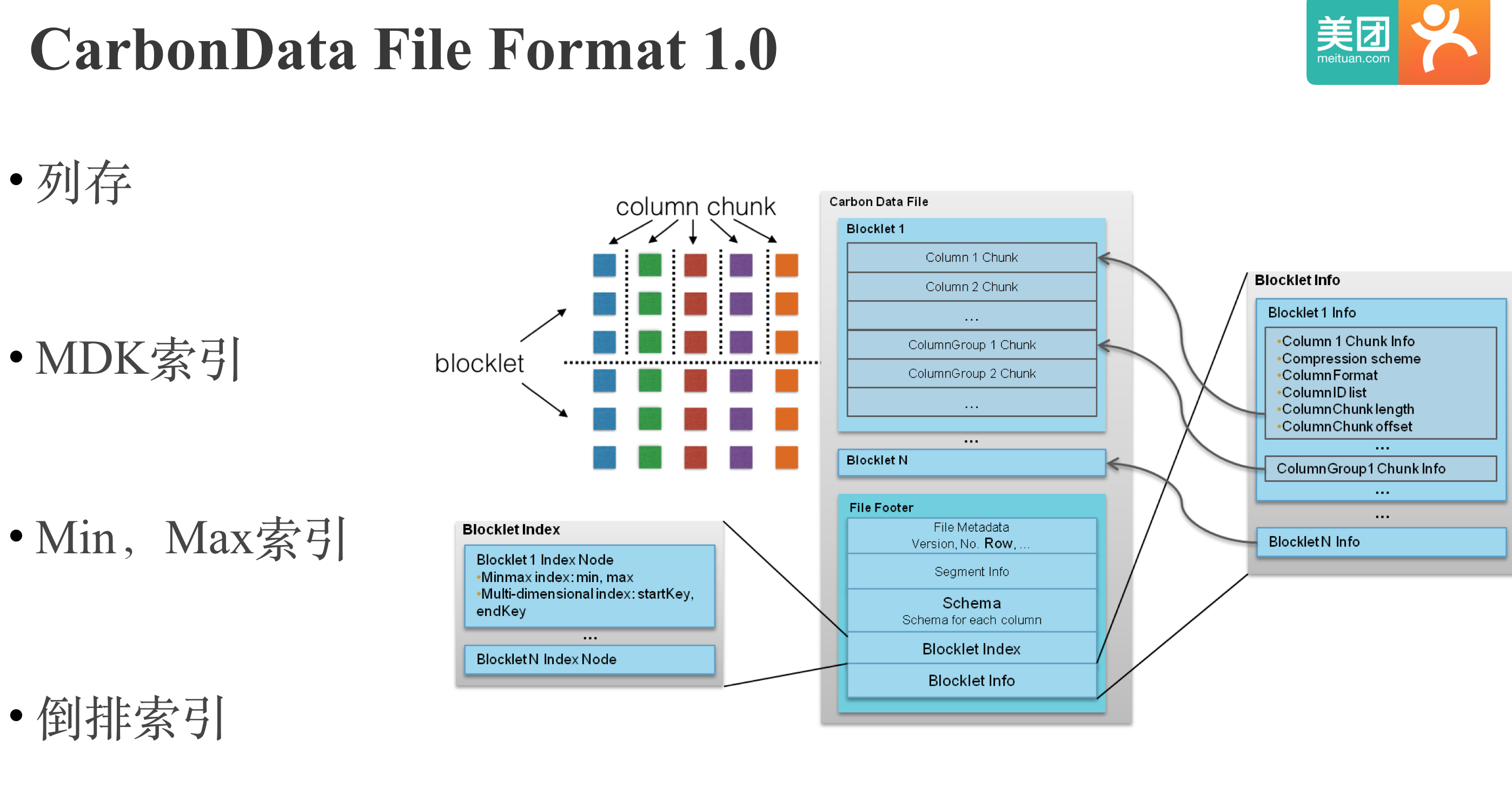
由于Parquet过滤性能不足,所以我们就Pass了Kylin On Parquet的方案。 Parquet之后,我们又调研了当时新起的华为开源的存储格式CarbonData。和Parquet类似,CarbonData首先将数据水平切分成若干个Blocklet,Blocklet内部按列存储,每列的数据叫做一个Column Chunk。和Parquet不同的是,CarbonData拥有丰富的索引:MDK索引;Min,Max索引;倒排索引。MDK索引是多维度索引,类似Kylin中的维度索引,整个文件会按照多个维度列进行排序,这样对MDK列中的维度进行前缀过滤就会很高效。
CarbonData的列存+丰富索引的设计的确是我们所期望的,不过CarbonData和Spark耦合较深,且当时的CarbonData没有OutputFormat,也不是很成熟,所以我们也Pass了Kylin On CarbonData的方案。
Kylin On Lucene POC
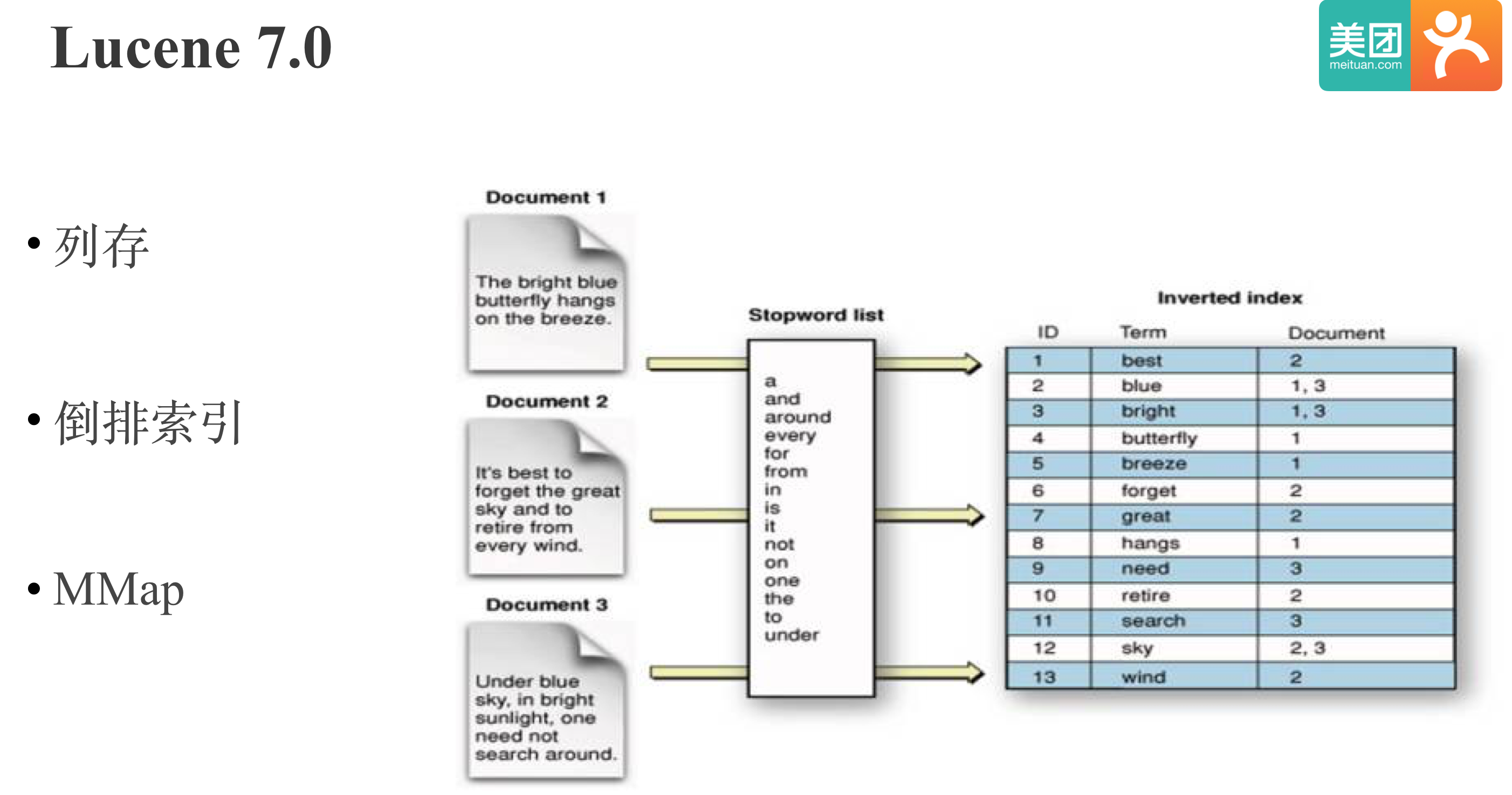
Parquet,CarbonData之后。 我们差不多同时进行了Kylin On Lucene POC 和 Kylin On Druid POC。我们先来看下Lucene, Lucene大家应该都很熟悉,是一个被广泛使用的全文搜索库,其存储格式是基于MMAP,支持倒排索引的列存。
Kylin On Lucene POC的结果和我们对倒排索引的理论认知符合:由于倒排索引是用额外的构建成本和存储成本换取查询时高效的过滤性能,所以Lucene的构建性能只有HBase的1/3,存储是HBase的4倍,但是过滤性能明显优于HBase。
Kylin On Druid POC
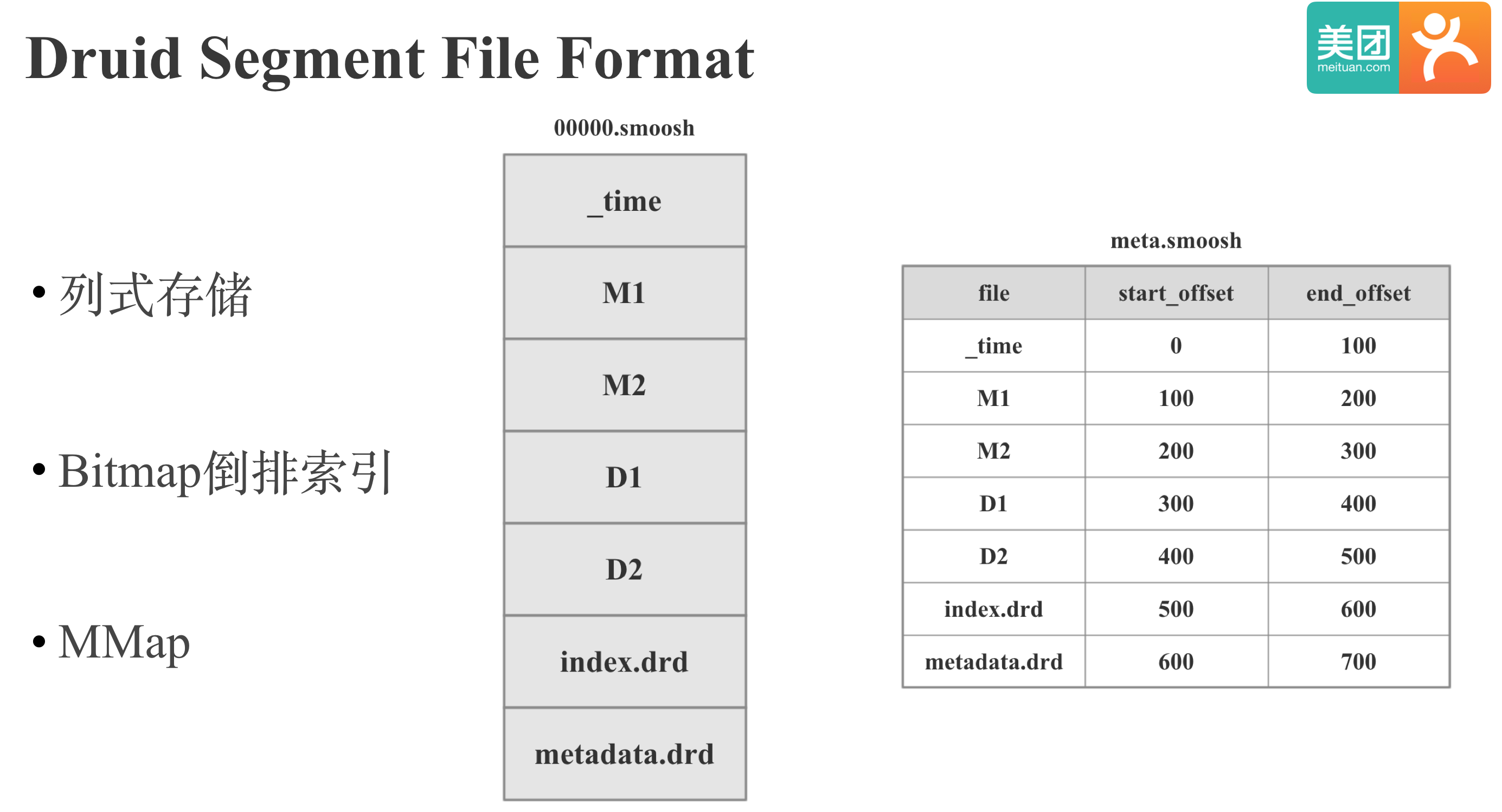
下面我们来看下Druid的存储格式。和Lucene类似,Druid的存储格式也是基于MMAP,支持倒排索引的列存,区别是Druid的倒排索引是基于Bitmap的,Lucene的倒排索引是基于倒排表的。Druid的存储格式比较简单,就是直接按列依次存储,其中的M1,M2是指标列,D1,D2指维度列.除了数据文件之外,还会有一个meta文件记录每一列的offset。我们要读取Druid文件时,就将Druid文件MMap到内存,直接根据offset读取指定偏移量的数据。
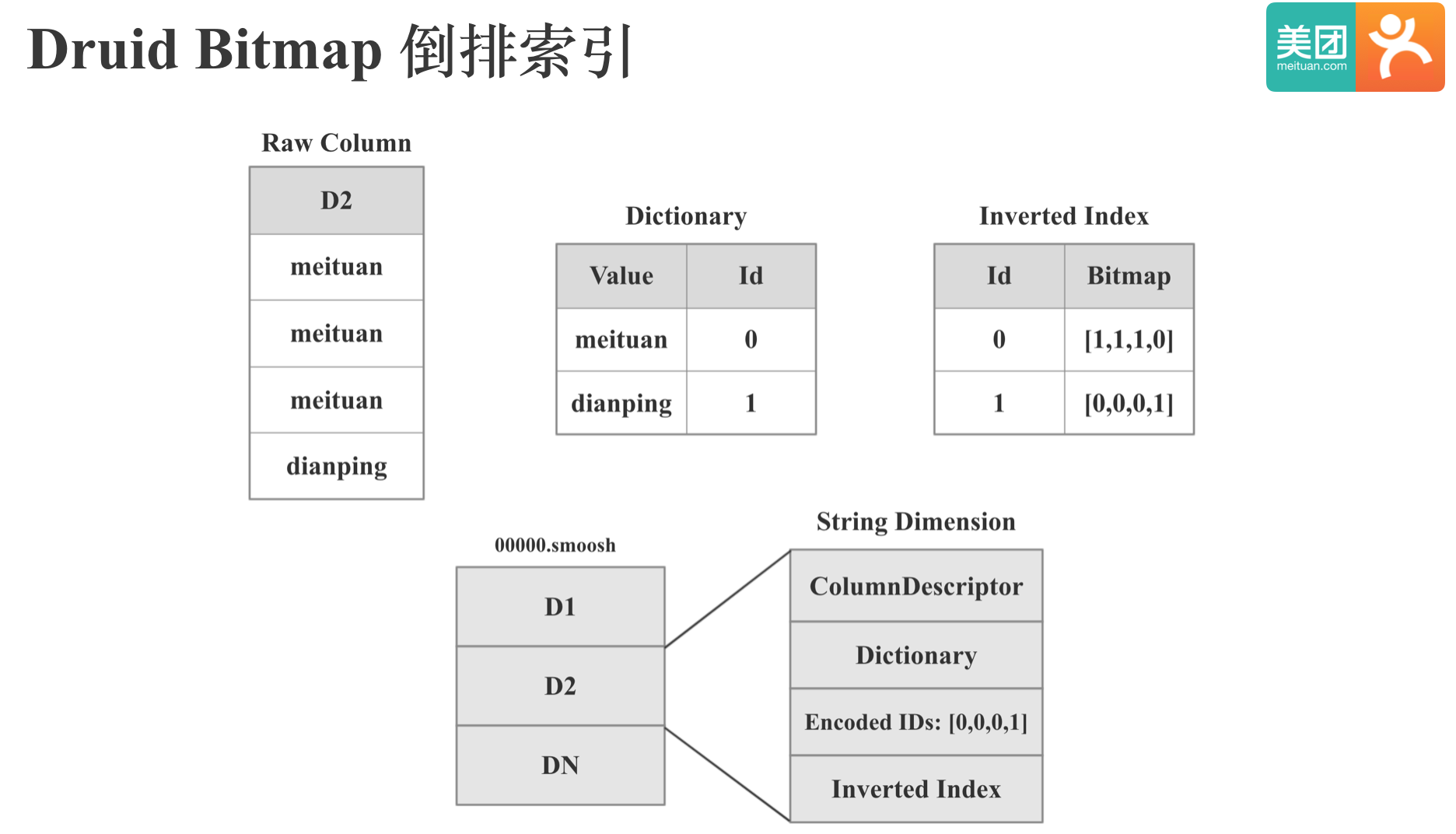
图中上半部分是Druid Bitmap 倒排索引的实现原理:我们有维度列D2, 共4行数据,包含meituan,dianping两个值,Druid会首先对维度列进行字典编码,图中meituan编码为0,dianping编码为1,然后Druid会基于维度值和字典构建基于Bitmap的倒排索引,倒排索引的Key是编码后的ID,Value是Bitmap,Bitmap的哪个bit位是1,就表示该值出现在哪些行。 下半部分是Druid String 维度存储的具体内容:包括列的元数据,维度字典,维度编码后的ID和倒排索引。
图中是Kylin On Druid POC的结果,我们可以看到Druid的过滤性能明显优于HBase,Scan性能和Parquet类似,在部分列时也明显优于HBase。 构建和存储的话,和Lucene类似,会比HBase差一点。
Why Kylin On Druid
在我们对Parquet,CarbonData,Lucene,Druid的存储格式和POC情况有了基本了解之后,我们来看下为什么我们当时做出了Kylin On Druid的方案:
- Parquet的索引粒度较粗,过滤性能不足;
- CarbonData与Spark 耦合较深,集成难度较大;
- Lucene 和 Druid相比,存储膨胀率较高,还有比较重要的一点是,Druid不仅仅是一个存储格式,也可以作为Kylin完整的存储引擎。
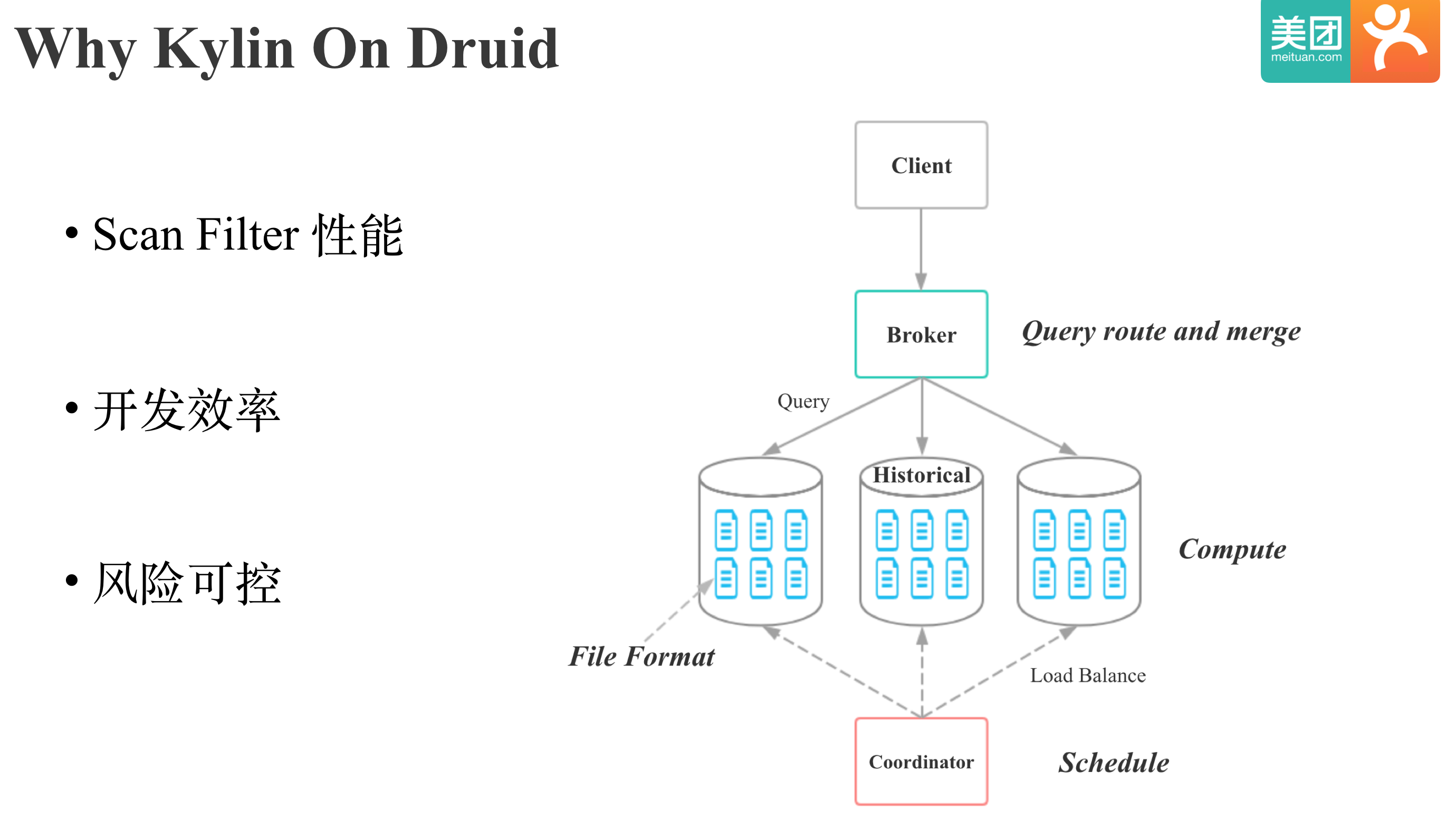
我们再来看下我们选择Kylin On Druid的原因:
- 首先是Druid Scan,Filter性能很好
- 其次是Druid不仅仅是一个存储格式,而是可以作为一个完整的Kylin存储引擎, 比如Druid Historical节点负责Segment的Cache和 计算,Druid Coordinator节点负责Segment的增删,副本和负载均衡。这样我们就不需要基于存储格式再去演进出一个存储引擎,我们整个项目的工期会大幅缩短。
- 最后,Kylin和Druid本身就是我们维护的系统,项目即使失败,我们的付出也会有收获。
Kylin On Druid
OK,前半部分主要介绍了Kylin On Druid的大背景,回答了Why Kylin On Druid。 下面我们来看下How Kylin On Druid。
Kylin 可插拔架构
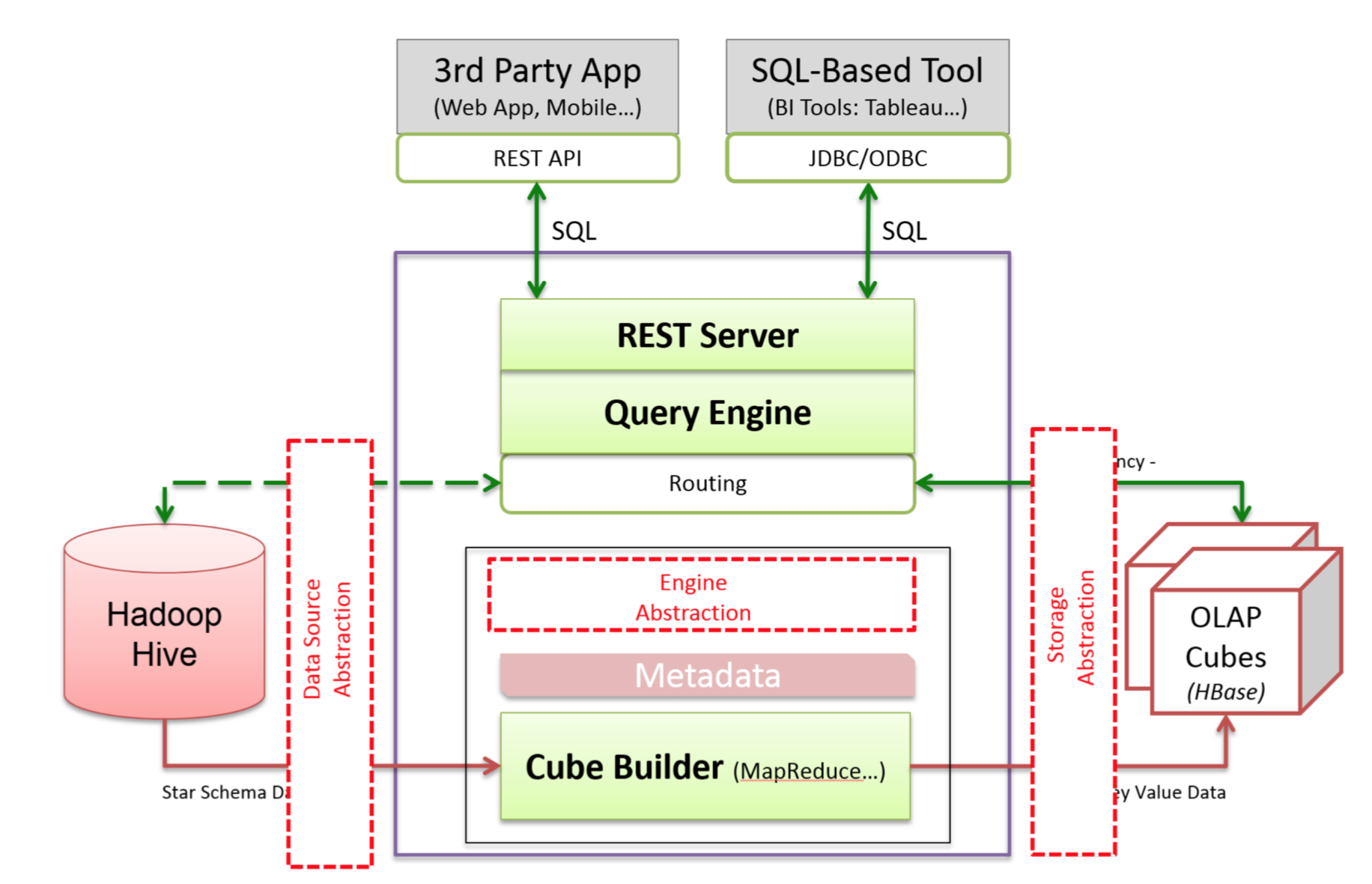
在介绍Kylin On Druid之前,我们先来看下Kylin的可插拔架构。Kylin的可插拔架构对数据源,计算引擎, 存储引擎都有抽象,理论这3个部分都是可以替换的。目前数据源已经支持Hive,Kafka;计算引擎支持Spark,MR; 但是存储引擎只有HBase。 所谓的Kylin On Druid就是在Kylin的可插拔架构中用Druid替换掉HBase。
Kylin On Druid 架构
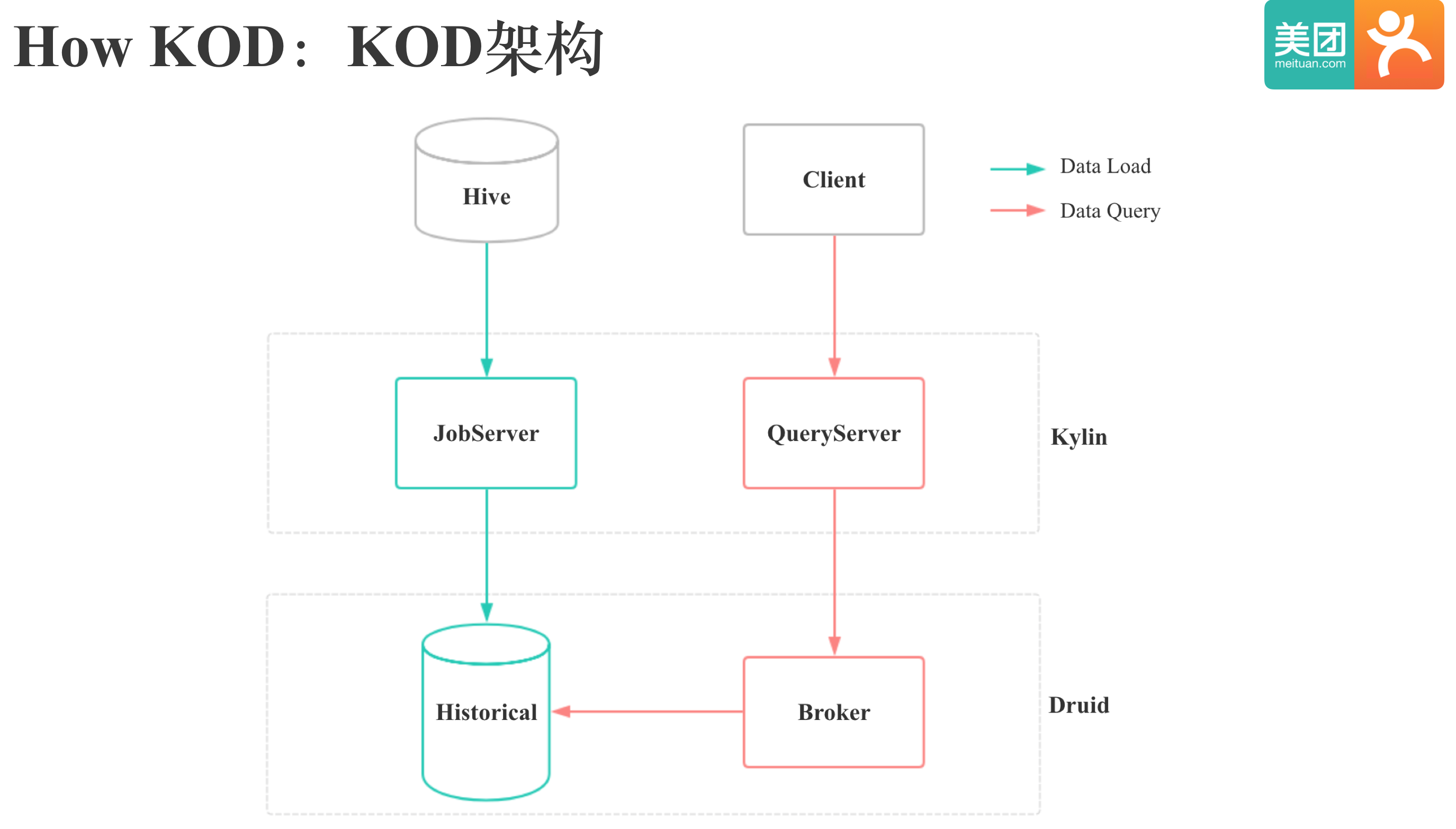
图中是Kylin On Druid 简化后的架构图,分为数据导入和数据查询两条线。数据导入时,Kylin的JobServer会将Hive中的数据导入到Druid的Historical节点中;数据查询时,Kylin的Queryserver会通过Druid的Broker节点向Druid发起查询。
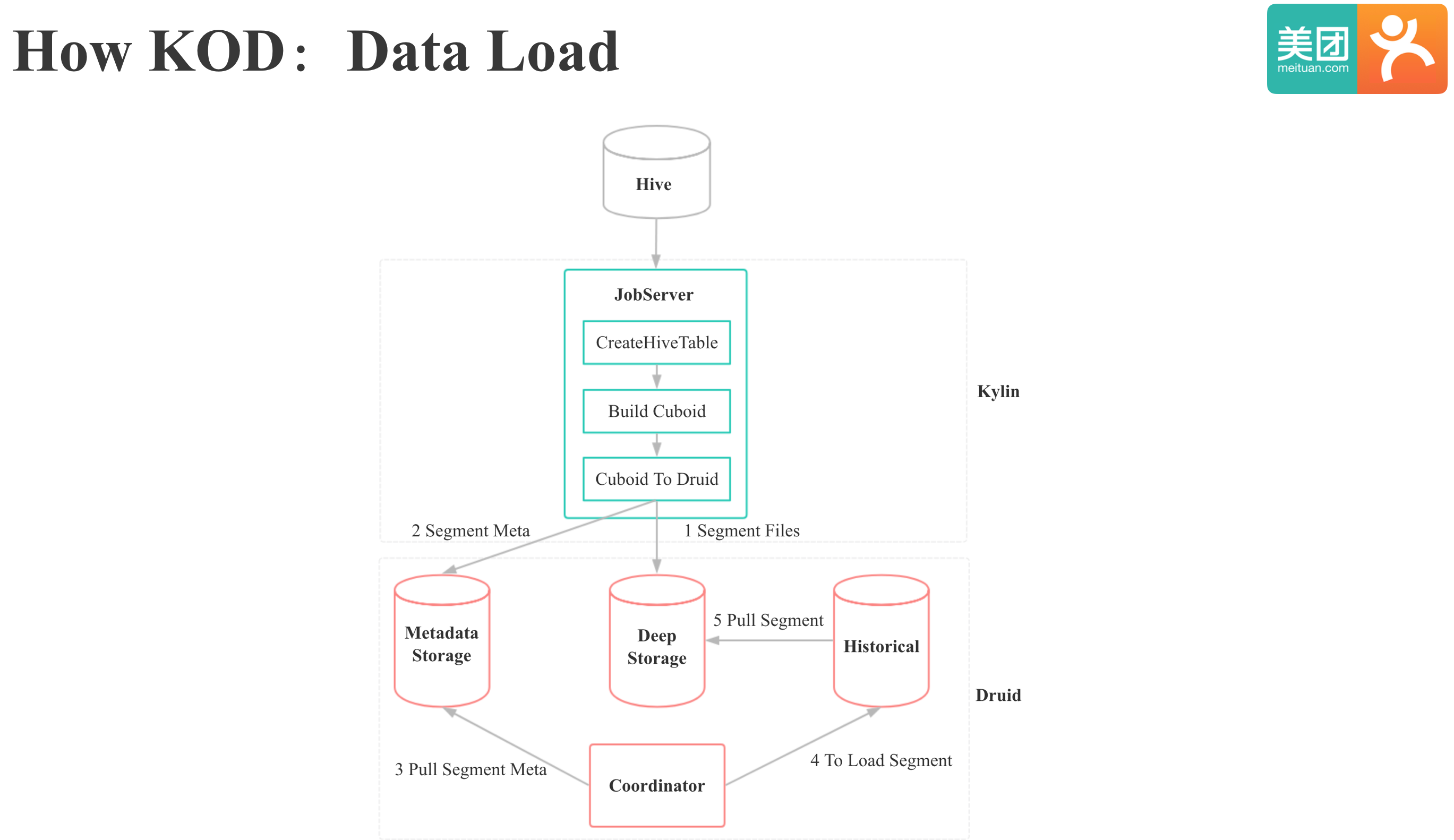
下面我们来详细看下KOD数据导入和数据查询的过程,我们首先来看下数据导入过程:
- 和HBase一样,首先需要计算出Cuboid
- 生成Cuboid后,Kylin On HBase中是将Cuboid转为HBase的HFile,KOD中则是将Cuboid转为Druid Segment文件。
- 向Druid的MetaData Store插入Segment元数据。下面的工作是Druid内部的流程:
- Coordinator定期从MetaData Store Pull Segment元数据,发现有新Segment生成时,就会通知Historical节点Load Segment
- Historical节点收到Load Segment通知后,就会去HDFS上下载Segment文件,然后MMap到内存,至此整个数据导入过程完成。
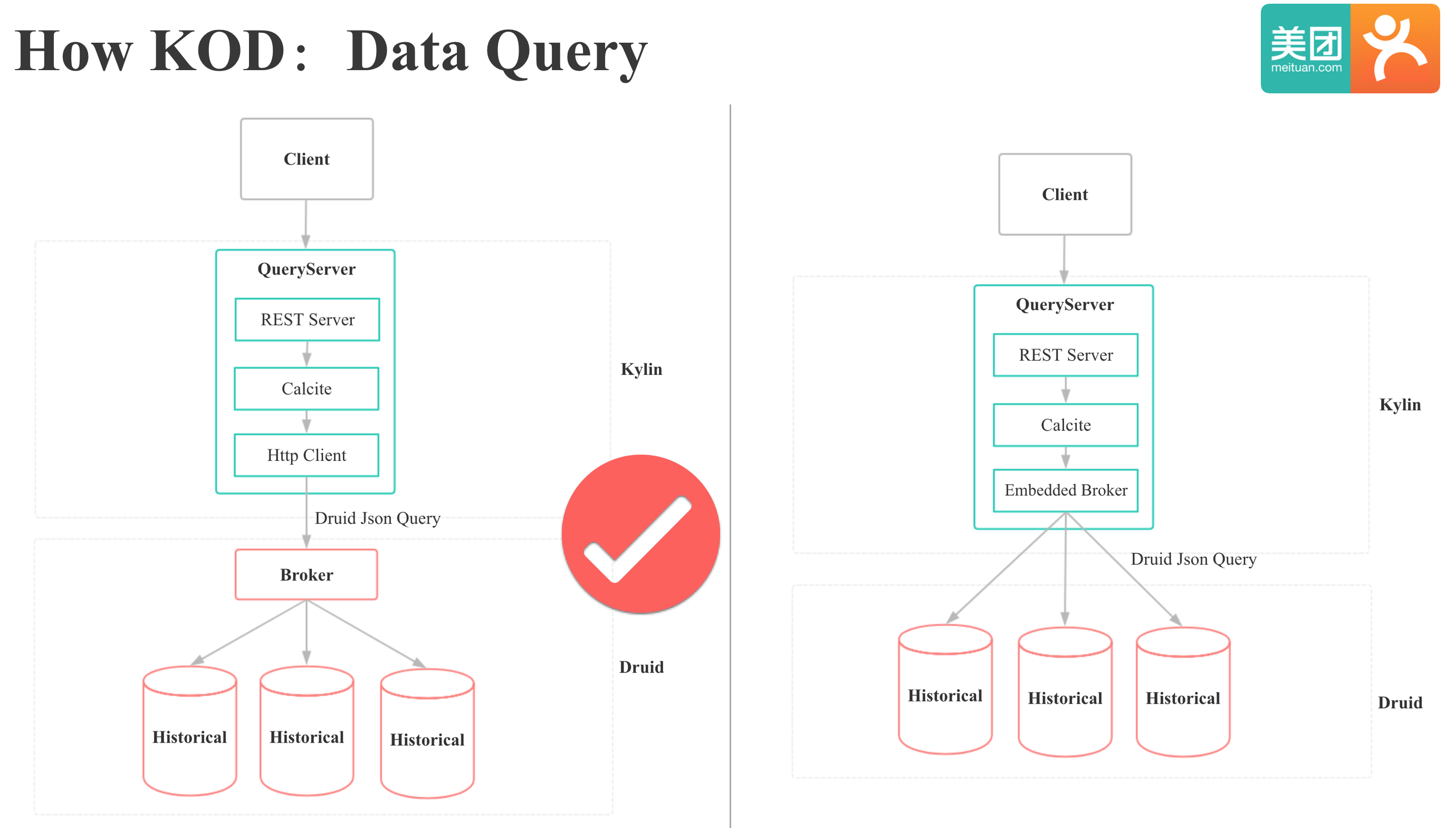
KOD的数据查询过程,Kylin和Druid如何交互我们可以有两种方案。 一种是通过直接访问Broker的方式和Druid集成,一种是通过直接访问Druid Historical节点的方式和Druid集成。 第一种方式我们只需要将Kylin的SQL翻译成Druid的json,通过Http向Druid的Broker发起查询。 第二种方式我们就需要在kylin中实现Druid Broker的功能,好处是性能会比第一种好,因为少一层网络传输,坏处是Kylin和Druid的依赖冲突会更严重,实现较复杂。本着侵入性小和简单可用的原则,我们选择了第一种方案。
Kylin On Druid 实现细节
在了解了KOD的架构和整个数据导入,数据查询过程后,我们再具体看下我们做了哪些方面的工作:
- Kylin和Druid的Schema映射
- Cube 构建侧适配
- Cube 查询侧适配
- 运维工具适配
其实这4方面的工作也是我们为Kylin增加一个存储引擎必须要做的工作。
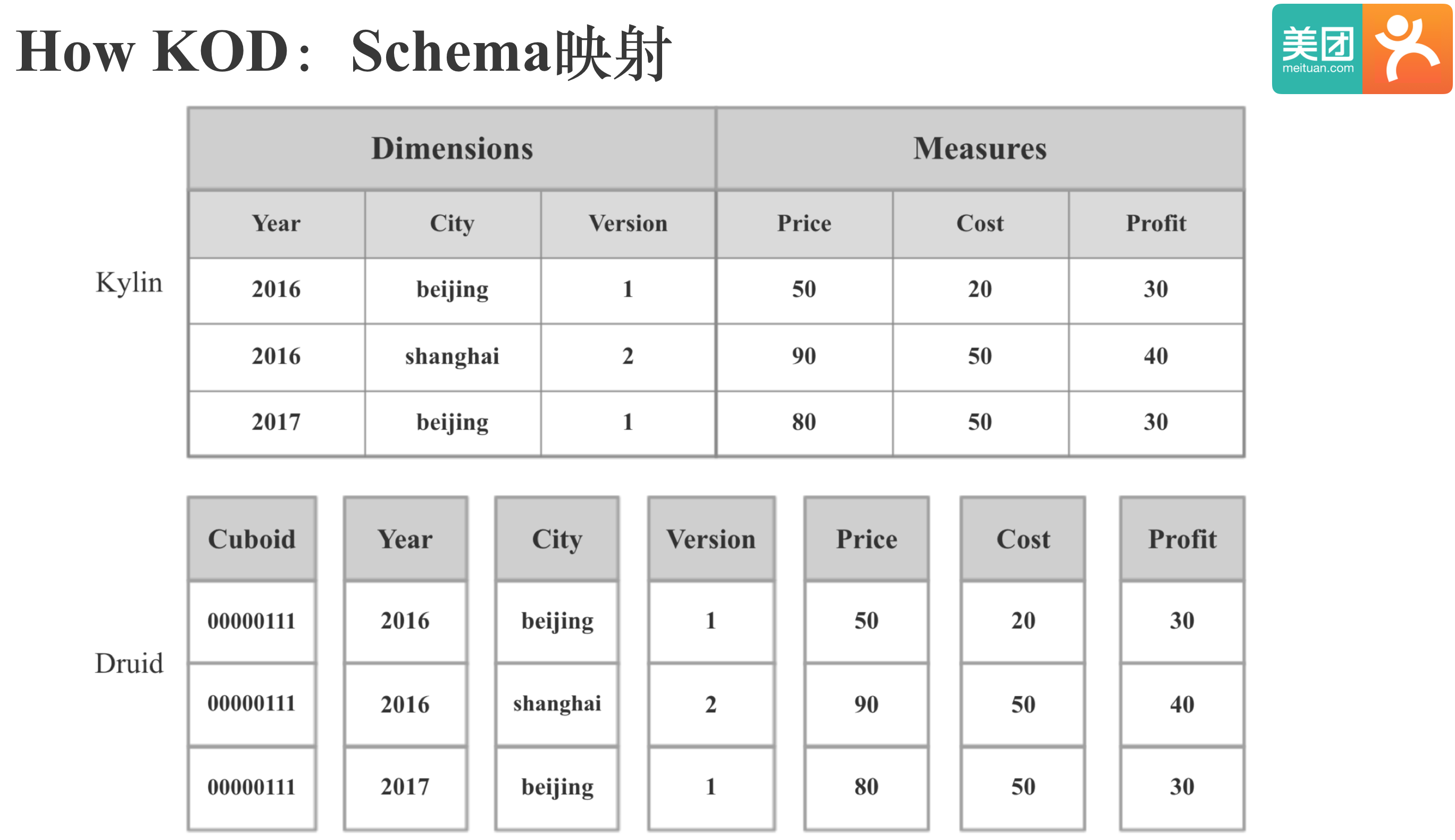
Kylin和Druid的Schema映射是这样的:Kylin的Cube对应Druid中的DataSource,Kylin的Segment对应Druid中的Segment,维度对维度,指标对指标,需要额外增加一个Cuboid维度列,Druid中没有的指标需要在Druid中进行扩展。
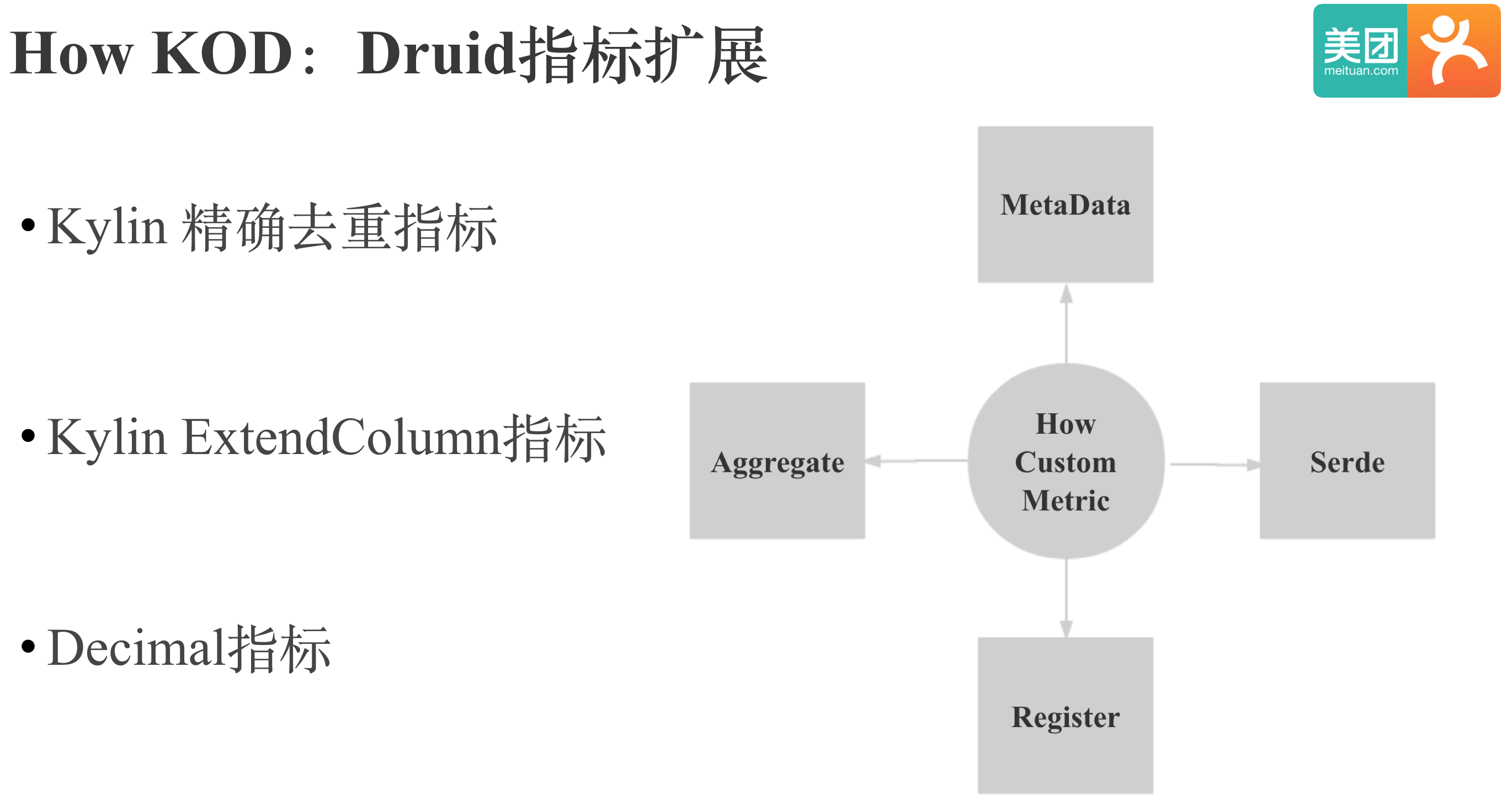
我们目前在Druid中增加了Kylin的精确去重指标,Kylin的ExtendColumn指标和Decimal指标。无论是Druid还是Kylin,我们新增一种聚合指标所要做的事情都是类似的,区别只是具体的接口和实现方式不同。我们自定义一种聚合指标要做这些事情:
- 定义指标的元数据:指标的名称参数,返回类型,核心数据结构;
- 定义指标的聚合方式;
- 定义指标序列化和反序列化的方式;
- 注册指标,让系统发现新指标。

Cube构建侧适配除了之前提到的将Cuboid 转为 Druid Segment和Load Segemnt这一步,KOD中为了支持Druid层的业务隔离,还增加了Update Druid Tier这一步,允许用户将不同的Cube存储到不同的Tier。在Druid Segment生成和Load这两步,都进行了一定的优化。 生成Druid Segment时,由于需要生成倒排索引,所以相比生成HBase的HFILE,就需要更多的内存,所以这一步进行了较多内存升的优化。 在Druid Load Segment这一步,初期发现多个Segment 并发导入时,Druid Load Segment会很慢。 经过排查发现,主要是Druid 0.10.0版本有bug,默认的并发度配置不生效,所以整个Load是串行,后来是通过升级到Druid 0.11,并将并发度设置为磁盘数的2倍解决的,因为Druid Load Segment的耗时99.9% 都是在从HDFS下载Segment上。
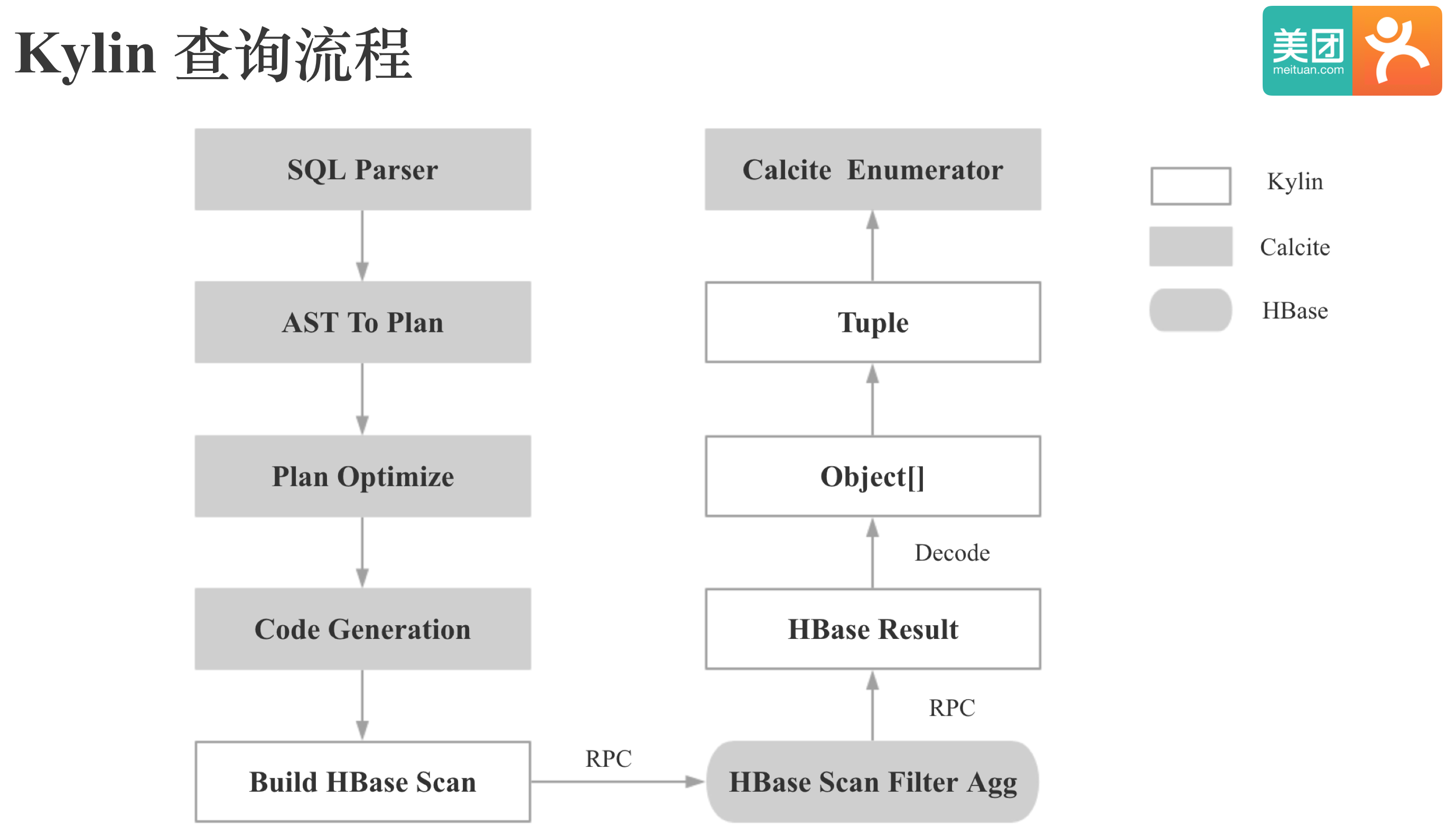
在介绍KOD对Cube查询侧的适配之前,我们先简单看下Kylin的查询流程。Kylin的SQL解析,逻辑计划的生成和优化都是通过Calcite实现的,Kylin会根据Calcite生成的查询计划生成HBase的Scan请求,HBase端经过Scan,Filter,Agg后会一次性将结果返回给Kylin的QueryServer,QueryServer会将HBase返回的结果反序列化,对维度根据字典进行解码生成Obejct数组,再将Obejct数组转为Tuple,Tuple和Obejct数组的主要区别是Tuple有了类型信息,最后Tuple会交给Calcite的Enumerator进行最终计算。
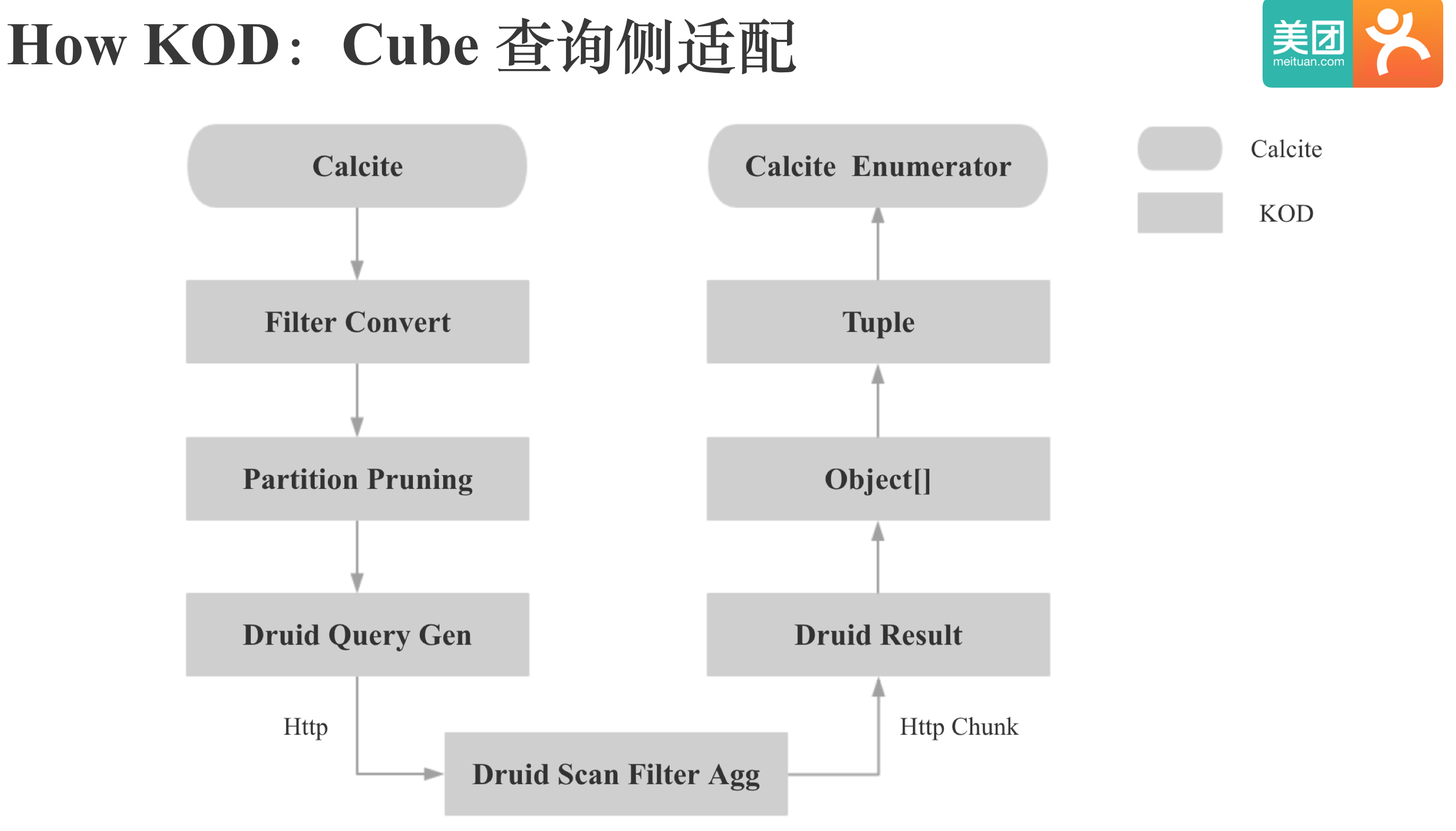
下面我们来看下KOD对Cube查询侧的适配,我们拿到Calcite生成的查询计划后,为了实现谓词下推,会首先将Kylin的Filter转为Druid的Filter;其次会进行分区裁剪,避免访问不必要的Druid Segment;然后会根据查询的Cube,维度,指标,Filter等生成Druid的查询Json,通过Http向Druid发起查询,Druid端经过Scan,Filter,Agg后会按照Http Chunk的方式Pipline地将查询结果返回给Kylin的QueryServer,下来的过程基本和HBase类似,需要注意的是,由于我们本身在Druid中存储的就是原始值,所以查询就不需要加载字典进行维度的解码。
最后我们来看下运维工具适配方面的工作,主要包括:
- Cube迁移工具
- Storage Cleanup工具
- Cube Purge,Drop,Retention操作等。
这里我就不展开了,因为主要是一些实现和细节上的问题。
Kylin On Druid 成果
现在为止,我们已经清楚了KOD的整体架构和核心原理。 下面我们来看下,KOD的性能到底怎么样。 首先我们来看下SSB测试的结果,PPT中展示了我们测试的SQL样例和测试环境。 需要特别注意的是:我们在KOD和Kylin都只计算了Base Cuboid,因为如果KOD和Kylin都充分预计算,测试性能基本上没有意义,测试的目的就是为了对比KOD和Kylin的现场计算能力。
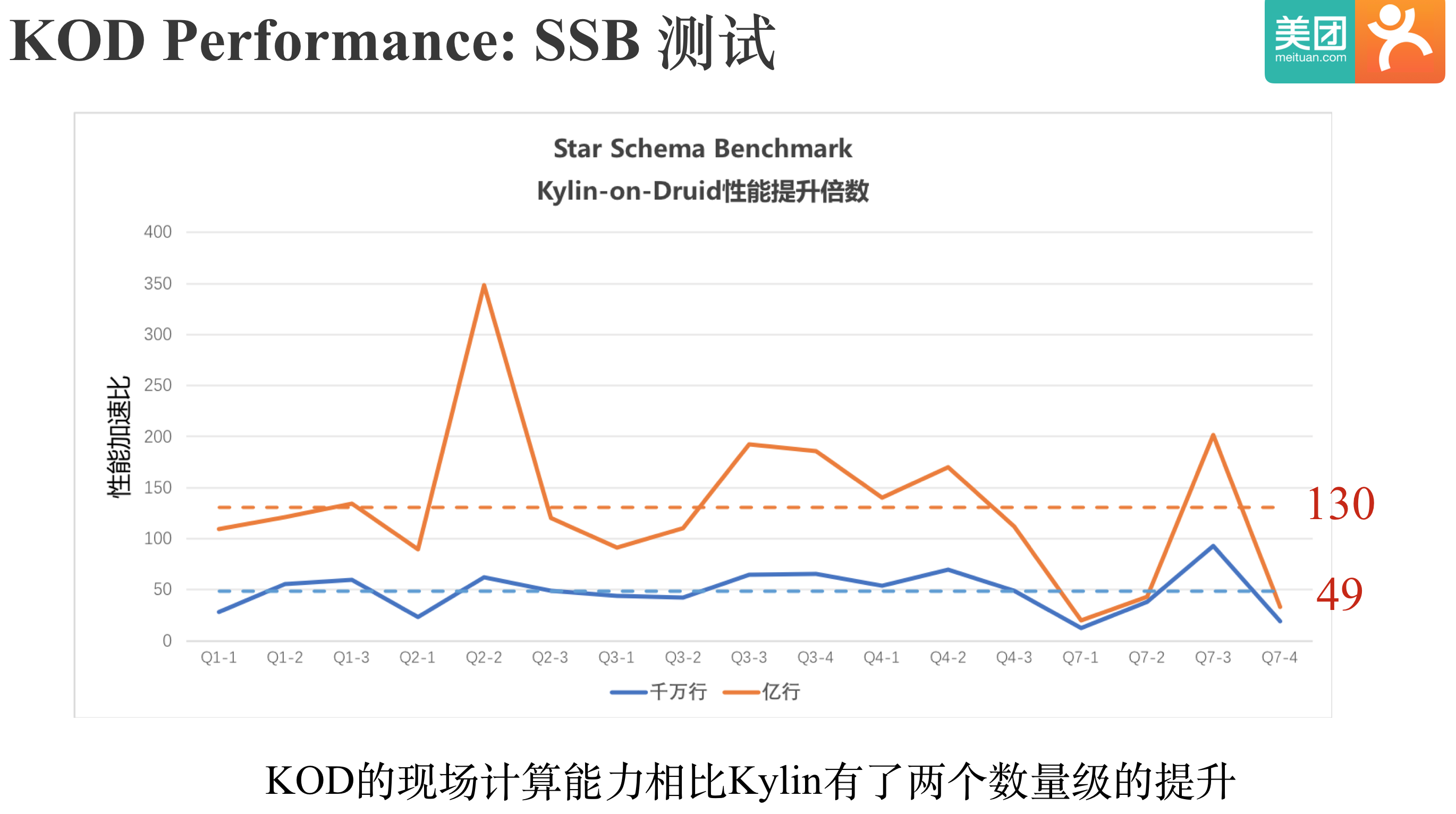
这是KOD和Kylin只计算Base Cuboid时SSB测试的结果,图中纵轴是KOD相比Kylin的加速比,千万量级时KOD的加速比是49,亿级时KOD的加速比是130。 总的来说,KOD的现场计算能力相比Kylin有了两个数量级的提升。
这张图展示的是我们KOD第一批Cube上线后,线上的真实数据。 我们可以看到,KOD相比Kylin在查询性能提升的同时,存储和计算资源也有了明显的下降

前面提到,KOD的现场计算能力相比Kylin有了两个数量级的提升,所以对于亿级及以下数据规模的数据,我们不需要再进行复杂的优化,只需要构建Base Cuboid就可以,用户的易用性有了显著提升。
Kylin On Druid 特性
在介绍完KOD的架构,核心原理,性能后,我们再总结下KOD的特性:
- 和Kylin完全兼容:SQL,Web 等
- 分区预过滤
- 查询时无需加载字典:相比Kylin On HBase 查询稳定性更高
- 存储层支持业务隔离
- 亿级及以下数据只需构建Base Cuboid
Kylin On Druid 未来规划
最后,我们看下KOD的未来规划:
1 更高效,更精简的Cube构建流程:由于Druid不依赖字典,所以KOD的Cube构建时,就不需要构建字典,和字典相关的好几步都可以省去
2 优化高基数列点查询的场景:之前的POC也体现了这一点,这种场景是倒排索引不适合的场景,却是HBase的最佳场景。 解决思路:参考linkedin的Pinot对Druid进行优化,Druid中倒排索引作为可选项,添加轻量级的类似Palo,ClickHouse的前缀索引。
3 支持在线Schema变更:目前Kylin的Schema变更也是用户使用上一大痛点,每次Schema变更都需要全量重刷数据。
本次分享从Kylin On HBase 问题出发,解释了为什么我们给Kylin新增一种存储引擎,进而介绍了我们存储引擎探索的过程,最后介绍了Kylin On Druid的架构和原理。
最后,需要注意的一点是,最新版本的Parquet已经有了PageIndex,点查询的性能显著提高,所以Kylin On paquert 或许依然值得尝试。
FAQ
Q1 为什么不直接用Druid代替Kylin?
- Kylin的预计算比Druid更加强大,Druid只能计算Base Cuboid
- Kylin支持基于预计算的精确计算,精确去重是我司强需求
- Kylin的SQL支持更加完善
- Kylin的离线导入更加完善
- Kylin对星型模型的查询支持更加友好
- Kylin支持Join
总之,用Druid代替Kylin的工作量远远大于Kylin On Druid的工作量。
Q2 为什么没有选择Kylin On Kudu?
- Kudu 并没有倒排索引或者二级索引
- Kudu 是C++实现的,我们团队的技术栈主要是Java,我们的存储团队也没有引进Kudu
Q3 为什么没有选择去优化改进HBase?
因为要将HBase的Key-Value模型改成列存的话已经不仅仅是优化改进了,需要重新设计整个系统。 可以参考 https://kudu.apache.org/faq.html#why-build-a-new-storage-engine-why-not-just-improve-apache-hbase-to-increase-its-scan-speed
Q4 Druid和Kylin的应用场景?
在我司,Kylin是主推的离线OLAP引擎,Druid是主推的实时OLAP引擎。
关于CarbonData 的 DataMap特性
CarbonData在最近的版本实现了DataMap特性: https://carbondata.apache.org/datamap-developer-guide.html
DataMap的主要目的是一份存储支持多种查询场景,实现CarbonData设计之初的愿景;核心思想是一份数据,多种索引,不同场景下的查询用不同的索引进行加速,查询时可以自动路由到相应的索引。 目前已经实现了Pre-aggregate DataMap,Timeseries DataMap,Lucene DataMap,BloomFilter DataMap等,个人比较看好CarbonData这个特性。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
