Improving Spark Cubing in Kylin 2.0
作者: 康凯森
日期: 2017-07-10
分类: OLAP
- Make Spark could connect HBase using Kerberos
- Use HDFS manage the metadata for Spark Cubing
- The Spark configuration for Spark Cubing
- The performance test result of Spark Cubing
- The pros and cons of Spark Cubing
- The applicable scenario of Spark Cubing
- The improvement for dict loading in Spark Cubing
- Conclusion
Apache Kylin is a OALP Engine that speeding up query by Cube precomputation. The Cube is multi-dimensional dataset which contain precomputed all measures in all dimension combination. Before v2.0, Kylin uses MapReduce to build Cubes. In order to get better performance, Kylin 2.0 introduced the Spark Cubing. About the principle of Spark Cubing, please refer to this official blog:By-layer Spark Cubing.
In this blog, I mainly talk about the following points:
- How to make Spark Cubing support HBase cluster using Kerberos
- The Spark configuration for Spark Cubing
- The performance test result of Spark Cubing
- The pros and cons of Spark Cubing
- The applicable scenario of Spark Cubing
- The improvement for dict loading in Spark Cubing
In currently Spark Cubing(beta) version, it doesn't support HBase cluster using Kerberos bacause Spark Cubing need to get matadata from HBase. To solve this problem, we have two solutions: ony way is to make Spark could connect HBase using Kerberos, another way is to avoid Spark connect HBase in Spark Cubing.
Make Spark could connect HBase using Kerberos
If we only want to run Spark Cubing in Yarn client mode, we only need to add three line code before new SparkConf() in SparkCubingByLayer:
Configuration configuration = HBaseConnection.getCurrentHBaseConfiguration();
HConnection connection = HConnectionManager.createConnection(configuration);
//Obtain an authentication token for the given user and add it to the user's credentials.
TokenUtil.obtainAndCacheToken(connection, UserProvider.instantiate(configuration).create(UserGroupInformation.getCurrentUser()));
As for How to make Spark connect HBase using Kerberos in Yarn cluster mode, please refer to SPARK-6918,SPARK-12279,HBASE-17040. The solution maybe could work, but not elegant. So I try the sencond solution.
Use HDFS manage the metadata for Spark Cubing
The core idea is uploading the necessary metadata job related to HDFS and using HDFSResourceStore manage the metadata.
Before introducing how I use HDFSResourceStore instead of HBaseResourceStore in Spark Cubing. Let’s see what's Kylin metadata format and how kylin manage the metadata.
Every concrete metadata for table, cube, model and project is a JSON file in Kylin . The whole metadata is organized by file directory. The picture below is the root directory for Kylin metadata,
 This picture shows the content of project dir, the "learn_kylin" and "kylin_test" are both project name.
This picture shows the content of project dir, the "learn_kylin" and "kylin_test" are both project name.

Kylin manage the metadata using ResourceStore, ResourceStore is a abstract class, which abstract the CRUD Interface for metadata. ResourceStore has three implementation classes:
- FileResourceStore (store with Local FileSystem)
- HDFSResourceStore
- HBaseResourceStore
Currently, only HBaseResourceStore could use in prod env. FileResourceStore mainly used for test. HDFSResourceStore still has some concurrent issue, but which could be used for read safely. Kylin use the "kylin.metadata.url" config to decide which kind of ResourceStore will be used.
Now, Let’s see How I use HDFSResourceStore instead of HBaseResourceStore in Spark Cubing.
- Determine the necessary metadata for Spark Cubing job
- Dump the necessary metadata from HBase to local
- Update the kylin.metadata.url and then write all Kylin config to "kylin.properties" file in local metadata dir.
- Use ResourceTool upload the local metadata to HDFS.
- Construct the HDFSResourceStore from the HDFS "kylin.properties" file in Spark executor.
Of course, We need to delete the HDFS metadata dir.
The Spark configuration for Spark Cubing
These are the Spark configuration I used for Spark Cubing. The goal is to make our user set less spark config.
//running in yarn-cluster mode
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
//enable the dynamic allocation for Spark to avoid user set the number of executors explicitly
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=10
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1024
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.shuffle.service.port=7337
//the memory config
kylin.engine.spark-conf.spark.driver.memory=4G
//should enlarge the executor.memory when the cube dict is huge
kylin.engine.spark-conf.spark.executor.memory=4G
//because kylin need to load the cube dict in executor
kylin.engine.spark-conf.spark.executor.cores=1
//enlarge the timeout
kylin.engine.spark-conf.spark.network.timeout=600
kylin.engine.spark-conf.spark.yarn.queue=root.hadoop.test
kylin.engine.spark.rdd-partition-cut-mb=100
The performance test result of Spark Cubing
For the source data level is from million to hundreds of millions of,my test result is consistent with the By-layer Spark Cubing basically. The performance improvement is Remarkable. Moreover I tested with billions of source data or having huge dict specially.
The test Cube1 has 2.7 billion source data, 9 dimensions, one precise distinct count measure having 70 million cardinality.(which means the dict also has 70 million cardinality)
Test test Cube2 has 2.4 billion source data, 13 dimensions, 38 measures(contains 9 precise distinct count measures).
The test result is shown in below picture, the unit of time is minute.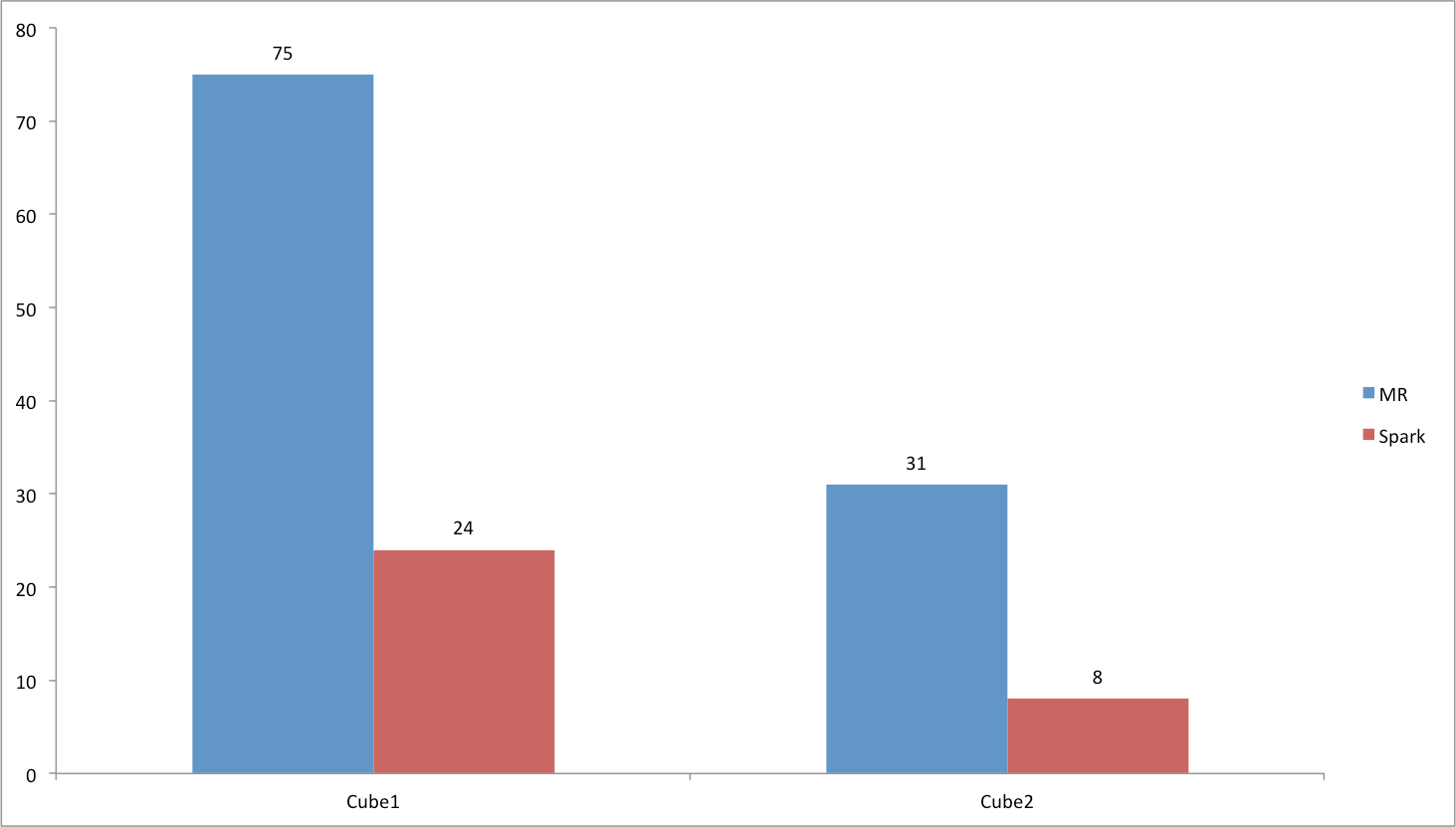
In a word, Spark cubing is much faster than MR cubing in most scenes.
The pros and cons of Spark Cubing
In my opinion, the advantage for Spark Cubing is:
- Because of the RDD cache, Spark Cubing could take full advantage of memory to avoid disk I/O.
- When we have enough memory resource,Spark Cubing could use more memory resource to exchange more better build performance.
On the contrary,the drawback for Spark Cubing is:
- Spark Cubing couldn't handle huge dict well.(hundreds of millions of cardinality)
- Spark Cubing isn't stable enough currently.
The applicable scenario of Spark Cubing
In my opinion, Except the huge dict scenario, we all could use Spark Cubing instead of MR Cubing, especially the following scenarios:
- There is more cube build level.
- There is smaller dict.
- There is lesser source data.
The improvement for dict loading in Spark Cubing
As we all known, A big difference for MR and Spark is the task for MR is running in progress and the task for Spark is running in thread. So, in MR Cubing, the dict of Cube only laod once, but in Spark Cubing, the dict will load many times in one executor, which will result in GC frequently in Spark Cubing.
So, I have done the two improvement:
- Only load the dict once in one executor.
- Add maximumSize for LoadingCache in the AppendTrieDictionary to make the dict removed as early as possible.
Conclusion
Spark Cubing is a great feature for Kylin 2.0, Thanks Kylin community. I will popularize Spark Cubing in our company. I believe Spark Cubing will be more robust and efficient.
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
