Kylin 2.0 Spark Cubing 优化改进
作者: 康凯森
日期: 2017-07-02
分类: OLAP
Kylin 2.0 引入了Spark Cubing beta版本,本文主要介绍我是如何让 Spark Cubing 支持 启用Kerberos的HBase集群,再介绍下Spark Cubing的性能测试结果和适用场景。
Spark Cubing 简介
在简介Spark Cubing之前,我简介下MapReduce Batch Cubing。所谓的MapReduce Batch Cubing就是利用MapReduce 计算引擎 批量计算Cube,其输入是Hive表,输出是HBase的KeyValue,整个构建过程主要包含以下6步:
- 建立Hive的大宽表; (MapReduce计算)
- 对需要字典编码的列计算列基数; (MapReduce计算)
- 构建字典; (JobServer计算 or MapReduce计算)
- 分层构建Cuboid; (MapReduce计算)
- 将Cuboid转为HBase的KeyValue结构(HFile); (MapReduce计算)
- 元数据更新和垃圾回收。
详细的Cube生成过程可以参考 Apache Kylin Cube 构建原理。
而Kylin 2.0的Spark Cubing就是在Cube构建的第4步替换掉MapReduce。
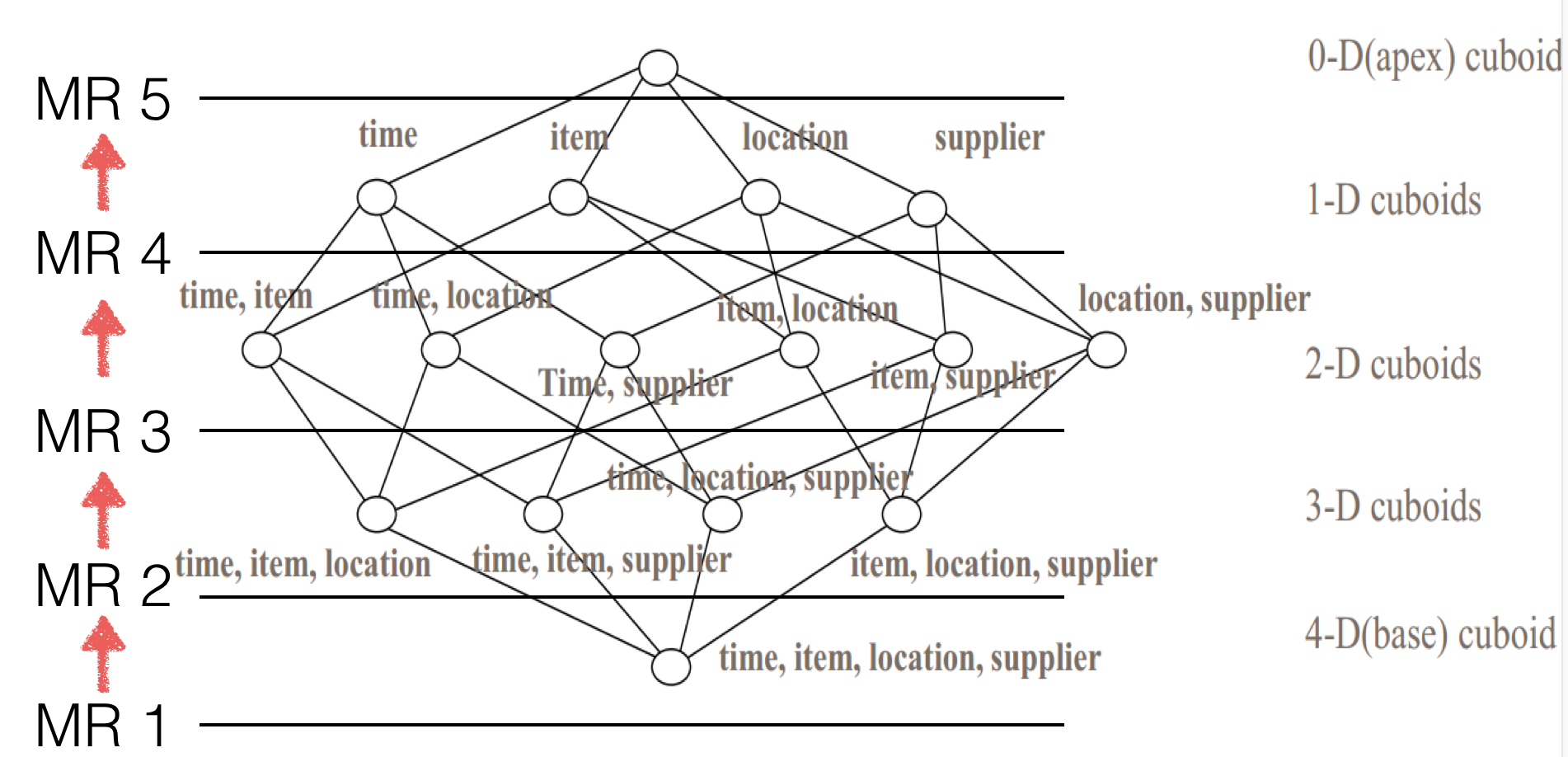
如下图,就是将5个MR job转换为1个Spark job:
(注:以下两个图片引自 Apache Kylin 官网的blog: By-layer Spark Cubing, 更详细的介绍也可以参考这篇blog。)
MapReduce 计算5层的Cuboid会用5个MR Application计算:
Spark 计算Cuboid只会用1个 Application计算:
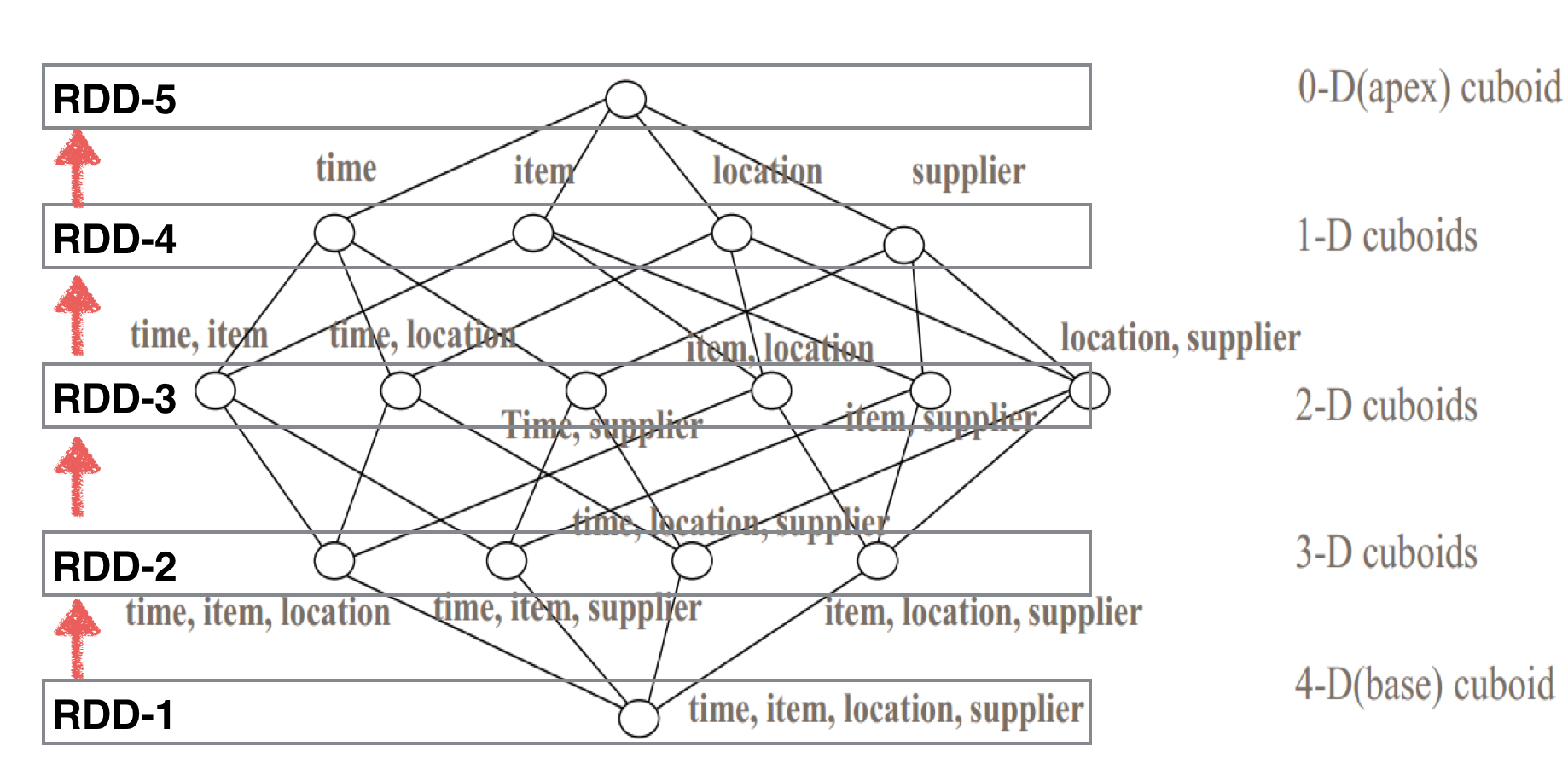
Spark Cubing的核心实现类是SparkCubingByLayer。
为什么目前只有计算Cuboid这一步用Spark计算?
个人认为主要有以下两点:
- 实现并不复杂。
- 收益会比较明显。Cuboid的分层计算方法天然可以利用RDD的Cache特性来加速Cuboid 计算,最理想的情况,如果executor的内存能够完全cache住每层Cuboid的RDD,那就可以完全避免读写磁盘,必然会比MapReduce快很多。
我认为第2点是主要原因。
Cube构建的其他步骤不可以用Spark计算吗?
当然可以! 其中第1步 建立Hive的大宽表 和 第5步 生成HFile 替换为Spark是十分简单的,但是性能提升可能不会十分明显。 至于2步计算列基数,其代码逻辑应该是整个Cube构建中最复杂的一步,复杂的主要原因就是这一步肩负的使命略多。 还有第3步MR构建字典,因为MR构建本身尚不成熟,自然不急着迁移到Spark。
Spark Cubing beta版本目前最大的问题就是不支持启用Kerberos认证的HBase集群,而事实上不少企业级的HBase服务都启用了Kerberos认证。不支持的原因主要是Spark Cubing需要直接从HBase中访问cube,dict等元数据信息。
Spark Cubing 访问 Kerberos认证的 HBase 解1
第一种简单的做法是将访问HBase的token从Kylin的JobServer传递到executor中,这种做法的限制是只能运行在Yarn-client模式中,即必须让driver运行在Kylin的JobServer中。 关于yarn-cluster mode和yarn-client mode两种模式的区别可以参考: Apache Spark Resource Management and YARN App Models。
这种做法的实现方式很简单,只需在SparkCubingByLayer的new SparkConf()之前加入以下3行代码:
Configuration configuration = HBaseConnection.getCurrentHBaseConfiguration();
HConnection connection = HConnectionManager.createConnection(configuration);
TokenUtil.obtainAndCacheToken(connection, UserProvider.instantiate(configuration).create(UserGroupInformation.getCurrentUser()));
但是如果只能在yarn-client模式下运行,必然无法运行在生产环境,因为Kylin JobServer机器的内存肯定不够用。
Spark Cubing 访问 Kerberos认证的 HBase 解2
既然Spark Cubing在 启用Kerberos认证的 HBase集群下无法运行的根本原因是 Spark Cubing需要从HBase 直接访问Job相关的Kylin元数据, 那我们把元数据换个地方存不就可以了, 所以我们将每个Spark Job相关的Kylin元数据上传到HDFS,并用Kylin的HDFSResourceStore来管理元数据。
在介绍实现思路前,我先简介下Kylin元数据的存储结构和Kylin的ResourceStore。
首先,Kylin每个具体的元数据都是一个JSON文件,整个元数据的组织结构是个树状的文件目录。 如图是Kylin元数据的根目录:
 下图是project目录下的具体内容,其中learn_kylin和kylin_test都是project名称:
下图是project目录下的具体内容,其中learn_kylin和kylin_test都是project名称:

我们知道Kylin元数据的组织结构后,再简介下Kylin元数据的存储方式。 元数据存储的抽象类是ResourceStore,具体的实现类共有3个:
- FileResourceStore 本地文件系统
- HBaseResourceStore HBase
- HDFSResourceStore HDFS
其中只有HBase可以用于生产环境,本地文件系统主要用来测试,HDFS不能用于生产的原因是并发处理方面还有些问题。具体用哪个ResourceStore是通过配置文件的kylin.metadata.url来决定的。
所以下面的问题就是我们如何将HBase中的元数据转移到HDFS 和如何将HBaseResourceStore 转为 HDFSResourceStore?
- 确定Spark Job需要读取哪些Kylin元数据
- 将需要的Kylin元数据dump到本地
- 改写kylin.metadata.url并将所有配置写到本地的元数据目录
- 利用ResourceTool将本地的元数据上传到指定的HDFS目录
- 在Spark executor中根据指定HDFS元数据目录的Kylin配置文件构造出HDFSResourceStore。
当然,在最后我们需要清理掉指定HDFS目录的元数据。 整个思路比较简单清晰,但是实际实现中还是有很多细节需要去考虑。
Spark Cubing 参数配置
以下是我使用的Spark配置,目的是尽可能让用户不需要关心Spark的配置
//运行在yarn-cluster模式
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
//启动动态资源分配,个人认为在Kylin生产场景中是必须的,因为我们不可能让每个用户自己去指定executor的个数
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=10
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1024
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.shuffle.service.port=7337
//内存设置
kylin.engine.spark-conf.spark.driver.memory=4G
//数据规模较大或者字典较大时可以调大executor内存
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.executor.cores=1
//心跳超时
kylin.engine.spark-conf.spark.network.timeout=600
//队列设置
kylin.engine.spark-conf.spark.yarn.queue=root.rz.hadoop-hdp.test
//分区大小
kylin.engine.spark.rdd-partition-cut-mb=100
Spark Cubing 的构建性能
对于百万级,千万级,亿级的源数据,且无很大字典的情况下,我的测试结果和官方By-layer Spark Cubing 的结果基本一致,构建速度提升比较明显,而且Cuboid的层次数越多,提速越明显。
此外,我专门测试了数十亿级源数据或者有超大字典的情况,构建提速也十分明显:
测试Cube1
原始数据量: 27亿行 9个维度 包含1个精确去重指标 字典基数7千多万
MR Cuboid构建耗时: 75分钟
Spark Cuboid第一次构建耗时: 40分钟 (spark.executor.memory = 8G,没有加spark.memory.fraction参数)
Spark Cuboid第二次构建耗时: 24分钟 (spark.executor.memory = 8G,spark.memory.fraction = 0.5)
为什么减小spark.memory.fraction可以加速构建?
因为减小spark.memory.fraction,可以增大executor中User Memory的大小,给Kylin字典更多的内存,这样就可以避免全局字典换入换出,减少GC。
测试Cube2
原始数据量:24亿行 13个维度 38个指标(其中9个精确去重指标) 不过这个cube的精确去重指标基数比较小,只有几百万。
MR Cuboid构建耗时: 31分钟
Spark Cuboid构建耗时: 8分钟
总结来说,Spark Cubing的构建性能相比MR有1倍到3倍的提升。
Spark Cubing 的资源消耗
除了构建性能,我们肯定还会关注资源消耗。在这次测试中我没有对所以测试结果进行资源消耗分析,只分析了几个Cube。
我的结论是,在我采用的Spark配置情况下,对于中小规模数据集Spark的资源消耗是小于MR的(executor的内存是4G); 对于有大字典的情况(executor的内存是8G),CPU资源Spark是小于MR的,但是内存资源Spark会比MR略多,在这种情况下,我们相当于用内存资源来换取了执行效率。
Spark Cubing 的优缺点
优点:
- 利用RDD的Cache特性,尽可能利用内存来避免重复IO
- 大部分场景下Cuboid构建速度有明显提升
- 在集群资源充足的情况下,我们可以用更多的资源换取更好的构建性能
缺点:
- 目前版本还未历经生产环境考验,稳定性不确定
- 不适合有超大字典的场景
- 引入Spark Cubing将带来额外的运维成本和沟通成本
Spark Cubing 的适用场景
个人的结论是,除了有好几亿基数超大字典的这种情况,其他情况应该都适用Spark Cubing,其中:
- Cuboid层次越多越适用。
- 数据规模越小越适用。
- 字典越小越适用。
Spark Cubing 字典加载优化
Spark和MR有一点重要的区别就是Spark的Task是在线程中执行的,MR的Task是在进程中执行的。 这点区别会对Kylin的Cube 构建造成重要影响,在MR Cubing中,每个Mapper task 只需要load一次字典,但是在Spark Cubing中,一个executor的多个task会多次load 字典,如果字典较大,就会造成频繁GC,导致执行变慢。
针对这个问题,我做了两点优化:
- 让每个executor里的字典只load一次,让该executor的所有Task共享字典。
- 给全局字典的AppendTrieDictionary中使用的LoadingCache增加maximumSize。 我用了一个有6亿基数的全局字典测试了这个优化,优化后GC时间明显缩短。
Spark 学习资料推荐
网上公开资料如果只推荐一份的话,我推荐: spark-internals
此外,这几篇文章也不错:
how-to-tune-your-apache-spark-jobs-part-1
how-to-tune-your-apache-spark-jobs-part-2
当然,看的资料再多自己不思考都没啥卵用。 学习一个系统,我们可以从系统的整体架构和设计层面开始,自顶向下的学习,也可以从一个具体的问题把整个系统涉及的所有模块串起来,切面式学习。 个人感觉两种方式结合着效率会比较高,而且一般从具体问题入手会让印象更深刻,理解更深入。
总结
用HDFSResourceStore替换HBaseResourceStore后,Spark Cubing已经具备了在启用Kerberos的HBase集群环境下大规模使用的基础。后续我将开放Spark Cubing功能让感兴趣的用户使用。最后,十分感谢我们团队Spark 小伙伴的给力支持。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
