数据库从0到0.1 (一): LSM-Tree VS B-Tree
作者: 康凯森
日期: 2018-05-26
分类: 数据库
数据库最基本两个功能:数据的存储和数据的查询。 当我们写入数据时,数据库可以存储数据;当我们需要访问数据时,数据库可以给我们想要的数据。 数据库会通过特定的数据模型和数据结构存储数据,并支持通过特定的查询语言访问数据。本文将从最简单的数据库开始,讨论数据库如何存储数据,如何查询数据。本文将讨论两种存储引擎:log-structured 存储引擎和以B+树为代表的page-oriented存储引擎。
1 最简单的数据库
#!/bin/bash
#key,value对追加写入文件的最后一行
db_set () {
echo "$1,$2" >> database
}
#查找指定key的最后一行的最新的value
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
上面两个Shell函数实现了最简单的Key-Value数据库。 调用db_set可以写入数据,调用db_get可以查询数据,数据的物理存储格式是逗号分隔的普通文本文件。
bash-3.2$ db_set 1 kks
bash-3.2$ db_get 1
kks
bash-3.2$ db_set 2 kangkaisen
bash-3.2$ db_get 2
kangkaisen
bash-3.2$ db_set 1 KKS
bash-3.2$ db_get 1
KKS
bash-3.2$ cat database
1,kks
2,kangkaisen
1,KKS
其中db_set函数拥有很好的写入性能,因为是追加写;但是db_get函数的性能十分糟糕,其时间复杂度是O(n),我们每次必须全表Scan。
2 Index
为了能够快速找到特定Key对应的Value, 我们需要引入一个数据结构:Index。 所谓Index,就是我们在数据库中增加额外的元数据,然后Index像路标一样可以快速知道我们需要访问数据的位置和偏移量。 Index类似汉语字典中的索引和一般书籍中的目录。如果我们需要按照不同的方式访问相同的数据,我们有可能需要多种不同的索引,比如按照Key查询和按照Value查询,我们会分别需要针对Key的索引和针对Value的索引。
Index是基于原始数据衍生的附加的数据结构,增加索引必然意味着降低数据写入速度,增大存储空间,所以Index是以数据写入时的处理成本和存储的空间成本来换取查询的加速。这也是数据库设计的一个trade-off,不同索引的查询加速比,写入时的处理成本,存储的空间成本往往是不同的,所以在设计数据库时选择何种索引是一个很重要的点。
3 Hash Index
下面就让我们用Index加速之前最简单的Key-Value DB。之前我们db_get方法查询特定Key必须全表Scan的原因,是因为我们不知道特定Key在文件中的Offset,假如我们知道了每个Key的Offset,我们就可以直接Seek到Key对应的Offset,直接读取Key对应的Value。而Key到Offset的映射我们自然会想起到我们熟悉的数据结构HashMap,我们可以在内存中维护一个HashMap,HashMap的Key就是Key-Value DB的每一条记录的Key,HashMap的Value就是每一条记录在文件中的Offset。
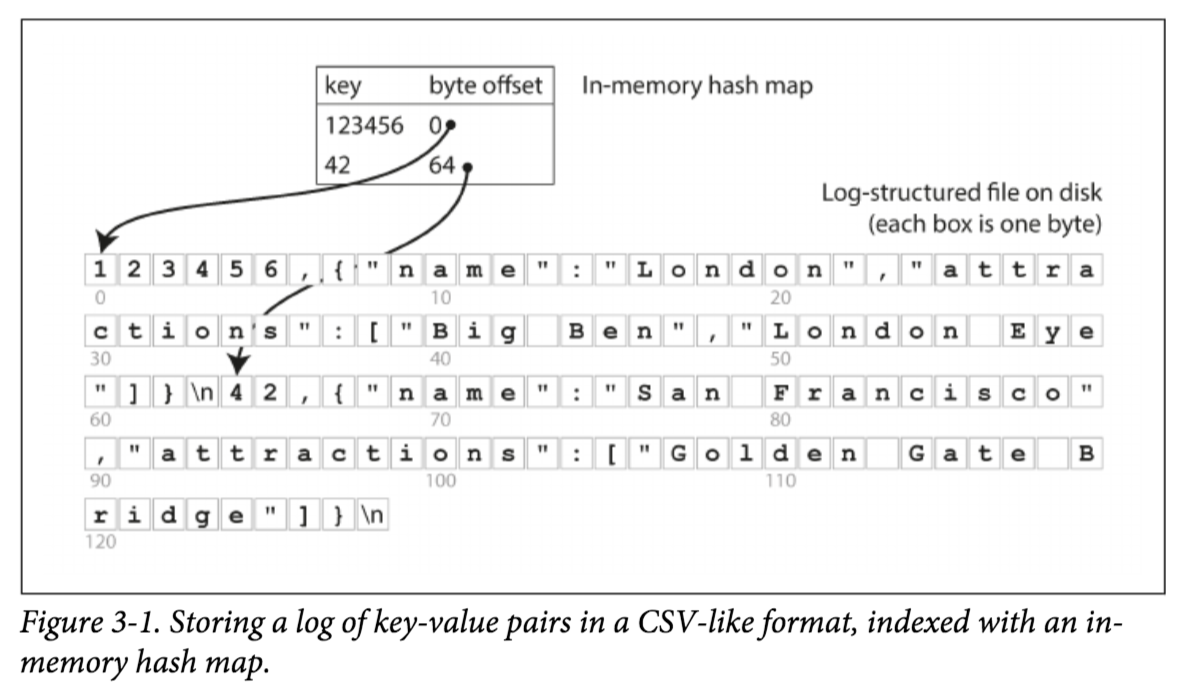
有了HashMap后,我们每次写数据后就必须要更新HashMap,查询数据时先从HashMap获取特定Key的Offset,再直接Seek到文件对应Offset的位置,读取数据。 事实上Bitcask(Riak的默认存储引擎)就是这样做的。
不过显然Hash Index有两个缺陷:
- 内存的大小必须可以放下Hash Table
- Range Scan的效率十分低下
4 Segment
目前为止,我们都是把数据写到一个文件中,这显然是不合理的。 一个常见的做法就是将文件按照大小拆为为Segment,每个Segment是不可变的。 Segment的概念很常见,比如Kylin和Druid中都有Segment的概念,指一定大小或者一定时间内不可变的文件。
第1部分我们知道,我们同一个Key的Value的更新只是追加写入,并没有删除旧的Value。 当我们有了多个Segment后,我们自然就可以定期在后台执行Compaction操作,将同一个Key的旧Value删除,更进一步,如果我们数据库支持delete的话,我们可以在一开始只进行标记,并不实际删除,等到Compaction的时候,我们再进行实际删除。 总之一句话,基于log-structured的存储引擎,我们可以通过后台的Compaction来实现update和delete,Compaction时依然可以进行数据的写入和查询。
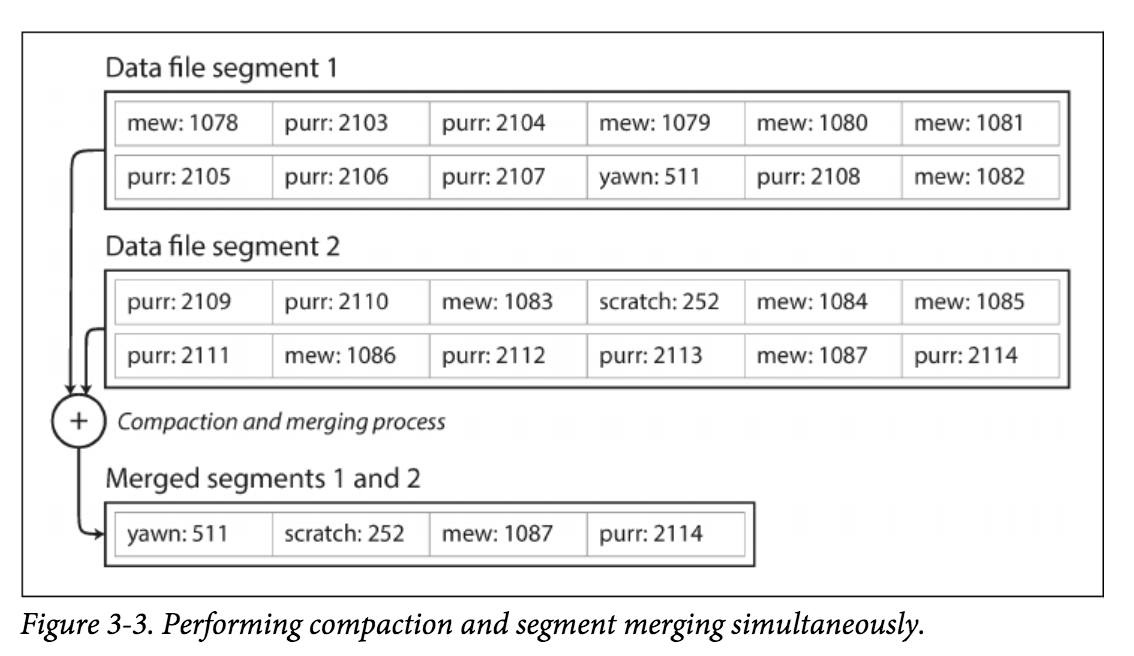
至此,每个Segment文件都在内存中有了对应的Hash table。 我们查询时为了找到特定Key对应的Value,我们依次查询每个Segment文件即可,查询每个Segment文件的过程和之前一样。
这种Append-only Log-structured的存储引擎的优点:
- 顺序写的效率远高于随机写
- 并发控制和故障恢复十分简单,因为Segment文件是不可变的,且是Append-only的,
为什么不再对Segment文件做索引呢?
这样我们就不需要顺序遍历每个Segment文件了,有了索引我们就只需要访问包含特定Key的Segment文件。
5 SSTables and LSM-Trees
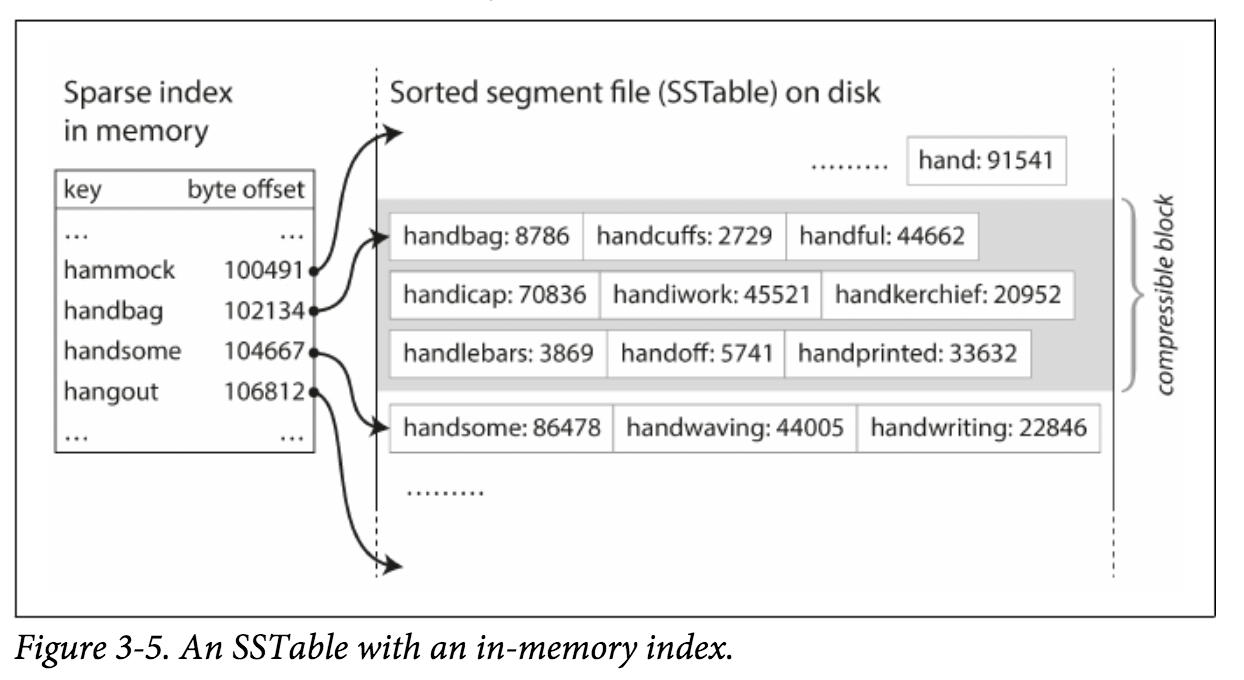
现在对Segment文件的格式做个简单的改变:我们要求所有的 key-value对必须按照Key排序。 这种格式我们称之为Sorted String Table, 简称为SSTable。 我们也要求在每个已经Merged的Segment文件中1个Key只会出现一次,Compaction过程保证了这一点。
SSTable相比Log Segments + Hash Indexes 有以下几个明显的优势:
- Segment的Merge会更加简单和高效,即使合并的所有文件比内存还大。 因为每个Segment是有序的,Sort Merge的成本比较低。
- 为了查找特定Key,我们不再需要在内存中维护一个很大的Hash Map。因为所有的key-value对是按照Key排序的,所以我们可以维护一个Segment文件的稀疏索引,索引的Key是每个Segment文件的Start Key,Value就是每个Segment文件的位置。 其次,在Segment内部,由于Segment有序,我们不再需要针对每个key-value对都构建索引,我们可以针对Block(几百或者几千行数据)粒度做稀疏索引,Block内存则进行二次查询。
- 由于我们的读取的最小粒度是Block,我们也可以基于Blcok粒度做压缩,减小磁盘空间和IO。
- SSTable不仅可以较好的支持Point Query,也可以很好的支持Range Scan。
那么我们如何保证Segment文件有序呢? 因为数据写入一般都要经过内存,在内存中我们可以利用Red-black tree 或者AVL tree保证有序。
至此,我们基于SSTable的存储引擎可以这样Run起来:
- 当一条数据写入时,我们将其插入到基于内存的平衡树中(Red-black tree)。 内存中的树我们称之为Memtable。
- 当Memtable的大小超过一定阈值时,我们将Memtable Flush到磁盘,转为SSTable。
- 当我们查询时,需要同时查询内存中的Memtable和磁盘中的SSTable。
- 周期性的在后台进行异步的Merge和Compaction操作。
- 为了防止Memtable在Flush到磁盘前机器故障导致数据丢失,我们可以在磁盘上维护一个只追加写的log文件,称之为Write-Ahead-Log,当集群故障后可以从log中恢复出Memtable。 所以我们在每次写入Memtable,需要先写入WAL。当Memtable flush到磁盘后,对应的WAL文件就可以删除。
至此,LSM-Tree(Log-Structured Merge-Tree)的3个组件:SSTable,Memtable,Write-Ahead-Log终于全了。 从开始最简单的Key-Value 数据库 讲到现在,我相信你已经理解了LSM-Tree的核心思想。
LSM-Tree 已经被广泛使用,比如LevelDB,RocksDB,Cassandra,HBase等,其中的SSTable也是被广泛借鉴,比如ClickHouse,Palo等。
6 磁盘简介
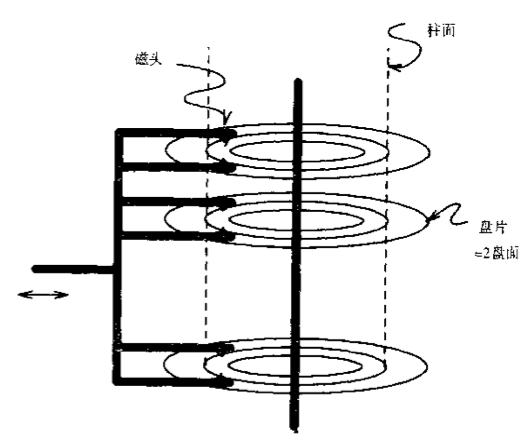
如图,一个磁盘由多个盘片组成。
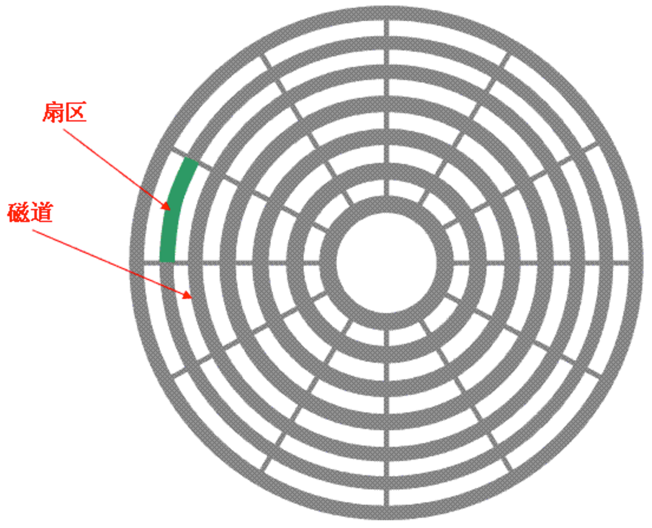
如图,1个盘片由一个个的同心圆组成,一个同心圆就是一个磁道,每个磁道由多个扇区组成,每个磁道的扇区数量是一个常量,每个扇区的大小一般是4KB,扇区是磁盘基本的物理单元。
一次磁盘IO的耗时主要由三部分组成:寻道时间 + 旋转延迟 + 数据传输时间。
- 寻道时间: 将读写磁头移动至正确的磁道上所需要的时间。 目前磁盘的平均寻道时间一般在3-15ms。
- 旋转延迟: 盘片旋转将请求数据所在的扇区移动到读写磁盘下方所需要的时间。旋转延迟取决于磁盘转速,转速为15000rpm的磁盘其平均旋转延迟为2ms。
- 数据传输时间:传输实际数据所需要的时间,它取决于数据传输率,其值等于数据大小除以数据传输率。目前IDE/ATA能达到133MB/s,SATA II可达到300MB/s的接口数据传输率,数据传输时间通常远小于前两部分消耗时间。
提高磁盘读写速度方法就是尽量减小寻道时间和旋转延迟,而减少寻道时间和旋转延迟的方法就是减少磁盘的随机IO,这就是为什么磁盘顺序读写的性能远高于随机读写的原因。
7 B-Trees
前面我们从零开始了解了LSM-Tree的核心原理,但是在数据库领域使用最广泛的索引结构是B-tree及其变种。
其实之前我们为最简单的数据库增加索引的时候,如果我们同时希望提高查询性能,支持原地更新和删除,支持Point query和Scan query, 保持高效的插入性能,我们就会比较自然的想到二叉查找树, 平衡二叉查找树,红黑树,B-Tree 及其最常见的变种B+Tree等树结构, 如果再考虑到面向磁盘,以及更好地支持Scan query,我们就会选择B+Tree。B+Tree具有较低的深度,这样就减少了磁盘 Seek操作的次数。
类似LSM-Tree,B-Tree也可以提供高效地Point query和Scan query。 但是两者的设计哲学是完全不同的:LSM-Tree是将数据拆分为几百M大小的Segments,并是顺序写入;B-Tree则是面向磁盘,将数据拆分为固定大小的Block或Page, 一般是4KB大小,和磁盘一个扇区的大小对应,Page是读写的最小单位。
在数据的更新和删除方面,B-Tree可以做到原地更新和删除,但由于LSM-Tree只能追加写,所以只能在Segment Compaction的时候进行真正地更新和删除。
大家可以通过B+Tree 可视化理解B+Tree的插入,查找,更新和删除过程。
关于B+Tree更详细的原理可以参考此文MySQL索引背后的数据结构及算法原理。
8 B-Tree VS LSM-Tree
一般而言, LSM-tree的写更加高效(追加顺序写),B-tree的读更加高效(LSM-tree需要访问几个不同的数据结构)。
LSM-Tree的优点:
- 高吞吐的写
- 可以高效的压缩,更节省磁盘(B-Tree一般会为Page的分裂预留一些空间)
LSM-Tree的缺点:
- Compaction会影响正常数据的读写。 阿里为了优化这个问题,X-DB的Compaction使用了FPGA来进行。
- 数据量越大,Compaction需要的磁盘带宽就越多。
- B-Tree中一个Key只会出现在一个Page,但是LSM-tree中一个key可能出现在多个Segment,所以B-Tree实现事务更加简单。
9 参考资料
1《Designing-Data-Intensive-Applications》第3章的第一部分《Data Structures That Power Your Database》
2 计算机底层知识拾遗(三)理解磁盘的机制 第6部分磁盘简介参考
3 磁盘I/O那些事 第6部分磁盘简介参考
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
