SnappyData 原理和架构: 一统Streaming Processing,OLTP和OLAP
作者: 康凯森
日期: 2018-06-03
分类: OLAP
- 1 Why SnappyData
- 2 The Challenges Of SnappyData Goal
- 3 What SnappyData
- 4 The Challenges of Marrying Spark & GemFire
- 5 How SnappyData
- 6 SnappyData Architecture
- 7 Why SnappyData is 20X Faster Than Spark
- 8 SnappyData Deploy Modes
- 9 Pros And Cons Of SnappyData
- 10 What Can We Learn From SnappyData
- 11 Conclusion
- 12 References
注:本文对SnappyData的描述仅基于对SnappyData论文和官方文档的阅读。
1 Why SnappyData
SnappyData诞生的背景是当时没有一个单一系统可以同时满足Streaming Processing + OLTP + OLAP这3个需求。
当时的常见解决方案如下:
- SQL On Hadoop(Hive, Impala/Kudu and Spark SQL等)
- HTAP系统(MemSQL,TiDB,Spanner等)
- SQL On Streaming
- Lambda架构
这些解决方案的问题如下:
SQL ON Hadoop(Hive, Impala/Kudu and Spark SQL)主要面向离线的OLAP分析,具有以下问题:
- 不支持实时
- 不支持事务
- 不支持高效的点查
- 不支持高并发
HTAP系统可以同时支持OLTP和OLAP,但是需要依赖外部系统(Storm, Kafka, Confluent)进行Stream Processing;
SQL On Streaming系统无法高效处理复杂的OLAP查询,也无法高效Join实时和历史数据。
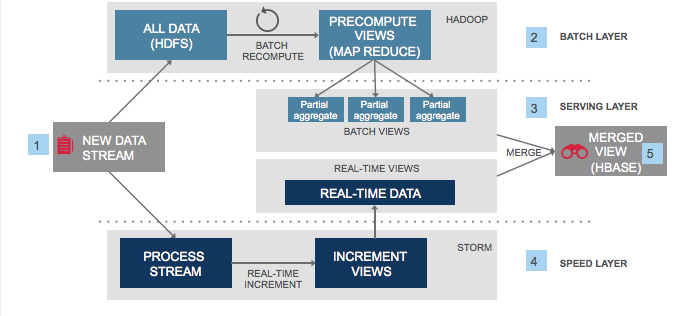
上图原始地址:https://untitled-life.github.io/images/post/the_lambda_architecture_for_big_data_systems.png
{kind=link}
上图是Lambda架构的一个示意,Lambda架构虽然可以满足Streaming Processing + OLTP + OLAP这3个需求,但是有以下缺点:
- Increased complexity and total of ownership:用户的学习成本高昂:用户需要熟悉多个系统的原理,概念,API,模型;用户的开发成本较高,开发效率较低;平台维护多个系统的成本高昂
- Wasted resources:数据需要存储多份,数据同步有延迟,数据流较长,数据格式需要多次转换,资源浪费较严重
- Consistency challenges: 多个系统间数据的一致性难以保证。
由于现有解决方案的诸多问题,SnappyData团队决定打造一个能够同时满足Streaming Processing + OLTP + OLAP的单一系统,并希望这个系统相比于现有解决方案能有更好的性能,更少的资源和更低的复杂性。
2 The Challenges Of SnappyData Goal
- Streaming Processing,OLTP,OLAP需要不同的数据结构和查询处理方式:比如Streaming Processing一般需要基于Sketches和Window的数据结构,OLTP需要行存,OLAP需要列存;Streaming Processing一般是delta/incremental的查询处理,OLTP一般是点查,点更新,OLAP一般是大量的Scan,Aggregation和Join。
- Streaming Processing,OLTP,OLAP这3种不同的Workload如何进行合理的调度和资源分配:Streaming Processing Job一般是常驻的,OLAP查询一般耗时在秒级,OLTP耗时一般在毫秒级。
3 What SnappyData
SnappyData是一个基于Spark+GemFire(开源版本是Geode)实现的,可以同时满足Streaming Processing + OLTP + OLAP需求的分布式内存数据库。具有以下特点:
- 同时支持Streaming Processing + OLTP + OLAP
- 基于内存
- 支持标准SQL,同时支持JDBC,ODBC,Spark API访问
- 支持分布式事务
- 比Spark快20x(官方号称)
- 100% Compatible With Apache Spark:可以使用Spark SQL,Spark API,Spark ML访问; 支持Spark的所有Data Sources;支持结构化数据和半结构化数据
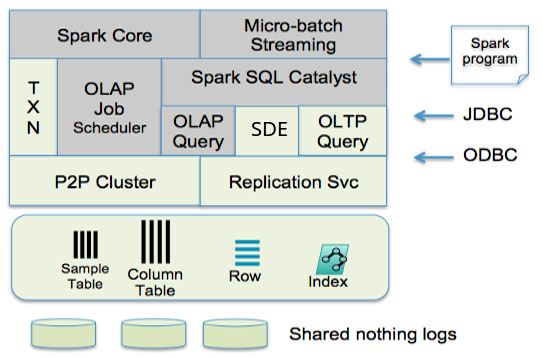
下图是SnappyData的组件图,灰色部分是Spark本身的模块。
4 The Challenges of Marrying Spark & GemFire
Spark是一个高效的分布式计算引擎,GemFire是一个低延迟,高可用,支持事务,面向行存,分布式的Key-Value内存数据库。Spark的设计目标是高吞吐,GemFire的设计目标是低延迟。要将Spark和GemFire整合来同时满足Streaming Processing + OLTP + OLAP的需求,显然会有不少挑战:
- 需要改变Spark Executors的生命周期,使得Executors的JVM是常驻的,并和Applications解耦;其次需要使用静态的资源分配策略使得同一份资源可以被多个Applications并发使用。
- 如何区分一个查询是OLTP还是OLAP。
- Spark Driver是单点。
- 扩展Spark支持基于GemFire可变的并发数据结构的点查询,点更新和点删除。
- 扩展GemFire的分布式锁服务以便在Spark中可以修改这些可变的数据结构。
- 需要100%兼容Spark代码。
5 How SnappyData
将GemFire整合进Spark,GemFire让SnappyData可以实现低延迟,细粒度,高并发的OLTP操作。
- SnappyData中的Streaming Processing是通过Spark Streaming实现的
- SnappyData中的OLTP功能是通过GemFire实现的
- SnappyData中的OLAP功能是通过Spark + Column Store实现的
SnappyData的存储
SnappyData同时支持行存和列存。列存是基于Spark RDD的实现衍生而来,行存是基于GemFire实现;一个表是使用行存还是列存需要在建表时指定;行存可以同时支持分区表和复制表(会复制到所有节点上,适合OLAP星型模型中的小维表),列存只支持基于Hash的分区表;行存支持索引,基于索引的Keys可以实现快速的读写,列存不支持索引,是按照连续的Blocks组织,支持dictionary,run-length 和bit 3种编码方式;行存支持“read committed” and “repeatable read”级别的事务隔离,列存支持快照级别的事务隔离。
我们知道,行存实现点更新十分简单,但是列存如何实现高效的点更新呢?
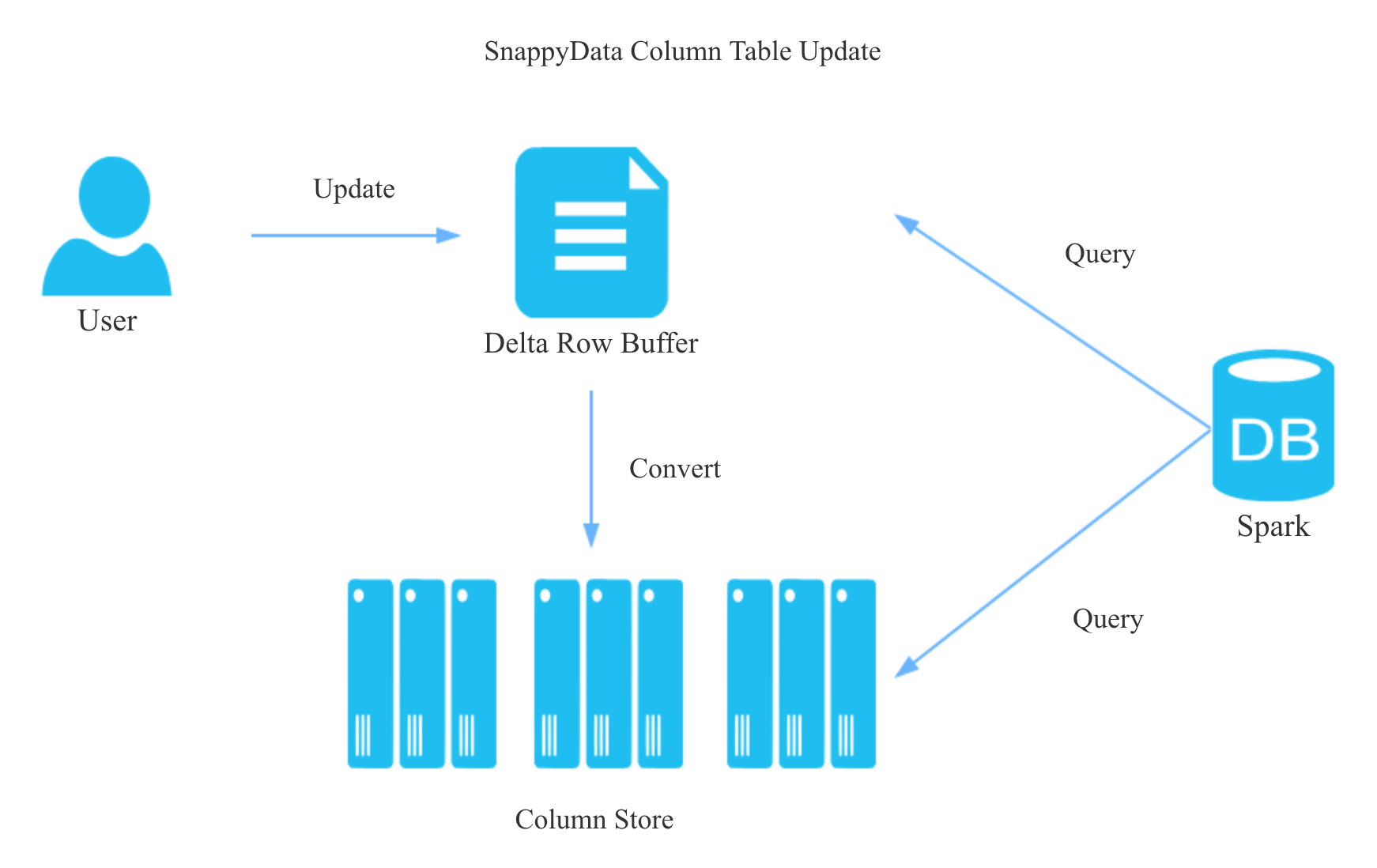
如上图所示,和LSM的思想类似,列存表的点更新会先写入一个delta row buffer的数据结构, delta row buffer是一个合并队列,合并的含义是同一条记录的所有更新操作只会保留最终状态, delta row buffer使用Copy on Write的方式支持并发更新, 超过一定行数或大小时会转为列存。所以在查询列存表时需要Merge列存和delta row buffer的结果。
SnappyData的查询接口
SnappyData同时支持标准SQL(扩展自Saprk的SparkSQL dialect)和Saprk API.
SnappyData的Stream Processing
SnappyData的Stream Processing主要是通过Spark Streaming来实现的,不过SnappyData优化了Stream Processing的OLAP查询能力,比如columnar formats, approximate query processing, and co-partitioning。
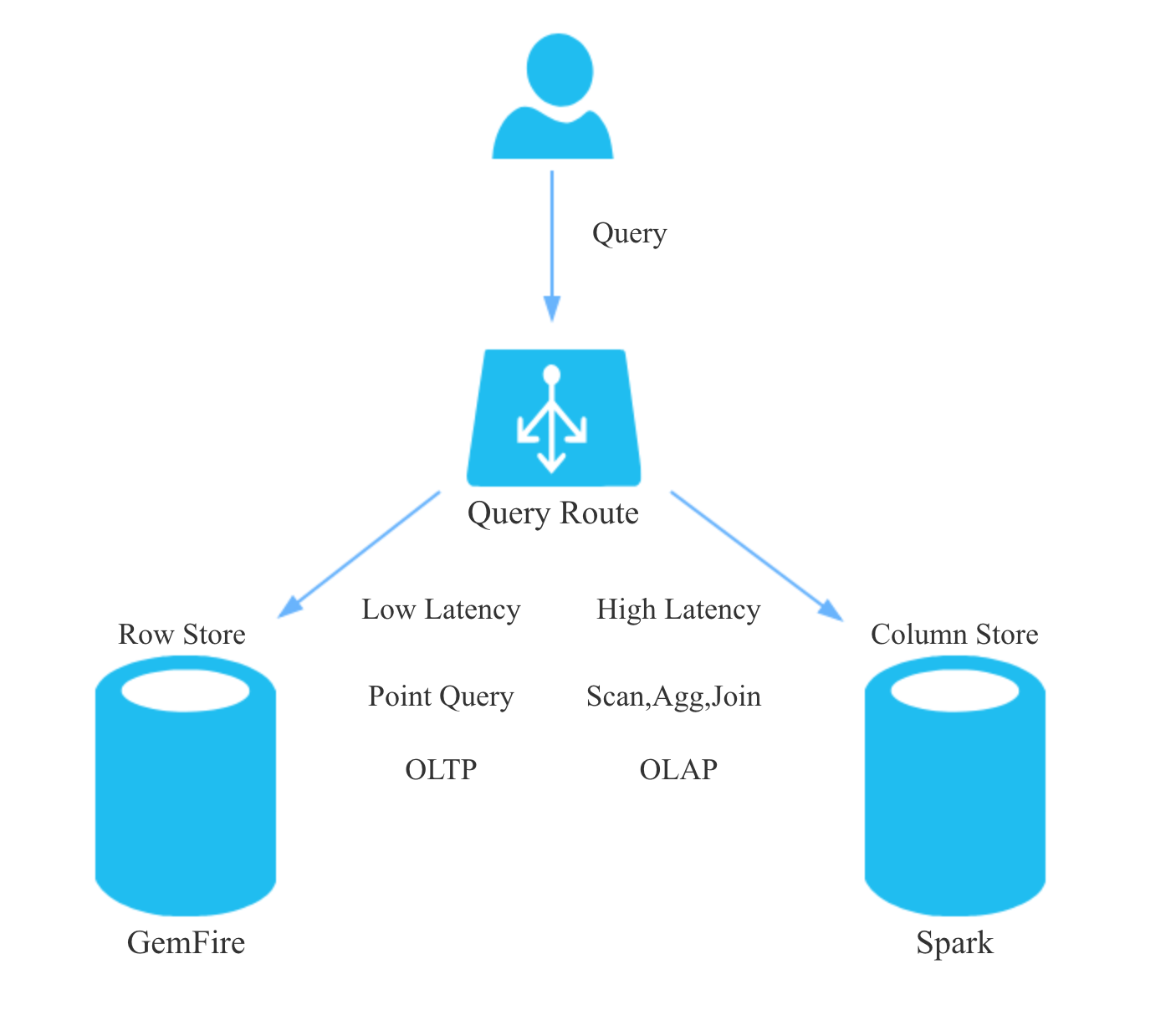
SnappyData的查询路由和调度
SnappyData将OLAP查询交给Spark,将OLTP查询交给GemFire。SnappyData一般将OLTP请求视为低延迟请求,将OLAP请求视为高延迟请求,低延迟的OLTP请求会绕过Saprk的调度直接操作数据,OLAP请求会交给Saprk的公平调度器调度执行。 当然,一个查询也可以显式的标注优先级。 下图是个简单的示意图:
SnappyData的高可用
Spark Driver通过主备的方式实现高可用。
SnappyData的失败探测依赖依赖UDP neighbor ping和 TCP ack timeout。
SnappyData将细粒度的事务更新的Recovery交给GemFire,将Batched and streaming micro-batch的操作交给了Spark。Saprk的Recovery依赖RDD的lineage;GemFire的Recovery依赖replication。
6 SnappyData Architecture
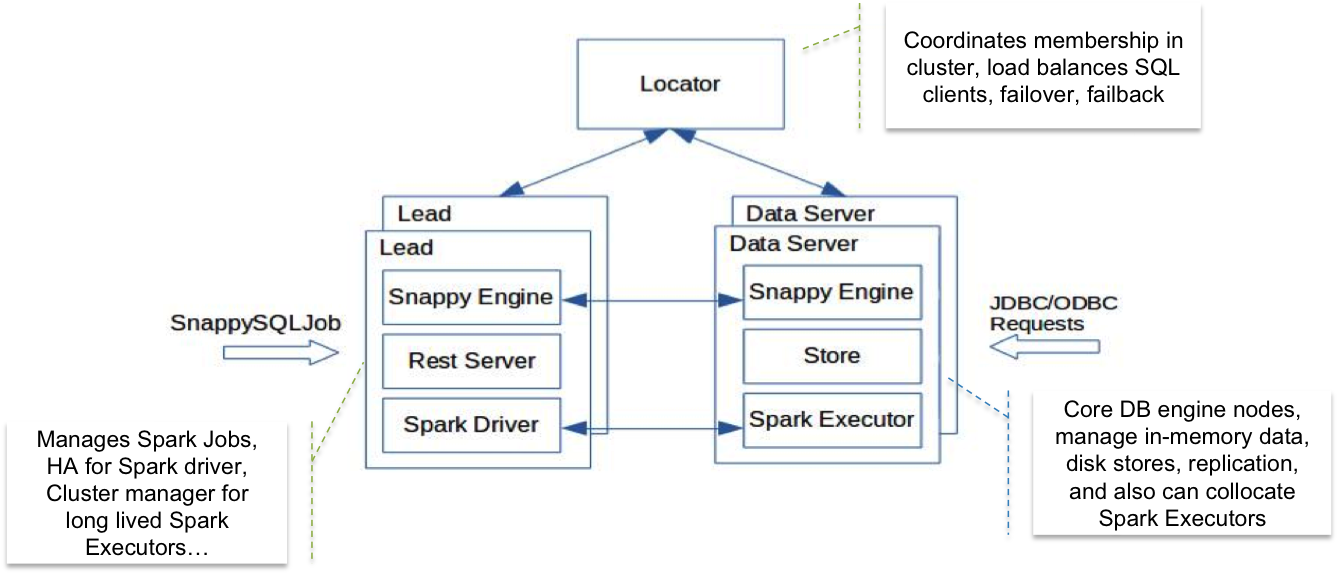
如上图所示,SnappyData的节点分为三类:
- Locator: 服务发现。
- Lead Node: Spark的Driver,负责将OLAP类型的查询分发给Executor,接收Saprk API的请求。 Lead Node借助Spark JobServer来管理Saprk Job和查询。
- Data Servers: 管理数据,内嵌Spark executor。接收JDBC和ODBC的查询请求,并解析SQL,如果是点查询,点更新之类的OLTP请求,就直接执行,如果是需要Scan, Aggregate,Join的OLAP请求,就转发给Lead Node。
7 Why SnappyData is 20X Faster Than Spark
SnappyData 主要通过以下手段来加速OLAP查询:
Data Colocate:核心思想是Join时避免Shuffle。具体有两种手段:
- Partition To Partition Join:Co-partitioning with shared keys,几张Join的表基于Join的key提前预分区,从而实现每个Partition的Local Join,适合多张大表的Join。
- Local Join:星型模型中维表通常比较小,且更新频率较低,所以可以将维表设置为Replicated Tables,保证每个节点上都有维表,从而避免Broadcast Join,实现Local Join。
Code Generation: 借助了Spark Tungsten的Code generation
- 列存使用了Spark原生的Column Format,所以避免了序列化和反序列化的开销。
- Spark Executors和Data Store 都运行在一个JVM中: 没有数据Copy开销。
- 数据都是在内存中。
- Long Running Executors: 提交一个Job不需要启动新的Executor。
8 SnappyData Deploy Modes
SnappyData 有3种部署模式:
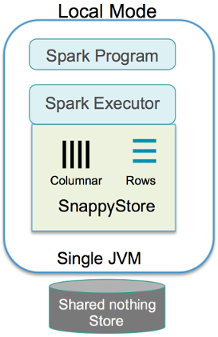
1 Local 模式: Client Application, Executors和Data Store 都运行在一个JVM中,主要用来开发测试,如下图所示:
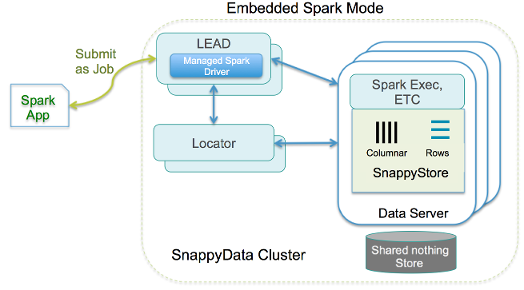
2 Embedded SnappyData Store 模式:Spark Executors和Data Store 都运行在一个JVM中,如下图所示:
3 SnappyData Smart Connector 模式: Spark Executors运行在独立的JVM中,把SnappyData当做Spark的一个普通的Data Source。 这就像Spark applications中访问Cassandra, Redis和HBase等外部Store一样。 如下图所示:

9 Pros And Cons Of SnappyData
优点:
- 一个系统同时满足了Streaming Processing + OLTP + OLAP这3个需求,开篇提到的Lambda架构的缺点SnappyData基本都解决了。
- 完全基于Saprk生态,对Spark生态和开发者十分友好。
缺点:
- Spark和GemFire两个项目都十分复杂,要维护开发SnappyData,则必须要十分熟悉Spark和GemFire。
- SnappyData未来的瓶颈或许会受到Spark和GemFire的限制,日常开发中也需要考虑到Spark和GemFire的兼容性,Spark和GemFire的稳定性也会影响SnappyData的稳定性。
- 列存没有索引。
- 应该会有OOM和GC问题。
- 不是真正的HTAP系统,一份数据无法同时高效的支持OLTP和OLAP查询,因为SnappyData中一份数据要么是行存,要么是列存。
10 What Can We Learn From SnappyData
- 踩在巨人的肩膀上前行,通过借力Apache Spark和GemFire两大项目的力量,大幅缩短工期,快速实现了复杂度极高的目标。
- 论证了如何通过巧妙地统一行存和列存来同时满足OLTP和OLAP需求。
- 展示了如何将Spark扩展为一个DataBase。
- 论证了Data Colocate的可行性和必要性。
11 Conclusion
SnappyData的设计目标是1个系统同时满足Streaming Processing + OLTP + OLAP,但是从我目前的视野和认知来看,Streaming Processing 似乎并不属于DataBase的职责,DataBase只要做好数据的存储和查询(OLTP + OLAP), 能够同时很好的支持实时和离线数据的摄入就可以了。 目前整个业界还没有1个开源的DataBase能够同时做好OLTP + OLAP的查询。 至于HTAP的DataBase怎么实现,我个人不倾向这种基于通用计算引擎Spark改造的思路,更倾向于一个针对OLTP+OLAP优化的查询引擎+针对DB优化的存储引擎(行列混存)的思路。
12 References
- SnappyData 论文
- SnappyData 官方文档
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
