畅想TiDB应用场景和HTAP演进之路
作者: 康凯森
日期: 2018-04-30
分类: 数据库
前一阵阅读了TiDB官方的文档和使用案例,对TiDB的架构原理,使用场景有了一定了解,本文深度畅想(胡思乱想)下TiDB未来可能的应用场景和HTAP的演进之路。在畅想TiDB的应用场景之前,我们先了解下TiDB诞生的背景和TiDB是什么,要解决什么问题。
1 Why TiDB
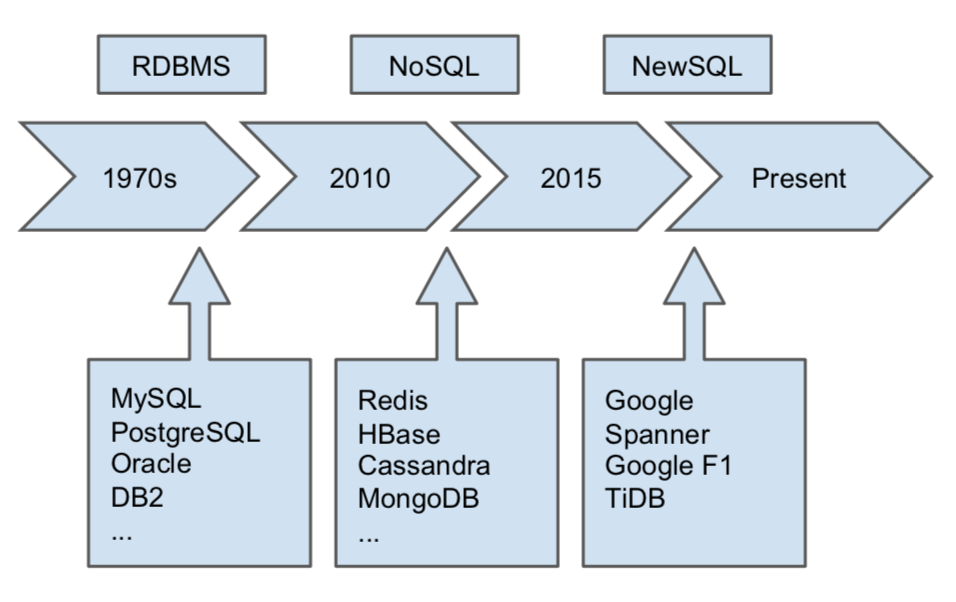
如上图,从1970s年代开始,出现了以Mysql,PostgreSQL为代表的RDBMS, 并在相当长的时间内占据主导地位,但是随着21世纪互联网的快速发展和业务数据的飞速增长,传统数据库缺乏Scalability的缺陷暴露出来,于是出现了以HBase,Redis,MongoDB为代表的NoSQL数据库,NoSQL数据库拥有很好的Scalability和Availability,但是缺乏SQL和ACID Transaction。因此,我们需要一个新一代数据库,能够同时拥有RDBMS和NoSQL数据库的优点。
2 What TiDB

TiDB是一款HTAP数据库(同时支持OLTP和OLAP查询),同时具备了RDBMS和NoSQL数据库的优点,具有以下特点:
- 优秀的横向扩展能力
- 高可用
- 强一致性
- 支持ACID事务
- 支持SQL,兼容Mysql协议和绝大多数Mysql语法
- Cloud-Native
- 支持多数据中心
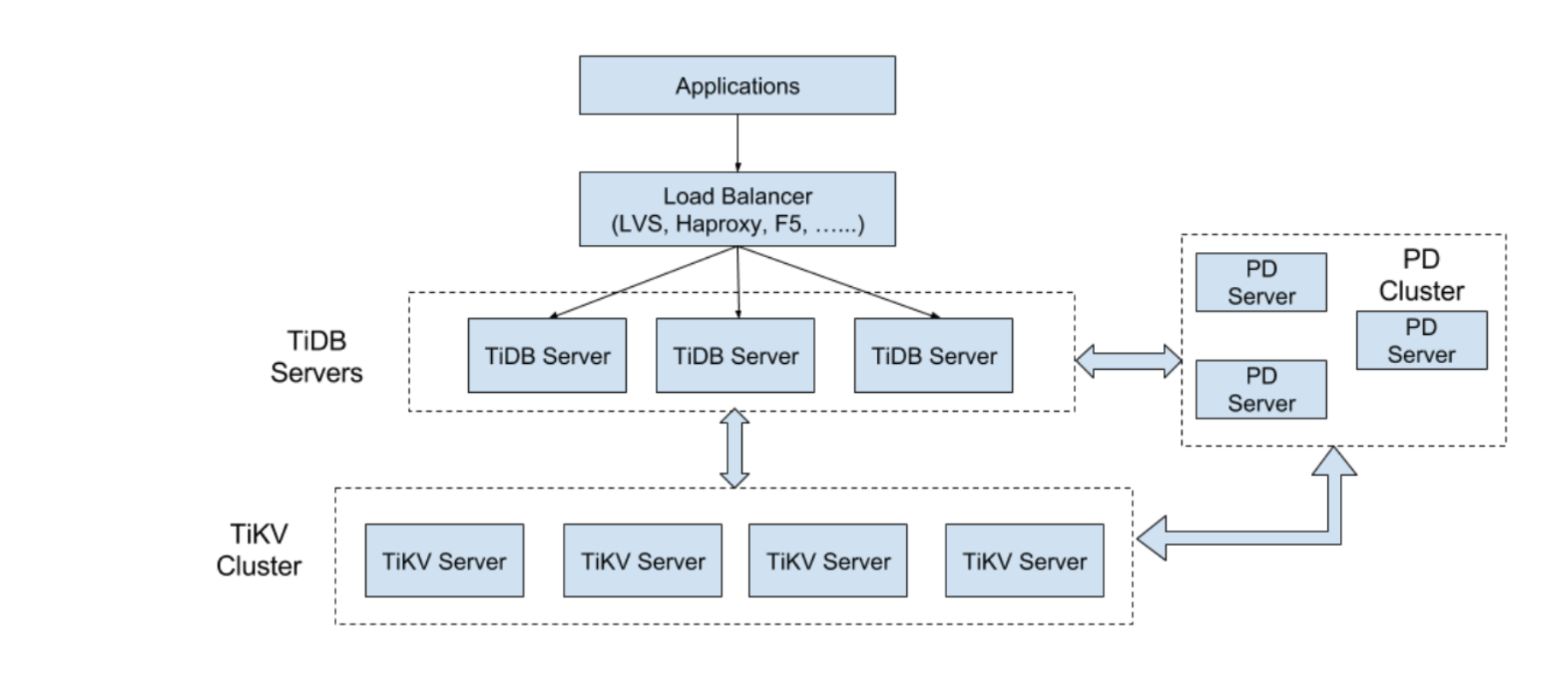
TiDB的架构图如上图所示,TiDB的组件共有3个:TiKV Server,TiDB Server,Placement Driver。 每个组件的主要职责如下:
1 TiKV Server
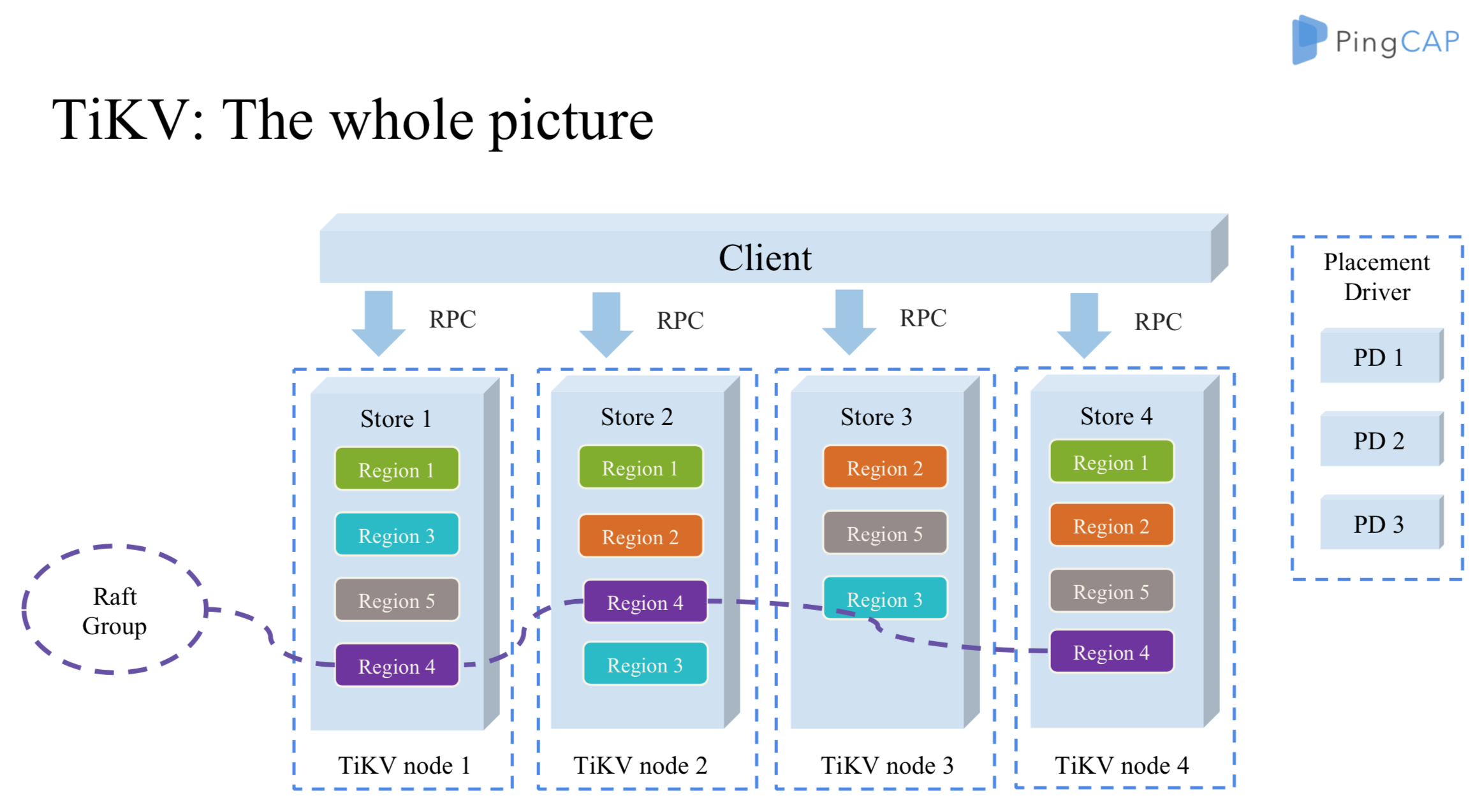
如下图,TiKV Server 负责存储数据,TiKV 是一个支持事务的分布式Key-Value存储引擎,如果不考虑Region复制,一致性,和事务的话,TiKV其实和HBase很像,底层数据结构都是LSM-Tree, Region都是Range分区, Region都是计算和负载均衡的基本单位。
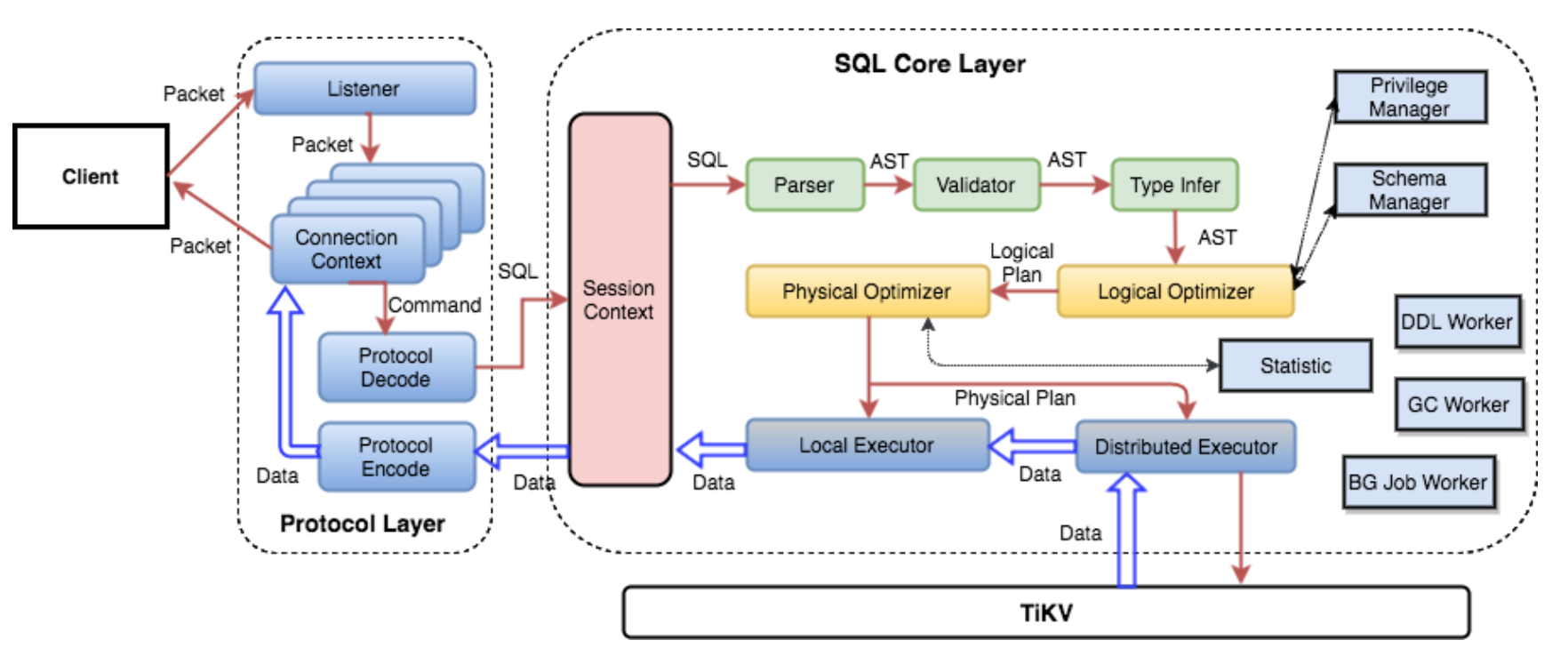
2 TiDB Server
如下图,TiDB Server 负责接收 SQL 请求,生成SQL的逻辑计划和物理计划,并通过 PD 找到存储计算所需数据的 TiKV 地址,将SQL转换为TiKV的KV操作,与 TiKV 交互获取数据,最终返回结果。
TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展。 TiDB Server 类似Kylin中的QueryServer。
3 Placement Driver
Placement Driver 主要有以下职责:
- 集群的元信息 (某个 Key 存储在哪个 TiKV 节点)
- TiKV 集群进行调度和负载均衡
- 分配全局唯一且递增的事务 ID
3 TiDB的理论背书
- Google Spanner: 最主要的特性就是支持跨行事务和在分布式场景上实现 Serializable 的事务隔离级别. TIKV主要参考此篇论文实现。
- F1: A Distributed SQL Database That Scales: 基于Google Spanner实现的NewSQL数据库, F1论述了Spanner上层的分布式SQL层怎么实现,分布式的Plan怎么生成和优化,TIDB主要参考此篇论文实现。
- Raft: TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。
- Online, Asynchronous Schema Change in F1:TiDB的在线Schema变更主要参考此篇论文实现。
- Google Percolator: 经过优化的 2PC 实现,依赖一个单点的授时服务 TSO 来实现单调递增的事务编号生成,提供 SI 的隔离级别. TIKV的事务主要参考此篇论文实现。
4 TiDB的应用场景
4.1 Replace Mysql

相比Mysql,TiDB 可以做到横向扩展,高可用。 此外,由于TiDB兼容Mysql协议和绝大多数Mysql语法,在大多数情况下,用户无需修改一行代码就可以从Mysql无缝迁移到TiDB。这也是目前TiDB在业界最广泛的应用场景。 下图是几个业界的典型应用:

4.2 Replace HBase

相比HBase, TiDB 可以很好地支持SQL, 支持事务,支持二级索引,没有Java GC的痛点(TiKV是由Rust开发,Rust可以完全手动控制内存,无GC)。所以我认为TiDB可以代替掉HBase。 下图是几个业界的典型应用:

4.3 TiDB for OLAP
TiDB的设计目标是同时很好的支持OLTP和OLAP,但是从公开的测试结果来看,TiDB的OLAP性能一般,不如现在专门的OLAP系统(Kylin, Druid,Palo,ClickHouse等),在业界实践中,大多数公司都会引入TiSpark来解决OLAP问题。
从OLAP视角来看,TiDB的优点如下:
- 兼容Mysql协议和语法
- 实时和离线数据导入
- 支持聚合,明细,点更新
- 在线Schema变更
- 易运维
- Both OLAP And OLTP
从OLAP视角来看,TiDB的缺点如下:
- 无列式存储
- 无预计算手段
- 无向量化执行
4.4 TiDB for 实时数仓
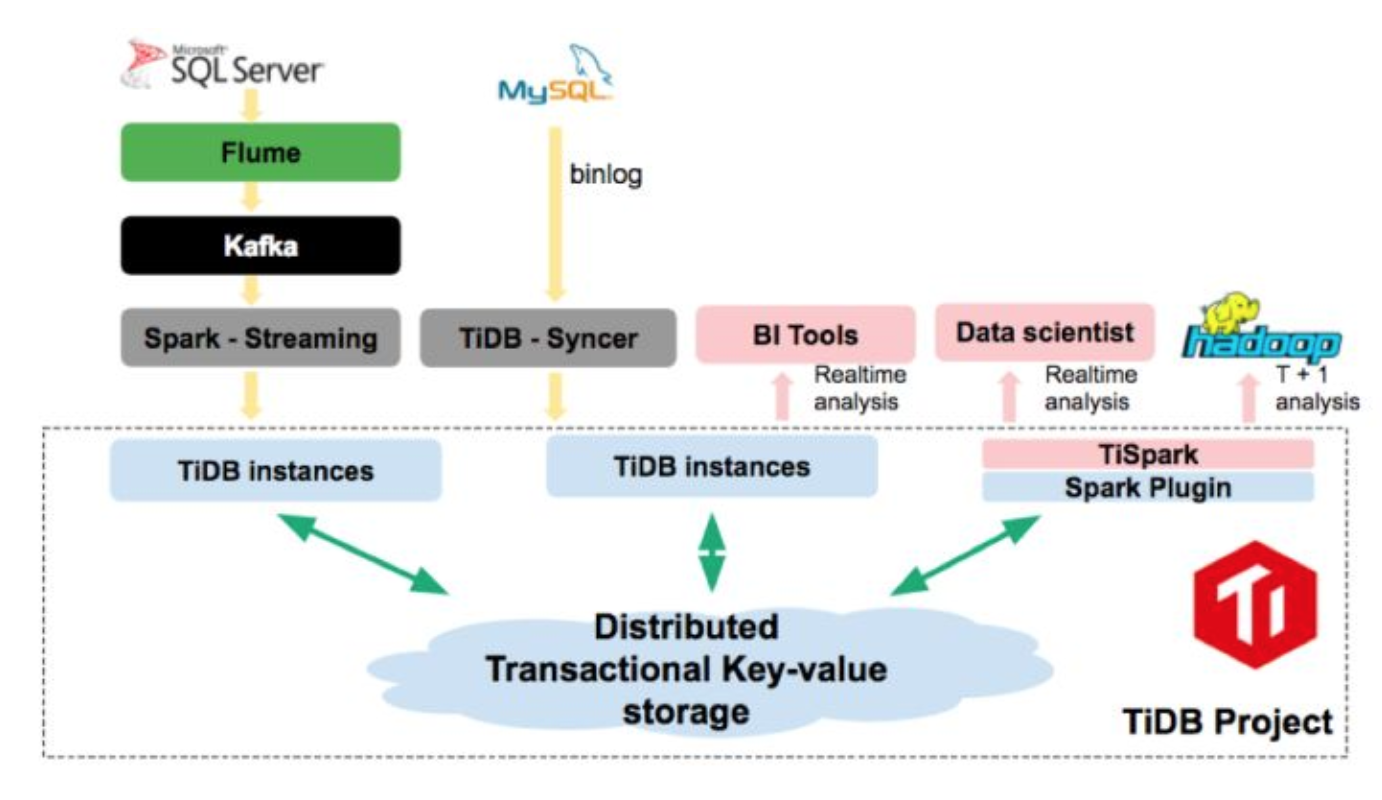
上图是易果集团实时数仓的架构图,上游OLTP的数据和其他的实时数据可以实时写入TiDB,下游OLAP的业务可以通过 TiDB或者TiSpark实时进行分析, 并且可以通过TiSpark将实时和离线整合起来。
4.5 Data Ecosystem Based On TiDB (In the future)
以下的畅想(胡思乱想) 需要TiDB未来能做到以下两点:
- 高效的OLAP查询
- 高效的批量写入
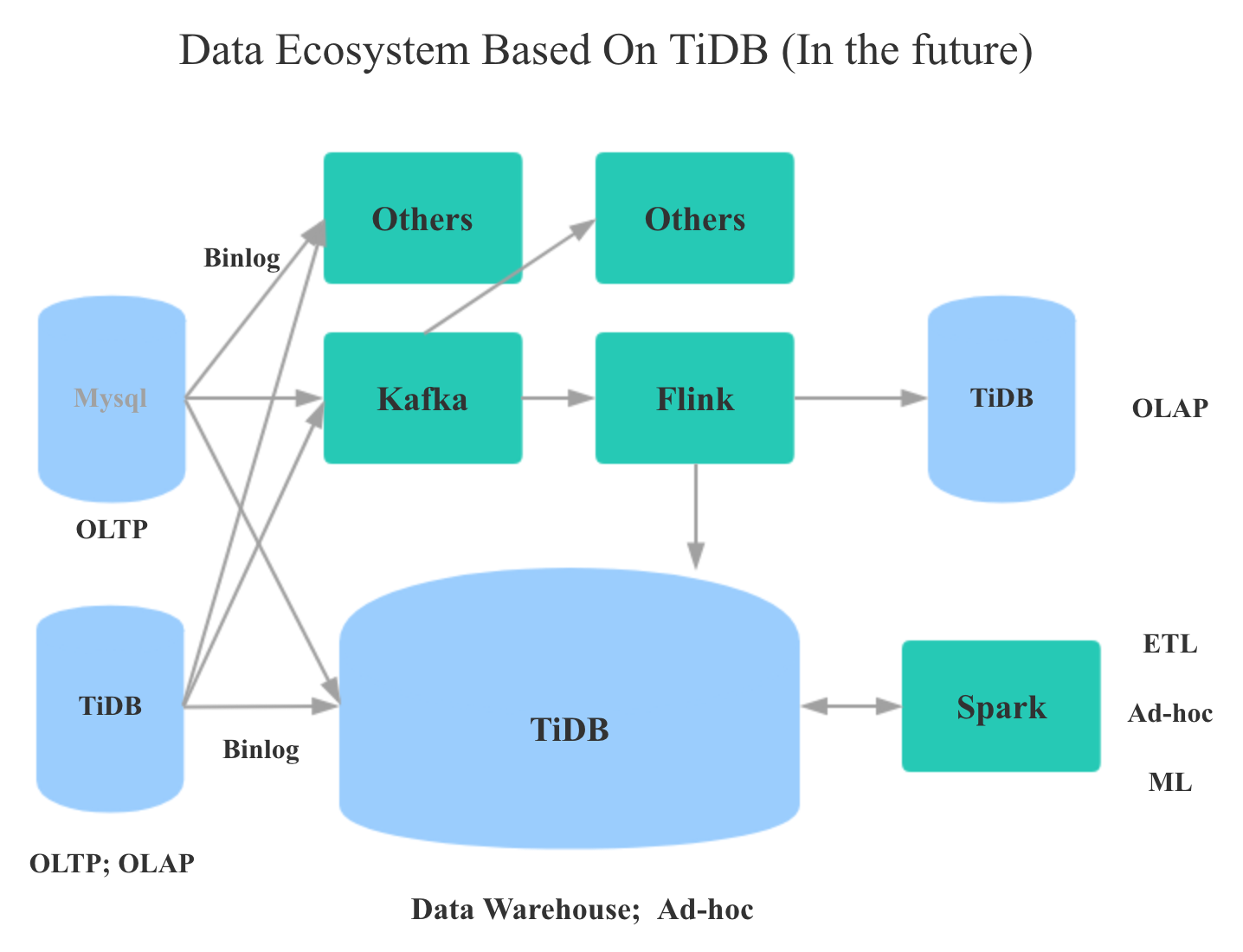
上图的含义如下:
- 最上游让Mysql和TiDB支撑在线OLTP和部分在线OLAP业务。
- 通过实时的Binlog同步将数据同步到下游,下游可以是基于TiDB的数仓,也可以是Kafka,还可以是其他系统,比如数据实时同步到ES做全文检索。
- Kafka的数据可以被任意下游消费,一种数据流是经过Flink等实时计算引擎进行ETL处理后,导入TiDB进行OLAP查询。
- 基于TiDB的数仓可以提供历史数据的Ad-hoc查询,也可以通过Spark进行ETL,ML,Ad-hoc查询。
- 所有结构化数据的查询都可以交给TiDB,非结构化数据的处理和查询交给Spark。
上图基于TiDB的Data Ecosystem相比于现在基于Hadoop的Data Ecosystem具有以下优点:
- 减少数据冗余,节省存储成本:现在有些数据可能在Mysql, Hive, OLAP系统中都有1份,其原因就是Mysql和Hive的查询效率低下,而在TiDB中,我们有可能只需要一份数据,如果TiDB能同时很好的支持OLTP和OLAP。
- 更精简的ETL流程:由于TiDB拥有OLTP和OLAP能力,现在许多以聚合,过滤为主的ETL就不需要做了。
- 更少的系统维护,更低的运维成本:如果我们基于TiDB构建数据仓库且TiDB能同时很好的支持OLTP和OLAP,那么Mysql,Hive,HBase,Presto,Kylin,Druid等系统理论上都可以被TiDB替换掉,并且可以实现结构化数据查询的接口大一统。
- 更高的开发效率:如果TiDB能同时很好的支持OLTP和OLAP,那么实现OALP需求,用户的开发成本就会低很多,甚至无需开发。
- 更低的学习成本:TiDB只要用户懂SQL就可以轻松的用起来,但是目前的Hadoop生态系统繁杂,概念众多,用户的学习成本和上手成本都较高。
5 TiDB HTAP 演进之路
那么我们可以通过哪些方法来加强TiDB的OLAP能力,使其成为一个真正的HTAP数据库呢?在介绍HTAP的演进之路前,我们先简介下行存和列存的优缺点和适用场景。
5.1 行存的优缺点和适用场景
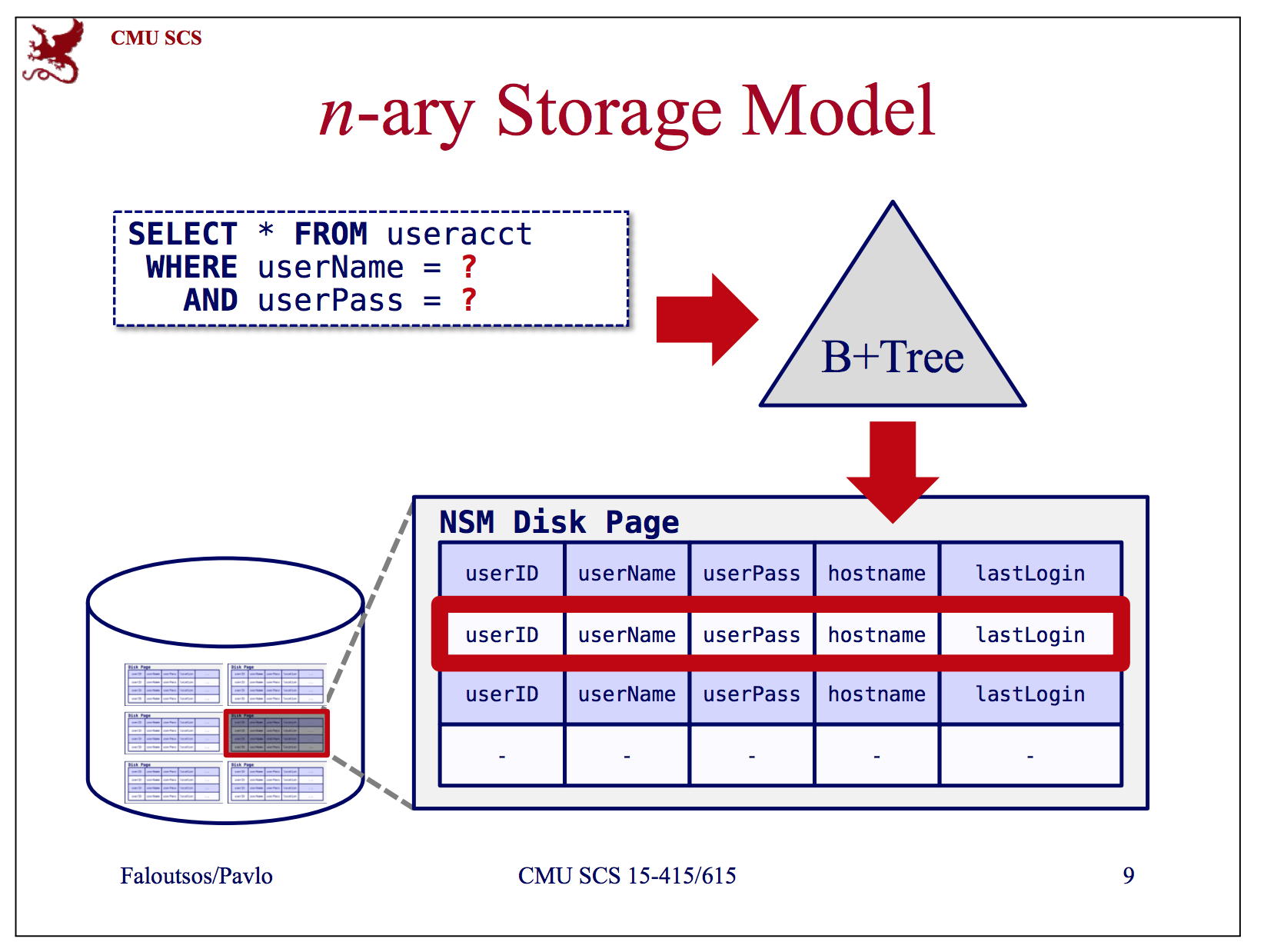
上图是个行存的示意图,就是数据按行组织,查询时按行读取。行存在学术论文中一般简称为NSM(N-ary Storage Mode)。
行存的优点如下:
- 适合快速的点插入,点更新和点删除
- 对于需要访问全部列的查询十分友好
行存的缺点如下:
- 对需要读取大量数据并访问部分列的场景不友好
所以行存适用于OLTP场景。
5.2 列存的优缺点和适用场景
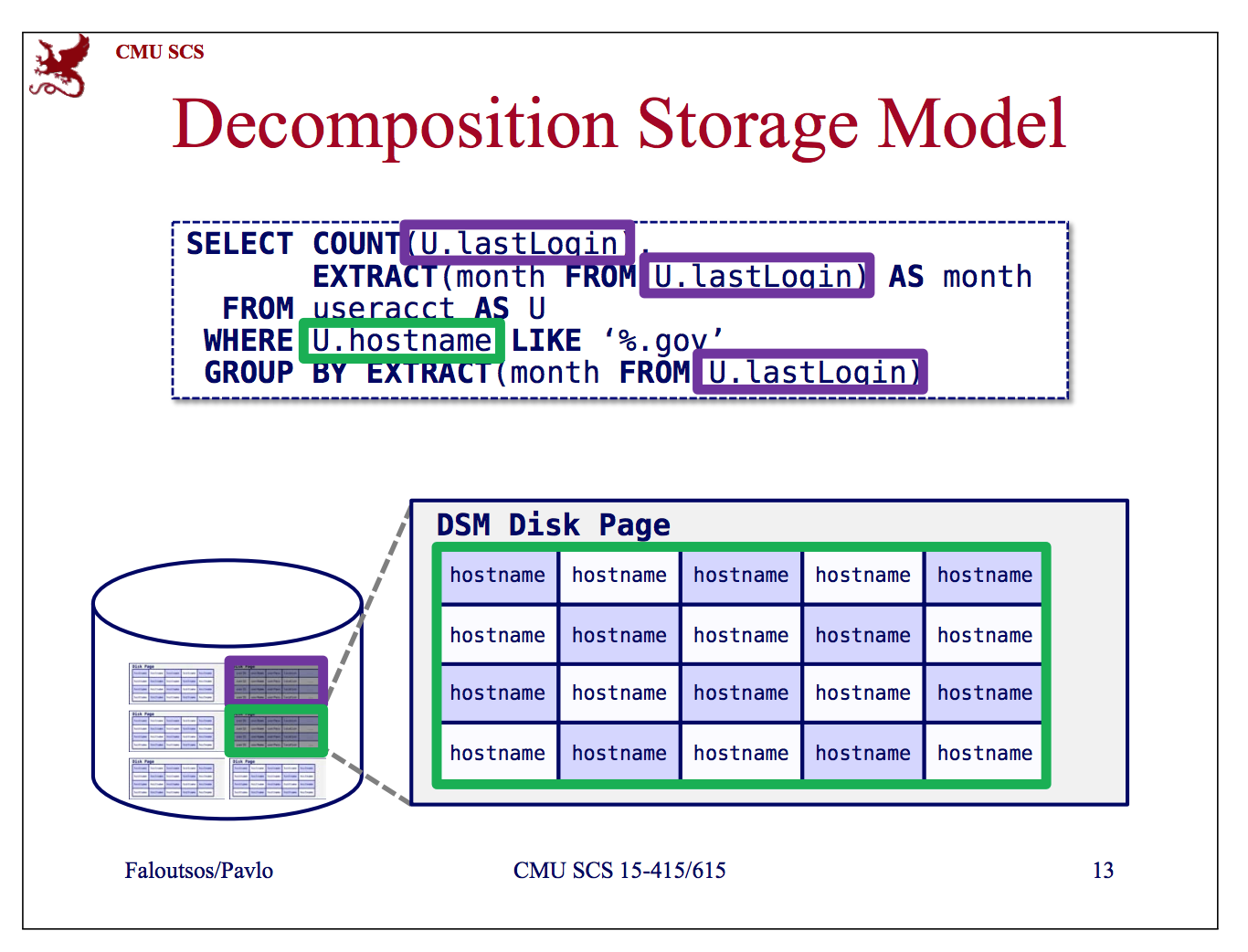
上图是个列存的示意图,就是数据按列组织,每列的数据连续存放在一起,查询时按列读取。 列存在学术论文中一般简称为DSM(Decomposition Storage Model)。
列存的优点如下:
- 只读取部分列时,可以减少IO
- 更好的编码和压缩(由于每列的数据类型相同)
- 更易于实现向量化执行
列存的缺点如下:
- 不适合随机的插入,删除,更新。(多列之间存在拆分和合并的开销)
所以列存适用于OLAP场景。
5.3 TiDB HTAP 演进之路——行列转换
现在我们已经知道了OLTP需要行存,OLAP需要列存,OLTP一般是查询较新的数据,OLAP一般是分析历史数据,所以要想同时很好地支持OLTP和OLAP,我们一个很自然的思路就是进行 行列转换,对于较新的数据使用行存,对于历史数据使用列存。 如下图所示:
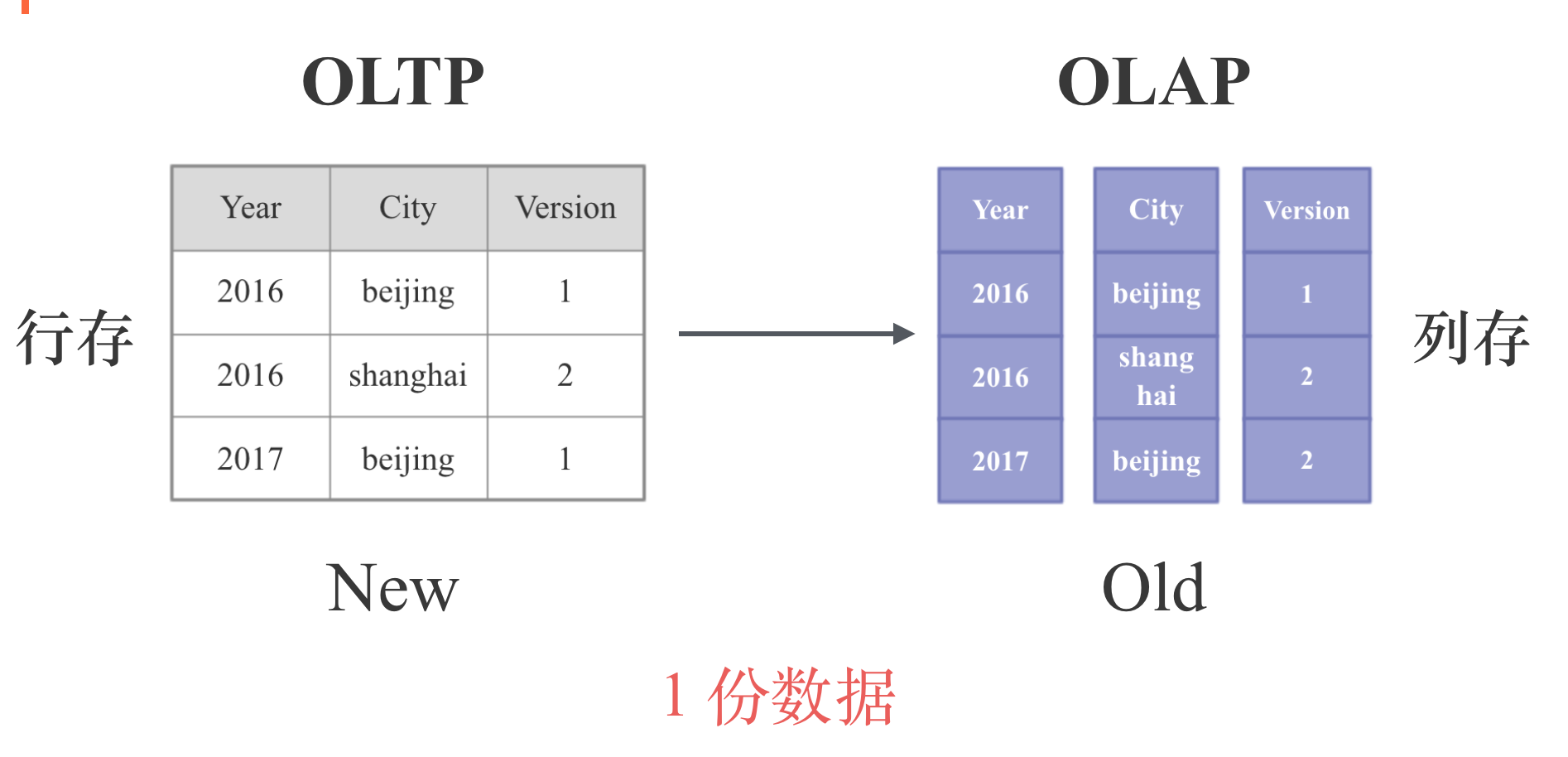
这种实现的难点就是如何确定一份数据什么时候由行存转为列存,此外,由于要支持点的更新和删除,必然要支持Compaction。Kudu, Druid采用了类型的思路。
5.4 TiDB HTAP 演进之路——行列混存 Spanner
上面的行列转换,是要维护两套独立的存储格式,有没有可能只用一种存储格式呢? 答案是可能的,就是行列混存。

上图是Spanner采用的行列混存方案,具体来说,就是将一个Page拆成多个Mini Page, 一列对应一个Mini Page,第一列放在第一个Mini Page,第二列放在第二个Mini Page,以此类推。在每个Page 的开头,会存放每个Mini Page的Offset。 好处是:当要依据某一列进行 Scan的时候,我们可以方便的在Mini Page里面顺序扫描,充分利用 Cache;而对于需要访问多列得到最终tuple的场景,我们也仅仅需要在同一个Page里面的Mini page之间读取相关的数据。
更多信息可以参考 PAX:一个 Cache 友好高效的行列混存方案
5.5 TiDB HTAP 演进之路——行列混存 Peloton
CMU的开源数据库Peloton中采用了另一种行列混存思路,如下图所示:
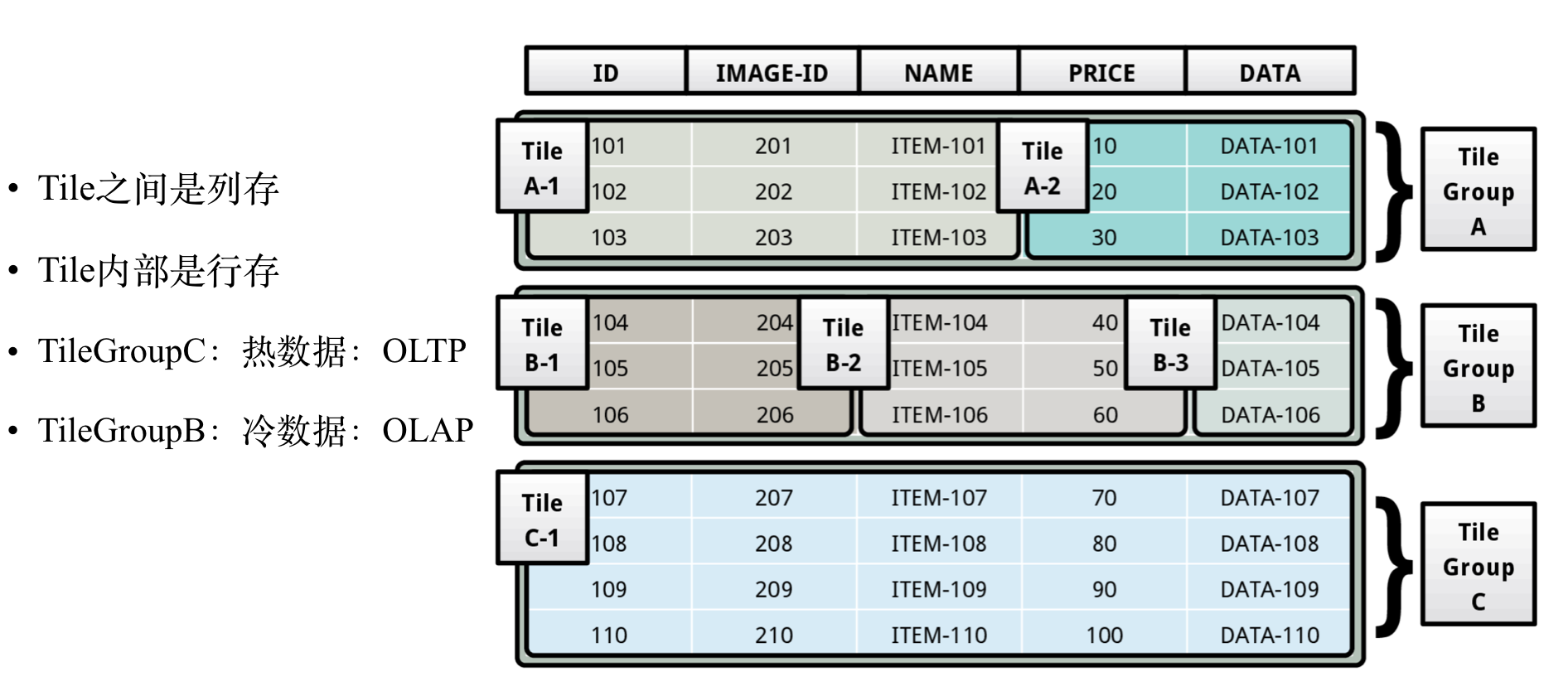
Peloton项目基于Tile来实现行列混存, Tile之间是列存,Tile内部是行存。一个Table有多个Tile Group组成, 一个Tile Group可以包含多个Tile。热数据可以存放到OLTP友好的Tile Group中,也就是一个Tile Group里面只有一个Tile,当数据变冷之后,可以将Tile Group 转成对OLAP友好的布局,也就是Tile Grou里面可能有几个Tile了。当Tile Group里面每个Tile都只有一个Column的时候,就变成完全的列存了。 有没有感到Tile的概念和HBase的Column Family很像。
更多信息可以参考 基于 Tile 连接 Row-Store 和 Column-Store
5.6 TiDB HTAP 演进之路——TiDB On ClickHouse
我们知道TiDB在OLAP场景下缺乏一个列式存储,而ClikcHouse是目前已知的单机性能最强大的开源OLAP数据库,但是其在分布式化上做的很差。So,Maybe 我们可以整合TiDB和ClickHouse,用ClickHouse填补TiDB在OLAP场景下的短板,用TiDB填补ClickHouse在分布式,运维性,易用性上的短板。
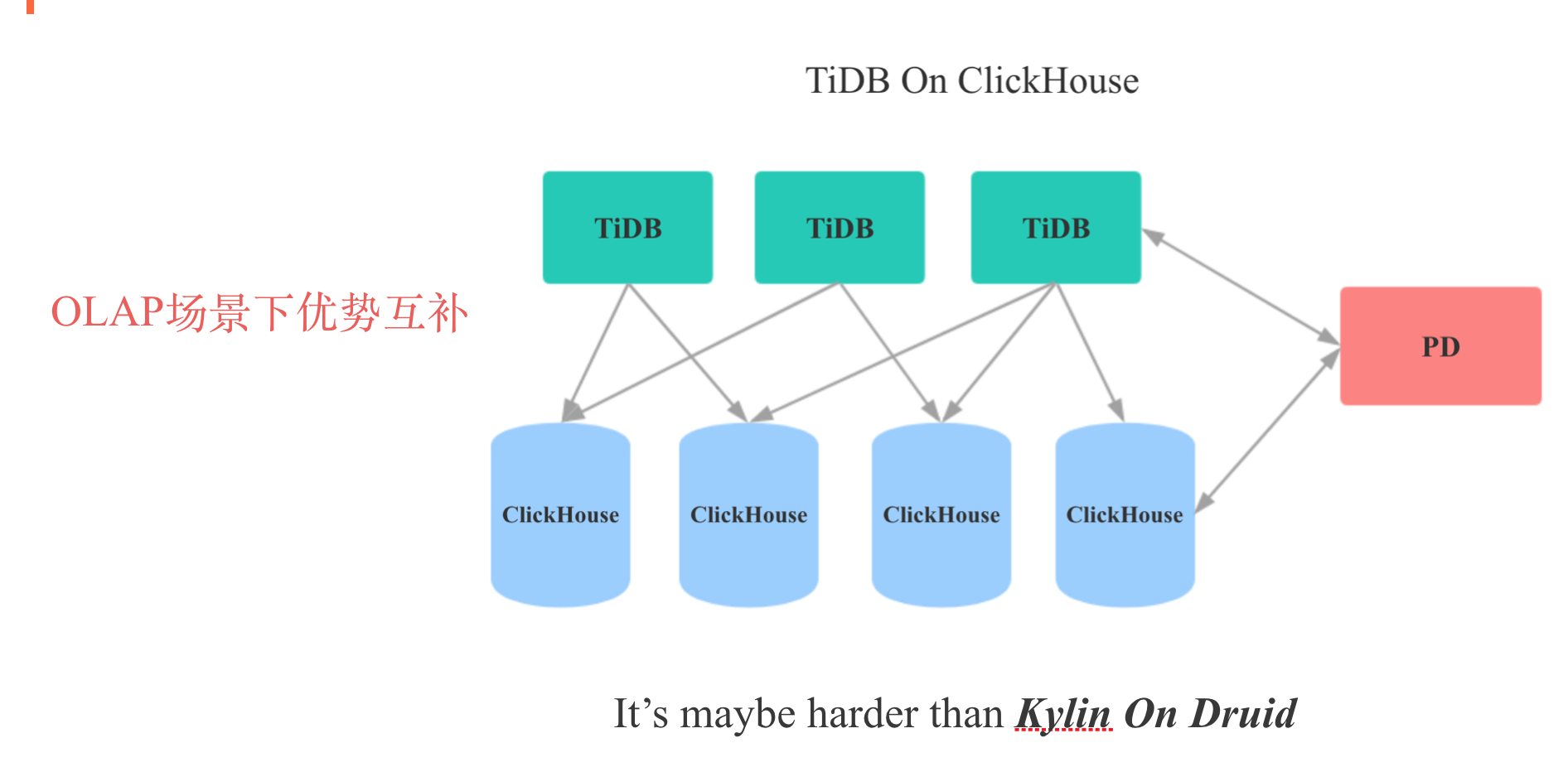
简单调研TiDB和ClickHouse的接口后,我们会发现,理想是美好的,现实是残酷的,真要做TiDB On ClickHouse的话,TiDB和ClickHouse两边都需要做大量的改动。
6 总结
本文简介了Why TiDB的What TiDB,没有讲How TiDB(对于实现细节感兴趣,可以阅读TiDB官方文档,论文和源码), 主要畅想(胡思乱想)了下TiDB的应用场景和HTAP演进之路。 个人比较看好TiDB的未来,TiDB能否拥有更广阔前景的关键就是OLAP能力的强弱。
7 参考资料
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
