Apache Kylin On Druid Storage 原理与实践
作者: 康凯森
日期: 2017-11-04
分类: OLAP
- 预备知识
- Why Kylin on Druid Storage
- How Kylin on Druid Storage
- Kylin on Druid Storage VS Kylin on HBase
- The roadmap for Kylin on Druid Storage
- 总结
- 参考资料
本文主要介绍Apache Kylin On Druid Storage 的原理与实践,读完本文,你将get以下几点:
- 如何为Kylin新增一种存储引擎
- 如何为Druid添加新指标
- 如何生成Druid Segment
- 如何直接查询 Druid Segment
- Kylin构建和查询时的数据格式转换
- Kylin on Druid Storage VS Kylin on HBase 单机版性能对比
预备知识
What is Kylin
Kylin 是一个基于Hadoop生态系统的OLAP系统,其核心思想是预计算:将经常查询到的维度组合下的指标预先计算出来,查询时就可以直接获取最终的结果值。这样就可以显著加速模式固定的OLAP查询。
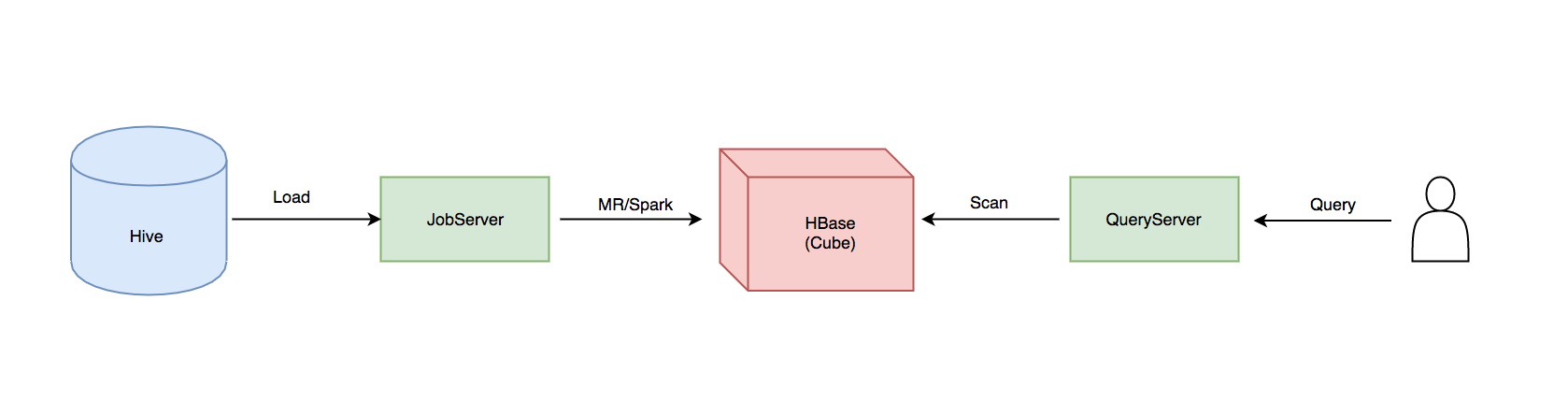
如上图所示,整个Kylin分为两个部分,即预计算部分和查询部分。预计算部分对应上图的左边,将Hive中的数据按照指定的各种维度组合(Kylin中1种维度组合称之为1个Cuboid)进行计算,生成Cube,将结果存储在HBase中,Kylin中负责预计算部分的节点是JobServer;查询部分对应上图中的右边,Kylin的QueryServer接受用户的SQL,依靠Calcite进行解析和优化,生成逻辑计划,最终根据Cuboid和Filter生成HBase的Scan,从HBase获取到结果后,再交给Calcite进行最终的计算。
关于预计算部分的详细原理可以参考:Apache Kylin Cube 构建原理, 查询部分的详细原理,有空会再写篇文章。
Kylin 构建时的数据格式转换
注: 括号里是相关的类
- 首先从Hive大宽表中获取每一列的值,会用HCatRecord将Hive中的每1列转为String (HiveToBaseCuboidMapper)
- 先对所有的维度列进行编码得到1个byteArray,byteArray的内容是cuboid+每个维度编码后的值。Kylin中维度的主要编码方式是字典编码,此外还有定长编码和整形编码。(BaseCuboidBuilder)
- 再将所有指标列按照每种指标自己的Serde方法序列化到一个ByteBuffer中。(BaseCuboidBuilder)
- 最后将byteArray格式的维度和指标转换为HBase的KeyValue格式。Kylin中的Cuboid+维度值是HBase的Rowkey,指标是HBase中每列具体的值。(CubeHFileMapper)
Kylin 查询时的数据格式流转
注: 括号里是相关的类
- QueryServer根据查询的Cuboid和Filter拼出HBase的Scan (CubeScanRangePlanner)
- HBase Scan得到相应的KeyValue (InnerScannerAsIterator)
- 将KeyValue 转化为GTRecord,GTRecord包含一个ByteArray,来存储所有维度列和指标列 (HBaseReadonlyStore)
- GTRecord将ByteArray写入到ByteBuffer中 (CubeVisitService)
- 所有结果转为一个大的ByteArray返回到Kylin的QueryServer(CubeVisitService)
- 将ByteArray 转为GTRecord (StorageResponseGTScatter,PartitionResultIterator)
- 将GTRecord 转化为 Object[] (SegmentCubeTupleIterator)
- Object[] 数组 传给 Calcite (OLAPEnumerator)
What is Druid Storage
如果你不了解Druid或者Druid Storage, 请参考 Druid Storage 原理
Why Kylin on Druid Storage
从前面的介绍我们知道,Kylin的查询稳定性和性能严重依赖HBase的稳定性和性能,那么HBase在Kylin的使用场景下有哪些问题呢?
- HBase只能根据Rowkey进行Scan,非前缀过滤的性能极其低下
- Kylin依赖了HBase的Coprocessor机制,这直接决定了Kylin不能提供3个9的查询可用性。因为更新Coprocessor必然影响线上查询,而更新Coprocessor十分费时(即使我将之前的串行更新改为并发更新),数千张HBase表的更新耗时在小时级
- HBase故障恢复时,Region的重新分配耗时较长(即使调大openregion线程数),近10万Region的重新分配需要数十分钟,这也决定了Kylin很难提供3个9的查询可用性。
- Kylin无法作为数据仓库生产的上游,因为无论是Kylin在HBase的HFile数据,还是Kylin在HDFS上的Cuboid数据,都无法被其它系统直接读取。
综上,我们知道HBase显然不是Kylin的最佳存储引擎,那么为什么会选择Druid呢?
- Druid Storage是列式存储,能够实现查询的投影下推,避免访问不需要的数据
- Druid Storage对维度字段建立倒排索引,从而可以快速过滤
- Druid Storage本身就是针对OLAP场景设计的,已经被Druid这个业界广泛使用的OLAP系统进行了验证
How Kylin on Druid Storage
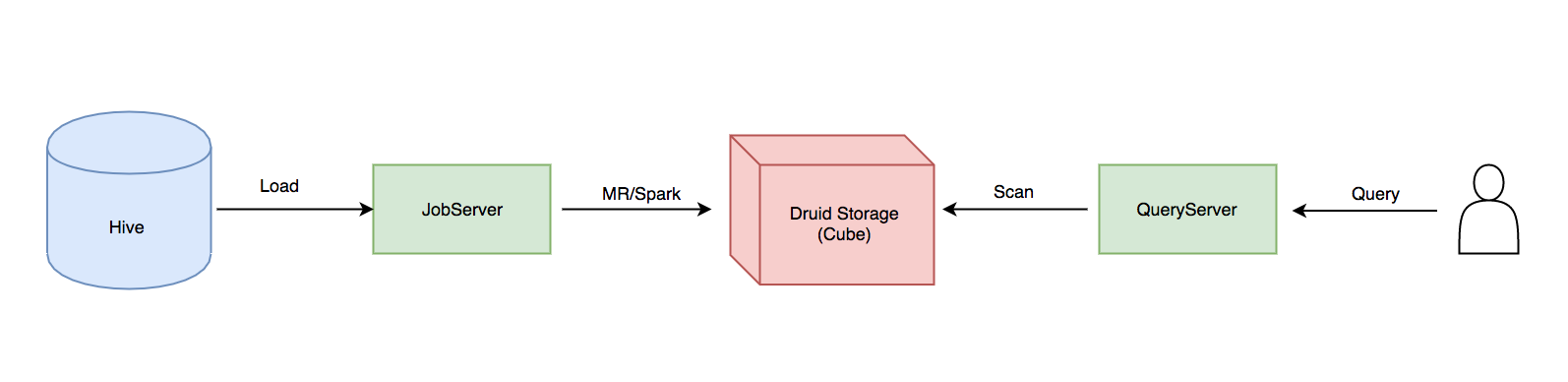
如上图所示 所谓的Kylin on Druid Storage 就是用Druid Storage 替换 HBase,我们的目标是在单机环境下替换掉HBase,显然我们在Kylin的Cube 构建部分和查询部分都需要修改。
1 Druid新增Binary指标
在Druid Storage 原理中,我介绍过Druid的指标支持Long,Float,Complex 3种指标,所以为了将Kylin中精确去重和近似去重等复杂指标映射到Druid中,我们需要在Druid中新增一种Binary指标,来存储Kylin一些复杂指标serialize后的byteArray。
在Druid中新增一种指标的方法和Kylin类似,只需要实现ComplexMetricSerde,Aggregator, BufferAggregator, AggregatorFactory 4个接口:
- ComplexMetricSerde 用于定义一个指标如何Serde。
- Aggregator 用户定义一个指标如何执行聚合
an Aggregator can be thought of as a closure over some other thing that is stateful and changes between calls to aggregate
- BufferAggregator 是Aggregator的替代品,是Aggregator的Buffer版本
- AggregatorFactory 定义指标的名称,获取具体的Aggregator。
2 Kylin 构建侧修改
构建侧需要修改或添加3个步骤:
CalculateShardsStep
类似CreateHTableJob,需要估算每个cuboid的分片数,决定生成Druid时的Reducer个数。
- ConvertToDruidJob
Partitioner:根据Shard id进行分区。
Reducer:将Kylin的Cuboid转为Druid的Segment:
1. 将Kylin的维度decode为String,将Long,Float,Double,BigDecimal指标decode为原始值,其他复杂指标依旧保持byteArrayg格式
2. 将Kylin的Cuboid,维度,指标拼接成Druid的InputRow
3. 将InputRow加入到IncrementalIndex中
4. 在Cleanup阶段将内存中的Row持久化,并上传到HDFS
- PullDruidIndex 将Druid文件从HDFS拉取到Kylin JobServer本地
3 查询侧修改
主要是实现IGTStorage,通过Druid的底层API QueryableIndexStorageAdapter.makeCursors 直接读取Druid文件,将结果转换成Object数组返回给Kylin的查询引擎Calcite。在实现过程中,进行了投影下推和谓词下推:
- 投影下推:通过Cuboid和ScanRequest.aggrMetrics得到需要从Druid读取的列
- 谓词下推:将Kylin ScanRequest中的TupleFilter转换为Druid的Filter,其中 将逻辑运算符And,Or,Not和比较运算符=,<=, >=, in进行了转换。
4 移除Kylin查询时的核心数据结构GTRecord
前面提到过,我们在Druid中存储的是String, Float,Long等原始值,如果我们将Druid返回的数据和HBase一样继续封装为GTRecord的话,我们首先要将原始值decode为ByteArray,之后Kylin将GTRecord转化为Tuple的时候,还需要将ByteArray encode为原始值。所以为了避免这种完全没有必要的编解码,我就将Druid返回的数据直接转为Tuple中的Object数组。
为了将GTRecord在查询时移除,我们需要做两件事情:
- 建立GTindex到TupleIndex的映射。
- 将IGTScanner的接口中的GTRecord改为Object[],并对其所有实现类进行删改。
Kylin on Druid Storage VS Kylin on HBase
我们重点关注查询性能,主要测试了全表Scan,前缀过滤,后缀过滤3种Case,每种Case下测试了1个指标,11个指标,21个指标,41个指标。 (我们知道Kylin是将多个维度拼接成HBase的RowKey的,所以维度必然有顺序,前缀过滤是指我们按照Rowkey中靠前的维度去过滤,后缀过滤是指按照Rowkey中靠后的维度去过滤)
测试的Cube: 6.7亿行原始数据,16个维度,41个简单SUM指标,无分区列。
测试的方法: 测试HBase Scan性能时将Kylin查询的StorageSideBehavior设置为Scan,测试HBase过滤性能时,将StorageSideBehavior设置为SCAN_FILTER。
注:由于是对比单机版性能,所以Druid的实现是串行去读取每个segment文件,我们计算查询耗时时,Druid的耗时就是串行读取的时间,HBase的耗时是将多个Region的耗时相加。
由于采用的测试样例不是标准的测试数据集,所以就不罗列测试的具体SQL,测试结论也不给出定量的结论,因为意义不是很大,只给出定性结论:
- HBase的过滤性能几乎不会随着访问列数的增加而变化(Kylin的指标都在HBase的同一个列族的同1列)
- Druid的过滤性能会随着访问列数的增加而大致成线性下降 (Druid需要单独访问每列,再拼接成1行)
- Druid 针对任意列的过滤表现都一致 (Druid对每个维度列都有倒排索引,每个维度列的地位都是等同的;HBase测试越靠前的维度过滤性能越好,因为HBase是前缀匹配)
- 相同列数下,过滤的行数越多,Druid相比HBase的优势越明显 (Druid可以基于倒排索引快速过滤,不会访问无关的行,但是HBase只能Scan,过滤的行数越多,HBase就要Scan更多无关的行)
- 在前缀过滤场景下,当访问的Value数(访问的列数 X 过滤后的行数)小于3亿时 (这个值是我根据多组测试结果估计出来的)Druid的过滤性能都要比HBase好。
- 在后缀过滤场景下,Druid几乎是碾压HBase。
综上,我们可以得到最终结论,Druid Storage比HBase更适合作为Kylin的存储。
The roadmap for Kylin on Druid Storage
整合Kylin和Druid
Kylin和Druid作为两款优秀的OLAP系统,各有优劣,Kylin在SQL接口,Web UI, 离线导入, 权限等做的更好,Druid在存储层,实时摄入做的更好,所以我们可以将两者的优点结合。 我们在实现Kylin on Druid Storage 单机版后,借助或参考 Druid的Historical,Coordinator, Broker服务,不难实现分布式版本。
整合Kylin,Druid Storage和Spark
我们可以仅仅只使用Druid的Storage部分,然后可以参考 When TiDB Meets Spark 整合Kylin,Druid Storage和Spark。
总结
本文主要介绍了Kylin On Druid Storage的What,Why 和How,显然,我忽略了很多细节和期间踩过的坑,因为这不重要,重要的是大家通过阅读本文能够知道如何为Kylin新增一种存储引擎。
参考资料
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
