论Apache Kylin SQL中数据类型的重要性
作者: 康凯森
日期: 2018-04-13
分类: OLAP
本文主要通过Apache Kylin线上查询机大量线程Blocked Case的分析过程,说明下在Kylin中SQL使用正确数据类型的重要性,最后再通过我近期解决的一些实际问题,来简单总结下计算机工程师解决问题的常规思路和手段。
背景
4月9号的时候,我们一个线上独立查询集群收到Http请求500异常的报警,用户也反馈查询严重超时。 当时首先看了下监控的Dashboard,发现Kylin QueryServer的Kylin.TomcatRequest.processingTime指标 异常升高,但是内存,CPU使用正常,GC情况也正常,说明不是常见的大查询引起的OOM,之后我就登录线上机器,发现耗时20多秒的查询请求HBase很快,只有几ms,但是在service.QueryService:356到routing.QueryRouter:56之间足足耗时21s,根据以往的经验来看,应该是Calcite又有问题。于是决定留下Jstack,先重启机器,恢复服务。
Jstack 分析
分析Jstack后发现,大量线程Block在WebappClassLoaderBase loadClass的地方:
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1735)
- waiting to lock <0x0000000580000688> (a org.apache.kylin.ext.CustomizedWebappClassloader)
at java.lang.ClassLoader.loadClass(ClassLoader.java:411)
- locked <0x00000004e829dfd8> (a org.codehaus.janino.ByteArrayClassLoader)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.codehaus.janino.ClassBodyEvaluator.compileToClass(ClassBodyEvaluator.java:319)
而锁0x0000000580000688被RUNNABLE的线程持有
java.lang.Thread.State: RUNNABLE
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1844)
- locked <0x0000000580000688> (a org.apache.kylin.ext.CustomizedWebappClassloader)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1701)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.codehaus.janino.ClassLoaderIClassLoader.findIClass(ClassLoaderIClassLoader.java:78)
at org.codehaus.janino.IClassLoader.loadIClass(IClassLoader.java:254)
- locked <0x00000004e20fec68> (a org.codehaus.janino.ClassLoaderIClassLoader)
grep了下发现,等待0x0000000580000688这个锁的线程有93个之多。 所以现在查询线程blocked的原因找到了,但是为什么会有大量的查询线程需要loadClass,loadClass为什么耗时很久还不清楚。
当时简单谷歌了一下,找到了两个比较相关的问题:
根据这两个Jira,我判定问题很大可能和Calcite有关系。 但是我们是第一次遇到这个问题,而且是两年来第一次遇到,同时我们其他多个查询集群从来没有发生过这个问题,所以我感觉这个问题触发的概率应该很低,同时考虑到即使出了问题我们也可以快速恢复服务,就不准备深究这个问题,因为其他优先级很高的事情很多。
问题复现
但是4月11号这个问题又出现了,说明了这不是一个低概率事件。但是为什么只有一个查询集群有这个问题呢?开始怀疑是不是用户的SQL最近有什么改动,导致这两天出现了这个问题,但是和用户确认后,SQL最近并没有改动。 我也分析了多个导致线程阻塞的SQL,十分简单,并没有什么特别的地方:
select id ,sum(price) from Table where id IN (14976,1673,21002,1676,20749,21645,17294,21646,17679,17039,17680,17296,17297,15634,21523,1427,2071,17691,17692,17693,17695,21407,21408,17697,16547,17704,14633,17705,14636,14637,15150,17327,21296,1841,2100,17079,17080,16186,1471,16066,21571,16579,21572,21573,14662,21194,21328,17106,2003,21715,21716,21717,17110,21718,1879,15832,21209,14686,17249,1890,16738,15075,17252,21860,21615,17784,21625,17786,21498,21499,17532,1662) and dt_name >=20180401 and dt_name < 20180410 group by id
我们从WW-3902可以推测这个问题很可能和并发有关。 不过有两点和我已知事实矛盾的地方:
- 这个查询集群的并发并不是很高,QPS最高只到3。
- 我之前专门压测过Kylin,Kylin在高并发场景下由于Calcite的代码生成的确会有明显的性能下降,但是在并发30多时也没有出现线程阻塞。
但是当时也没有其他复现问题的好思路,所以还是决定先试下并发会不会导致这个问题。 于是用32的并发同时执行上面的SQL,比较幸运,问题直接复现了。
LoadClass 原理明确
我们现在已经确定这个问题是在高并发情况下WebappClassLoaderBase loadClass锁竞争导致的。所以在深入分析之前,我们需要先明确下WebappClassLoaderBase的原理,loadClass什么时候需要同步。
Kylin中使用的类加载器是CustomizedWebappClassloader:
<Loader loaderClass="org.apache.kylin.ext.CustomizedWebappClassloader"/>
CustomizedWebappClassloader继承自 ParallelWebappClassLoader,ParallelWebappClassLoader 继承自WebappClassLoaderBase,WebappClassLoaderBase继承自ClassLoader。 ParallelWebappClassLoader 是一个并发的类加载器,原理是通过调用Classloader.registerAsParallelCapable开启并发加载。这样类名不同的Class就可以并发加载,只有类名相同的Class才需要同步。
ClassLoader在加载类前需要先获取类加载的锁
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
这个是ClassLoader获取类加载锁的逻辑,可以看到,如果开启并发加载,不同的className会持有不同的锁。
protected Object getClassLoadingLock(String className) {
Object lock = this;
if (parallelLockMap != null) {
Object newLock = new Object();
lock = parallelLockMap.putIfAbsent(className, newLock);
if (lock == null) {
lock = newLock;
}
}
return lock;
}
同时WebappClassLoaderBase加载类的逻辑如下:
(0) Check our previously loaded local class cache
(0.1) Check our previously loaded class cache
(0.2) Try loading the class with the system class loader, to prevent the webapp from overriding J2SE classes
(1) Delegate to our parent if requested
(2) Search local repositories
(3) Delegate to parent unconditionally
所以我们知道一个应用程序中1个类只会加载一次,第二次加载时会从Cache中加载。
调试分析
搞清LoadClass的原理后,我们知道多个查询线程阻塞的原因应该是多个查询线程需要去加载同一个类,而且这个类应该加载的比较慢。 于是就决定调试下代码,同时考虑到很大概率和Calcite的代码生成有关系,就将calcite.debug设置为true。
根据Jstack文件,首先将断点设置到WebappClassLoaderBase的1844行。因为程序开始运行时需要加载的类肯定很多,所以我在跑了一遍上面的SQL后,正式开启debug。 debug过程中发现会多次加载org,Object,org/apache这样的类名,这样的类显然是不存在的,无法正确加载,于是根据堆栈分析,发现这些类是UnitCompiler.findTypeByName中产生的,再追,发现IClassLoader loadClass的逻辑如下:IClassLoader中对无法加载的类会有Cache unloadableIClasses。 其unloadableIClasses的内容如下:
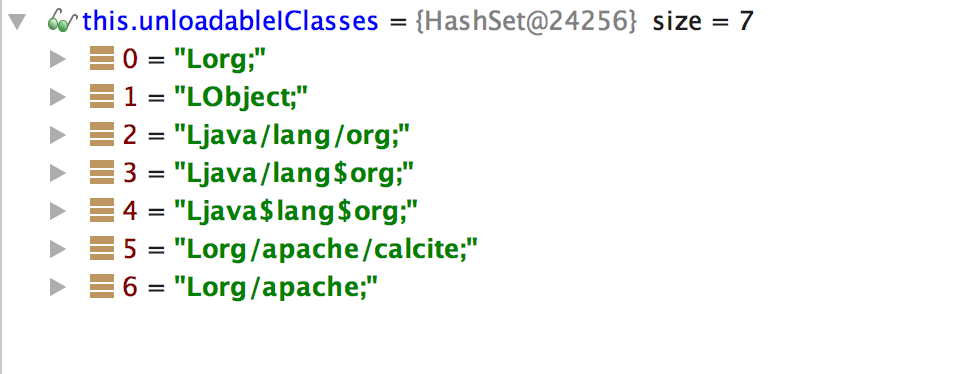 既然有Cache,这些类应该在WebappClassLoaderBase只会加载一次,但是debug中发现org这种类会出现多次。说明这个Cache不是全局的,再分析Jstack,猜测其应该是每个UnitCompiler会有一个。
既然有Cache,这些类应该在WebappClassLoaderBase只会加载一次,但是debug中发现org这种类会出现多次。说明这个Cache不是全局的,再分析Jstack,猜测其应该是每个UnitCompiler会有一个。
IClass result;
synchronized (this) {
// Class could not be loaded before?
if (this.unloadableIClasses.contains(fieldDescriptor)) return null;
....
....
....
if (result == null) {
this.unloadableIClasses.add(fieldDescriptor);
return null;
}
}
这时候我去看了这个SQL对应的Calcite生成的代码,发现了大量的:
/* 1 */ public Object[] apply(Object root0) {
/* 2 */ return new Object[] {
/* 3 */ org.apache.calcite.runtime.SqlFunctions.truncate(Integer.toString(14976), 256)};
/* 4 */ }
/* 5 */
/* 1 */ public Object[] apply(Object root0) {
/* 2 */ return new Object[] {
/* 3 */ org.apache.calcite.runtime.SqlFunctions.truncate(Integer.toString(1673), 256)};
/* 4 */ }
/* 5 */
/* 1 */ public Object[] apply(Object root0) {
/* 2 */ return new Object[] {
/* 3 */ org.apache.calcite.runtime.SqlFunctions.truncate(Integer.toString(21002), 256)};
/* 4 */ }
/* 5 */
这时候UnitCompiler, 大量apply代码片段, Integer.toString(xxx) 这几个因素,让我脑海中联想到问题莫非是和数据类型有关,于是在Kylin web上确认了下SQL中id和price的类型,的确是String。于是我就把SQL中的Int改成了String。用32的并发测试了下,果然没有了线程阻塞,而且每个查询的耗时比之前还短。
至此,我们整个问题的原因已经明确并同时有了解决方案。
刚才apply代码和UnitCompiler有关只是从代码命名和堆栈上的猜测,之后在代码中也确认了下,每个代码片段的确对应一个UnitCompiler。
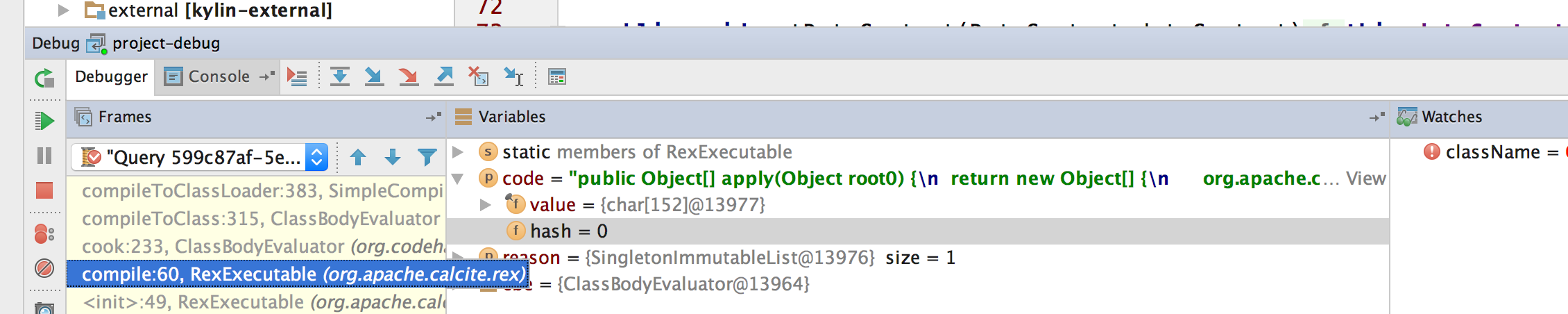
其代码中的调用链如下:
at org.codehaus.janino.UnitCompiler.compileUnit(UnitCompiler.java:320)
at org.codehaus.janino.SimpleCompiler.compileToClassLoader(SimpleCompiler.java:383)
at org.codehaus.janino.ClassBodyEvaluator.compileToClass(ClassBodyEvaluator.java:315)
at org.codehaus.janino.ClassBodyEvaluator.cook(ClassBodyEvaluator.java:233)
at org.apache.calcite.rex.RexExecutable.compile(RexExecutable.java:60)
这里还有一个问题,为什么Calcite会产生org,Object,org/apache等这样奇怪的,并不存在的类名。
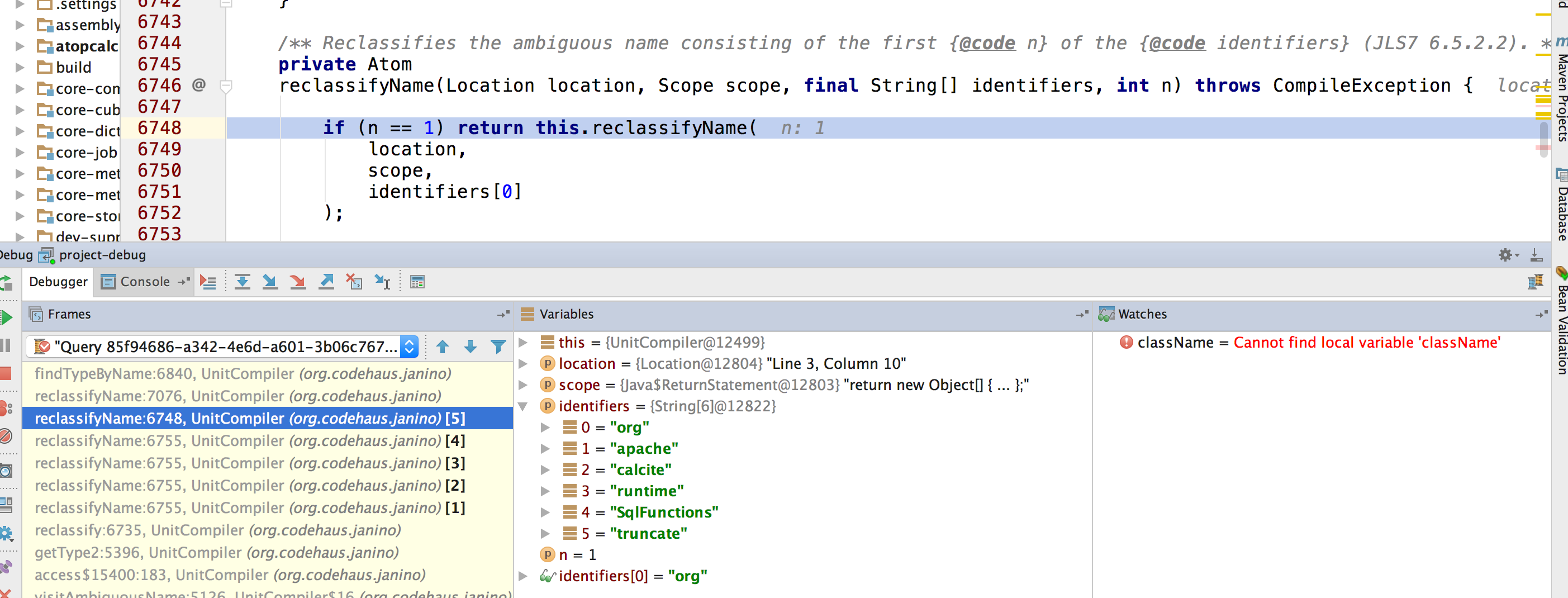
如上图,应该是UnitCompiler的reclassifyName(Location location, Scope scope, final String[] identifiers, int n)或者reclassifyName(Location location, Scope scope, final String identifier) 这个方法有Bug。对于org.apache.calcite.runtime.SqlFunctions.truncate这个方法,UnitCompiler会当成6个identifier,然后递归调用reclassifyName生成类名,但显然org,org.apache,org.apache.calcite并不是合法的类名。
逻辑链梳理
- Table中的id和dt_name都是String类型,但是在SQL中用户写的是Int
- SQL中大量的In导致Calcite生成的代码有大量的Integer.toString代码片段
- UnitCompiler在编译代码片段时会生成较多不合法的类名
- 由于不合法的类名每次都需要加载,1个SQL会生成30多个(甚至更多)代码片段,加上并发,就会造成相同类名的类在加载时争抢锁,一旦有一次处理的慢了,就会形成恶性循环,锁竞争越来越严重,进而形成90多个查询线程Blocked的情况,造成查询服务不可用。
Kylin中SQL 数据类型的重要性
- SQL中数据类型和实际类型不一致,在并发情况下很容易导致Kylin QueryServer 大量查询线程Blocked,进而导致查询服务不可用
- SQL中数据类型和实际类型一致,比不一致时的性能有明显提升。(具体提升多少就看HBase处理时间和Kylin QueryServer处理时间的占比,假如HBase的处理时间在几十毫秒左右,查询时延应该可以提升一个数量级,从几秒提升到几百毫秒)
如何排查和解决问题
我们计算机工程师在平时必然会遇到很多的线上,开发问题需要解决,下面我根据我最近解决一些问题的经历,浅谈下我们解决问题的常规思路和手段,想的时间比较短,不是很完善:
1 确认真实的代码和你预期的代码是完全一致的
相信大家都经历过分析了大半天问题,最终发现代码没更新的情况。 预防这种问题可以在代码仓库或者发布系统中中加上Commit号,这样我们就可以快速判断我们的代码版本是否正确,但是这个措施只能保证我们当前系统的代码是没有问题的,并不能保证我们系统依赖的其他系统代码也是最新的。
例如:我在开发Kylin On Druid POC时,需要先修改Druid代码,发布到我们公司Maven仓库,然后再编译Kylin代码进行发布。 开始测试时我发现改的Druid代码有Bug,就更新发布Druid代码后,再重新编译发布Kylin代码,但是我发现更新后还是有问题,开始我一直以为是我改的Druid代码逻辑有问题,反复确认几次后,想到先确认下代码到底是不是最新的。最后经过Google后才明确,Maven对于SNAPSHOT的依赖库并不保证每次都下载最新版本的,需要加上-U参数才能保证每次使用最新版本。
2 确认服务的环境是符合预期的,配置是正确的
服务的环境包括操作系统版本,核心参数,JDK版本,环境变量,依赖的Jar包等。 检查配置我们不仅要确认配置本身没问题,还要确认下配置的优先级,配置的作用和生效范围。配置还包括依赖系统的配置,像Kylin这种依赖系统的话还需要考虑HBase,Hadoop,Hive,Spark等的配置。
例如:我去年在搞Kylin跨机房迁移时,就遇到Kylin Spark Cubing执行失败的情况,最后经过排查,确认是Kylin本身的bug,而触发这个Bug的因素就是环境和配置的变化。 具体可以参考 KYLIN-2995
3 分析变量
很多时候,我们正常的服务变得不正常,都是由变量引起的,一般是我们内部本身的变量导致了问题,或者是外部的变量触发了我们内部的Bug。
我们在分析问题时,首先应该确定内部和外部的变量(比如我们代码改了哪些地方,用户的查询模式有什么变化,出问题服务的环境和正常服务的环境有什么区别),然后再分析确认每个变量是不是导致我们此次问题的因素。很多时候,经过这一步,我们就可以找出问题的原因。
比如文中这个Case的变量就是用户的SQL数据类型,这个变量也是触发Calcite Bug的因素,所以我们其他查询集群都没有发生过这个问题,
4 保留现场
有些线上问题的发生有其偶然性和必需条件,线上服务有问题,我们必须马上恢复服务,一般不会立即分析问题,所以我们必须保留现场。 这些现场包括完善的监控指标:机器本身和服务本身的监控,Thead dump,Heap dump,Core Dump,关键的Log等。
比如文中的这个Case的分析处理就利用了监控指标和Thead dump。 我们利用监控指标和Thead dump分析出问题的原因是大量线程在LoadClass时Block,并根据线程堆栈可以判断出问题可能和Calcite有关。
5 梳理处理问题需要的背景和最少知识
工作中随意给个问题让我们进行处理时,我们必然需要明确这个问题相关的整个背景,问题中涉及的概念,涉及的系统原理。搞清原理可以帮助我们快速,正确的分析问题,不会盲目的走弯路。
比如文中的这个Case我们就应该明确Tomcat类加载到底是串行还是并行,是什么粒度的并行。
再举个例子。 在进行Kylin On Druid开发时,我发现Druid的Segment Load进Druid时会很慢。 这个时候我要去优化Druid Segment Load的速度,就必须首先搞清楚Druid的Coordinator怎么知道有新Segment生成了? Druid的Coordinator多久会处理一次Segment Load?Druid的Coordinator 如何和Historical 节点交互? Historical Load Segment 的逻辑? 官方的并发Load配置为何不生效(实际是串行Load)? 只有这些问题明确后,我才可以进行优化。
6 复现问题
在我们排除了代码因素,环境因素,配置因素,变量因素之后,问题相关的原理也明确了,我们可以首先尝试去复现问题,因为如果问题可以通过某种方式稳定复现的话,那么导致问题出现的因素基本就确定了,我们就可以开始通过各种手段分析问题了
7 Debug
当代码逻辑比较复杂,或者看代码怎么也看不出问题时,或者是系统依赖的第三方系统有问题时debug往往会比较有用。文中Case的原因明确主要靠的就是debug。一般分析Kylin查询问题时,debug十分有用,而且Kylin查询的问题一般debug都可以解决。
8 Log
当我们要进行一些耗时分析或者无法直接debug时(比如Hadoop集群上运行的MR Job),我们就可以直接加些log,帮助我们快速分析。
9 Thead dump 分析,Heap dump 分析,Core Dump 分析, CPU Profiling, 火焰图, Linux系统命令
上面每一点都值得一篇文章详细介绍,这里就不一一展开了,这些问题分析的手段和工具都需要我们在平时不断积累和实践。
10 直接根据异常本身进行代码分析
有时候,我们的系统会抛出一些和我们系统本身无关的异常,这个时候我们可以尝试下从异常本身出发,分析下异常产生的原因。
例如,前一阵我们有台Kylin的JobServer每隔24小时就会出现访问Hive MetaStore Kerberos认证失败的问题,但是其他JobServer都没有问题。我们负责Kerberos的同学追查了几次也没查到什么原因。
2018-03-11 06:00:07,494 INFO [Job b04a63f2-49e5-43c9-b971-f10a41e21e26-6211] hive.metastore:418 : Trying to connect to metastore with URI thrift://xxx.com:9000
2018-03-11 06:00:07,498 ERROR [Job b04a63f2-49e5-43c9-b971-f10a41e21e26-6211] transport.TSaslTransport:315 : SASL negotiation failure
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211)
at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)
at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:271)
at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:52)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:49)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1690)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport.open(TUGIAssumingTransport.java:49)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:462)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:256)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:181)
at org.apache.kylin.source.hive.CLIHiveClient.getMetaStoreClient(CLIHiveClient.java:136)
at org.apache.kylin.source.hive.CLIHiveClient.getHiveTableRows(CLIHiveClient.java:130)
前几天我就决定追一下,但是我一开始也没什么好思路,我就决定先看JDK8的源码,先明确下这个异常的直接原因是什么。通过看JDK8的源码,首先明确这个异常的直接原因是获取的Ticket是null:
KerberosTicket tgt = getTgt(caller, name, initLifetime);
if (tgt == null)
throw new GSSException(GSSException.NO_CRED, -1,
"Failed to find any Kerberos tgt");
......
return Krb5Util.getTicket(
realCaller,
clientPrincipal, null, acc);
}});
然后追踪代码又发现Krb5Util.getTicket会首先尝试从当前AccessControlContext的Subject中获取ticket,如果ticket是null且javax.security.auth.useSubjectCredsOnly是false,则会通过HadoopLoginModule重新登录的方式来获取Subject,简单理解,就是多了一次重试的机会。
static KerberosTicket getTicket(GSSCaller caller,
String clientPrincipal, String serverPrincipal,
AccessControlContext acc) throws LoginException {
// Try to get ticket from acc's Subject
Subject accSubj = Subject.getSubject(acc);
KerberosTicket ticket =
SubjectComber.find(accSubj, serverPrincipal, clientPrincipal,
KerberosTicket.class);
// Try to get ticket from Subject obtained from GSSUtil
if (ticket == null && !GSSUtil.useSubjectCredsOnly(caller)) {
Subject subject = GSSUtil.login(caller, GSSUtil.GSS_KRB5_MECH_OID);
ticket = SubjectComber.find(subject,
serverPrincipal, clientPrincipal, KerberosTicket.class);
}
return ticket;
}
所以最终通过设置javax.security.auth.useSubjectCredsOnly为false解决了这个问题。
11 逻辑分析
我们在复杂问题时一定要头脑清楚,逻辑清晰,有条理地分析和推断,综合利用综合法和分析法。因为一个问题再复杂,我们都可以不断拆解,层层推进,直到我们熟悉的已知问题;同时问题的许多现象和因素之间都有关联,我们在分析问题时,也要注意各种现象和因素的关联性。
总结
本文通过一次线上事故的分析过程,说明了Apache Kylin中 SQL数据类型的重要性,并简单总结了下我们如何排查和解决问题。
TalkCody 欢迎 Star&共建
欢迎关注微信公众号
